How are the files arranged? Parsing
Files… what could possibly be easier? We are all used to creating, deleting, editing, sharing files.
But can we look inside each file and understand how it works? Of course we can, so today we will dig a little into the binary code and feel the metadata.
At the same time, we will find out why the iPhone hangs on SMS and gut PowerPoint.
Why are there so many file formats?
If we could just look at the raw data that is stored inside a hard drive or SSD, then we would not see any files: we would see only zeros and ones. Because, in any case, everything is stored in the computer’s memory as a continuous stream of binary code.
But how then to understand where one file ends and another begins?
At first, humanity solved this problem brutally. People wrote one file to one hard drive, so as not to make a mistake. Therefore, earlier the word file was not called a separate area on the hard disk, but the whole device. For example IBM 305.

CTSS (Compatible Time Sharing System)
But then, people came up with file systems. If we simplify it very much, this is a table of contents in which the name of the file is indicated, where it begins and its length. As well as all sorts of metadata, such as creation time, changes, and whether it can be overwritten.

But in order to read the file, knowing its location and boundaries on the hard drive is not enough, because we need to somehow decrypt the binary code.
There are various file formats for this. On most operating systems, file formats are specified as an extension separated by a dot from the file name. And if you don’t see the extension, that’s fine. Because, by default, modern operating systems hide them, but you can check the box in the settings.
The extension gives a hint to the operating system and programs about what type of data it contains and how it is all structured. For example, upon seeing the file droider.jpg, the operating system and we humans immediately understand that this is a picture in JPEG format.
Naturally, for data types and different tasks, a different file structure will be optimal. Therefore, there are a huge number of file formats.
Therefore, let’s take a look at how the most popular file formats are arranged from simpler to more complex.
TXT
One of the simplest formats is TXT. This is a text format. The famous Notepad application in Windows works with this format.
TXT is a simple format. It can store only simple unformatted text, that is, it does not contain any selections, underlining, italics, indents, different fonts. Only bare text, or rather just symbols.
Each character in TXT format is stored as a binary code.
Hello world!
What we see as meaningful text, the operating system sees like this:
01001000 01100101 01101100 01101100 01101111 00101100 00100000 01110111 01101111 01110010 01101100 01100100 00100001
Every 8 digits, that is, 8 bits of this code, is a separate character.
For example, 01001000 is “H”, 01100101 is “e”, and so on.
01001000-H
01100101-e
01101100-l
01101100-l
01101111-o
But how does the operating system decrypt this data? Everything is simple. The operating system needs to load a table that describes the correspondence of the binary code to a specific character. There are many such tables, the most famous today are CP1251 (Windows), UTF-8 (Android, Mac) and so on. Such tables are often called encodings. This file uses UTF-8 encoding, that is, 8-bit Unicode.
Unicode Transformation Format, 8-bit – “Unicode transformation format, 8-bit”
Having picked up the correct encoding, it remains a matter of technology. The system compares the binary code with the UTF-8 encoding table and you’re done! But what happens if the system selects the encoding incorrectly? There are not many options, most likely we will see kryakozyabry:
çÁ%%?Œ€Ï?Ê%À (EBCDIC encoding).
And this often happens, since the TXT file does not contain any additional information about the encoding. And this is a big drawback of the format.
Another interesting point. Historically, computers “knew” only the Latin alphabet, which is used in most European languages. And then there was a problem: 8-bit is just 256 possible values. It’s not much, but it was enough to encode all basic characters + latin letters.
In addition, this table had to be loaded into RAM when the computer booted up, and a typical PC in the early 80s rarely had more than 640 kilobytes of RAM. And it was simply impossible to use 16-bit tables (65536 variants), such a table simply would not fit into memory.
But the power of computers grew and the problem went away. Cyrillic characters were added to the tables with Latin characters, which no longer occupied 8 bits, but 16 bits each. Therefore, the text in Russian takes up twice as much memory, with the same number of characters.
11010000 10011111 11010001 10000000 11010000 10111000 11010000 10110010 11010000 10110101 11010000 10110101 11010001 10000010 00101100 00100000 11010000 10111100 11010000 10111100 11010001 10111000 11010001 10000000 00100001
11010000 10011111 – P
11010001 10000000 – p
10111000 11010000 – and
11010000 10110010 – in
…
Hello World!
Old people remember the life hack, if you write SMS in Latin, it will fit twice as much text. All this is just because of the encoding.
By the way, remember all these cases when the iPhone died from a sent message with strange symbols or pictures? This is precisely due to the fact that the system could not correctly recognize the sent characters and correctly determine their length.
For example, such a message at one time forced any iPhone to go into a cyclic reboot:
power
لُلُصّبُلُلصّبُررً ॣ ॣh ॣ ॣ
冗
WAV
So, so that the operating system does not have problems understanding how to read the file. In addition to the data itself, data about data began to be added to various formats. That is, metadata that is stored directly inside the file and contains additional information on how to read this file.
For example, let’s take WAV file.
This is a simple audio format that contains uncompressed. All CDs are recorded in WAV format.

