We implement a sustainable SRE approach in the company

It is difficult to manage microservices without adhering to the principles of SRE (site reliability engineering – ensuring the reliability of information systems). In this article, we will tell you how we set up the SRE process at Reputation.
In 2020, Reputation had more than 150 microservices that collected and processed millions of reviews from the Internet, extracting useful information from them for our customers. True, we had so much data and services that we could hardly manage to monitor the system manually and evaluate its reliability.
We’ve received complaints such as “You haven’t collected reviews for this establishment on TripAdvisor in the past three months”, “You’re late in responding to reviews for this branch” or “I have fewer reviews on Google, where did the review requests go?”
We collected millions of reviews and sent millions of feedback requests from our platform, so we needed a reliable system to monitor at the level of individual customers or even customer branches (by branch we mean, for example, a San Francisco store) so that we could notice when something goes wrong. More importantly, based on this data, we could invest in improving the reliability of our services or adding new features.
Define the problem
Before we at Reputation started to fully implement the principles of SRE, we had two teams: an engineering team that dealt with product features, maintenance and bug fixes, and an operations team that was responsible for order in production. She monitored the health of the infrastructure, services, databases, and so on. So the uptime of the services was very good (usually 99.99%). Therefore, we were very surprised when customers complained about the violation of the SLA for one of their branches.
For example, a job scheduled for a client started 15 minutes late or took too long to complete. Reviews were collected in different volumes and not completely. E-mail notifications didn’t arrive on time, etc. All of this pointed to problems with the application and business logic, rather than with the infrastructure.
We have decided to implement a sustainable SRE process to achieve the following goals:
Define SLO (service level objective, target service levels) and SLI (service level indicator, service level indicators).
Automate SLI tracking.
Create dashboards for SLO.
Improve service reliability based on SLO metrics.
Team and process preparation
To begin with, we assembled an independent team of five SRE engineers. They had to work with the owner of each service to define the SLO, SLI, and monitoring requirements for that service. Working with service teams, SREs explored the functionality of each product to help service and product owners define SLOs.
SLO indicates the target reliability level of the service.
The last word in determining the SLO was left to the owner of the service. With the SLO defined, the SREs and service owners set to work on the SLI.
SLI is a service level indicator.
SLO is a target value or range of values for a service level that is measured using SLI. We comply with SLO if:
SLI <= target
or
lower bound <= target <= upper boundFor example, we measure the reliability of the service by the time it takes to complete tasks, and we want all tasks to complete between 15 and 30 minutes.
Having defined SLO and SLI, we must set a target reliability value for SLO. Do we want 100% of jobs to be completed in 15-30 minutes? Reaching 100% SLO will be difficult at first because the team doesn’t have enough data. In addition, high expectations will lead to unnecessary stress for employees if the desired performance cannot be achieved. Ideally, you should set a value that is not too high and adjust it periodically.
For example, in our example, we could set the following target values for SLO:
95% of jobs should complete within 30 minutes
Job Latency <= 30 minutes
90% of jobs should be complete between 15 to 30 minutes
15 minutes <= Job Latency <= 30 minutesHaving determined SLO, SLI and target values, we must decide how often we will measure them. For example, SLO can be measured monthly or over a rolling period (for example, the last 28 days). Subsequently, we will compare SLOs for these periods. We, for example, calculate the SLO for a fixed month so that we can track trends from month to month.
Implementation
Having defined the SLO, SLI, reliability targets, and measurement period, we need to find ways to measure SLI. After collecting the SLI, the SLO can be calculated from them. Then the SLOs need to be combined for the specified period (for example, a month).
Let’s look at an example of how SREs helped a service owner define an SLO.
Rep Connect is a service that manages tasks. Clients schedule jobs in RepConnect at specified times of the day and expect RepConnect to run those jobs and complete them at the specified times. SRE engineers worked with RepConnect owner to define SLO and SLI.
SLO: job execution time
90% of tasks must be completed in 15 minutes
95% of tasks must be completed in 30 minutes
SLO: job delay
90% of jobs must start within 15 minutes of the scheduled time
95% of jobs must start within 30 minutes of the scheduled time
Time period: one month
How to measure
We at Reputation replicate runtime data from MongoDB to BigQuery every 15 minutes (as described here). The SRE team decided to use BigQuery to track the SLI and calculate the SLO. They wrote a stored procedure in BigQuery and scheduled it to run once a day. We were going to calculate the SLO for a month, so we calculated the indicators not in real time, but once a day. The stored procedure had to process all records of jobs and calculate the time spent on their execution. This value was compared with the SLO ranges and the results were saved to a new table. Similarly, the difference between the scheduled and actual start time of the job was calculated to calculate the latency. The delays were then divided into two ranges as described above.
So, every day we measured SLI and calculated SLO by ranges.
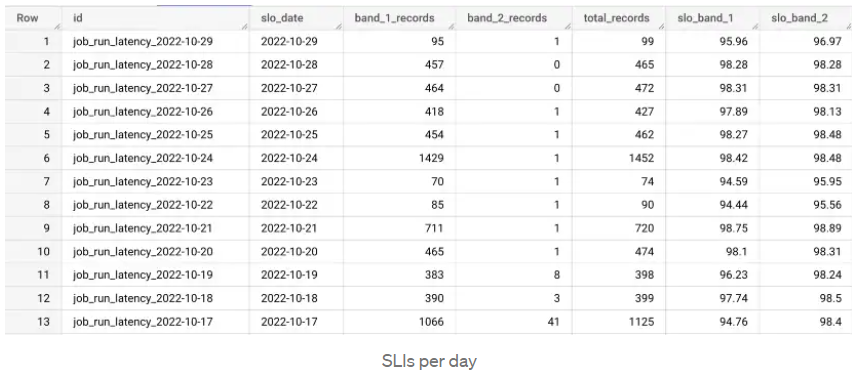
The table shows an example of calculating the time to complete tasks by day. The total_records column shows the total number of jobs per day, band_1_records shows jobs that took less than 15 minutes, and band_2_records shows jobs that took between 15 and 30 minutes. In the slo_band_1 column, we see the percentage of reaching the target value for the first SLI, and in slo_band_2 – for the second.
We collect data for individual days and calculate the SLO for the month.

This is a PivotTable with columns showing months and rows showing SLOs. The red cell shows that the SLO was violated for that range this month. Looking at this SLO dashboard, we can formulate Error budget (bug budgets).
Error budget is a culture in which the team stops releasing new features (except those aimed at improving reliability) until the service meets the SLO).
When red values constantly appear on the SLO dashboard, then something is going wrong, and the engineering team needs to work on the quality and reliability of the product.

Start of the practical course SRE: data-driven approach to systems reliability management 28th of February.