The first 44 bytes of a classic WAV file contain a header that contains useful information:
- number of audio channels;
- sampling frequency;
- bit depth;
- and much more.
All this data allows you to be sure that the audio will be played correctly.
Open and proprietary formats
The structure of WAV is well known and probably almost any player will be able to read such a file. This is because a WAV file is an example of an open format.
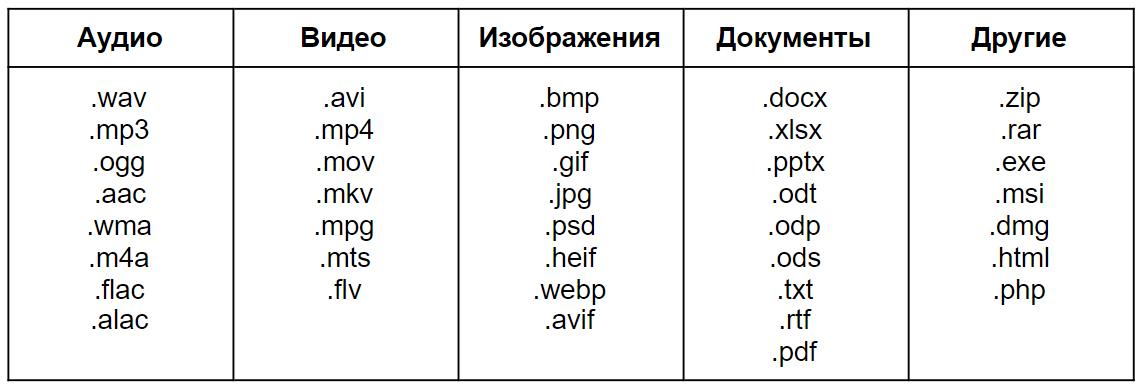
There are other open formats that you use daily. For example:
- web page markup language – HTML;
- pictures – PNG;
- audio format – OGG;
- archive – ZIP;
- video – MKV;
- e-book – EPUB;
- and others…
But there are also closed file formats, or rather proprietary ones. Opening and editing such files with third-party software is often either prohibited altogether or distributed under licenses.
Proprietary formats are great for everyone, but in some cases they prevent competition in the software industry, as they lead to vendor lock-in. There is even such a term Vendor lock-in.
old office
For example, earlier this situation was with Microsoft Office formats: DOC, XLS, PPT.
Not only were these proprietary formats from Microsoft and they only worked with proprietary software. Also Microsoft constantly changed their file structure from one version of MS Office to another. And as a result? when a new version of the office suite is released? files from the old editor were no longer readable by the new one, but on the contrary, even more so.
The European Union did not like this situation very much. Therefore, the EU has risen up on the topic of restricting competition. As a result, the file formats were published, and everyone learned to at least read them, but writing to the old formats still requires a Microsoft license. And in parallel to this, open formats began to be developed.
ODF and OOXML
On May 1, 2006, the ODF format was born, which literally stands for an open document format for office applications. It was developed by a consortium of OASIS and Sun Microsystems.
- ODF – Open Document Format for Office Application.
- OASIS – Organization for the Advancement of Structured Information Standards.
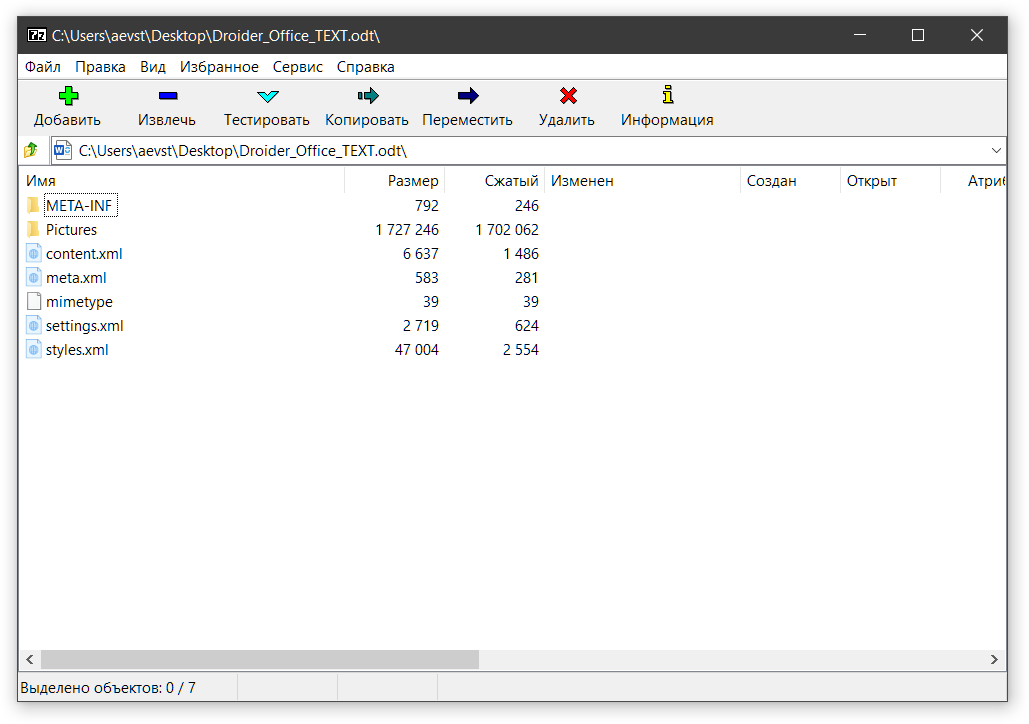
The format is based on the Universal Markup Language XML. And the ODF file itself is a ZIP archive with folders, XML files and all sorts of attachments in the form of pictures, videos and more. In other words, if we open such a file through an archiver, we can easily see all the insides. Here is an example of openness!
Microsoft didn’t sleep either. Under pressure from the European Court, they teamed up with a number of companies to form the ECMA association and developed their own open format, Office Open XML, which was born a little later in 2006.
OOXML is standardized by the European Computer Manufacturers Association. Standard ECMA-376
The letter X was added to the usual format at the end and we got: DOCX, XLSX, PPTX.
OOXML – Office Open XML (DOCX, XLSX, PPTX)
OOXML is, in general, very similar to ODF. It is also based on XML markup and is also a ZIP archive. Therefore, you can also look inside office files using any archiver. You can even pull out the pictures and even replace them, which is especially convenient when working with presentations or when you are sent a text document with pictures inside a file.

Despite the apparent simplicity, the format is really complex. Only the main documentation is 5 thousand pages. And it’s almost without pictures.
Nevertheless, someone still managed to read all this documentation and therefore cool office suites were born, for example My officewhich can work with ODF format, and with Office Open XML, and even with outdated formats such as DOC.
But there is an important remark about the old formats. As a rule, modern software can only read them, but not write them, because this action requires the purchase of a Microsoft license. However, in our time, this action, to put it mildly, is meaningless.
Total

What did we end up learning? Files are of several types:
The most basic ones are binary. Companies like to come up with such formats so that no one understands how their programs store data.
A more open option is xml containers. Fortunately, most of the popular office formats are now like this. If you want to work with all these files, even at home, even on the run, download MyOffice programs! That’s all we have today.





