How we made life easier for highly loaded services with Platform V SessionsData. Part 3
Platform V DataGrid instead of DBMS
I’ll start by abandoning the database and persistent storage in general. But first, I’ll tell you why we decided to abandon the database altogether.
Firstly, we only store records of active sessions for our admin panel in it, the data itself is not there. So, they are not critical for our service. If you abandon the database, we just won’t see active sessions in the admin panel. That is why we have previously replaced synchronous database calls with asynchronous ones, which I wrote about in the second part.
Secondly, sessions do not last long: an average of 5 minutes. Therefore, persistence when storing such data is not needed.
Thirdly, the records in the database are compact and fit in the server’s memory.
Therefore, we plan to replace the base with Platform V Data Grid is a distributed data storage solution based on Apache Ignite and upgraded to an enterprise level in terms of security and fault tolerance.
Instead of a dedicated Ignite cluster, we will create our own. Using a few jar files from the Platform V DataGrid, we will make a service service – servant – each node of which will become an Ignite node. Such nodes themselves form an Ignite cluster in Kubernetes. For now, we plan to use the standard “ring” topology and the REPLICATED cache mode so that each node of the cluster has a complete copy of the data.

The master will contact the servant via the exposed REST API through the Ingress Gateway with Round robin balancing. This is necessary for flexibility: the masters will not have a connection to the database, and the servant, with some settings, can be Ignite, and with others, use the database as before.
By getting rid of the DBMS, we will finally protect ourselves from its failures, architectural redundancy, and besides, we will be able to save money. And then I’ll tell you about the refinement, which will help further enhance the security of our service for consumers.
Data Access Authorization
Large companies work with a large number of microservices. And each of them needs to protect their contracts when working with data in Platform V SessionsData: other services that know the name of the data section can read it or change it. Let’s take an abstract example: the microservices “Tickets” and “Routes” can have common data sections, and they would not want someone else to have access to this data.
To protect data access, we will take a unified authorization service based on the Open Policy Agent and which is part of the product Platform V IAM, where it has been upgraded to the enterprise level in terms of security and fault tolerance. At the same time, the subjects of access rights will not be end users, but microservices working “under the hood” for it. How it will work: when deployed, each microservice imports access policies to its sections into the authorization service.
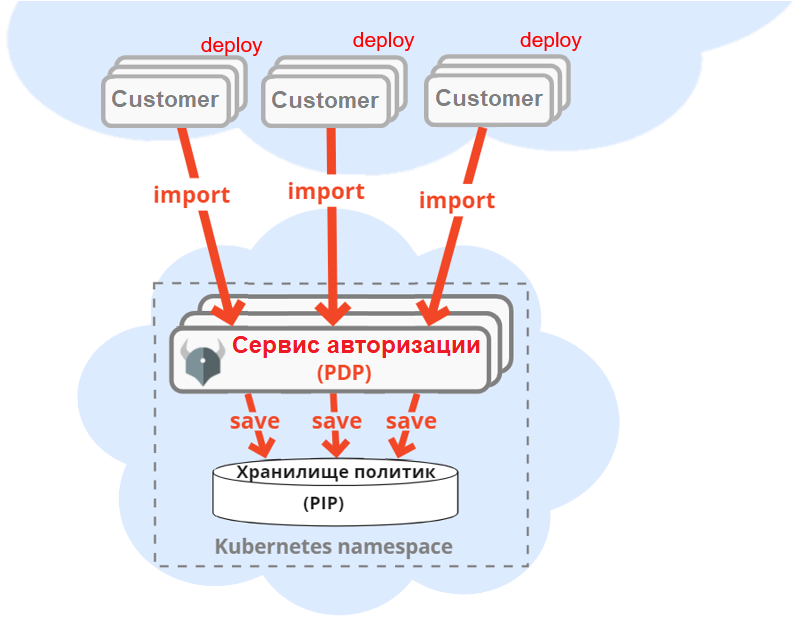
When accessing sections, our master service goes to the REST API authorization service and receives a response whether the access is allowed or not. The authorization service checks access against all policies imported into it.

Policies specifically for this authorization tool are written in the Rego declarative language. But Platform V uses a generic policy written in Rego that simply interprets JSON ACL Policy files with policies. They look something like this:

Here at the microservice tickets (tickets) have the right to read and write the section pricesPerKilometer (prices per kilometer).
What will happen with the delay time of the master service if it calls the authorization service for each client request? The master will cache the authorization service responses. They are static and can only change when services are redeployed. The combinatorial number of possible answers is also small, and will easily fit in the master’s memory.

The ideal option is to never invalidate this cache at all. It is better to periodically update it with asynchronous calls to the authorization service. So the duration of the delay of our masters will practically not increase after the cache is warmed up. And as a result, thanks to authorization, our service will become even safer for consumers.
“Non-client” sessions
One of our goals is to facilitate the work of loaded persistent storages. To do this, we came up with special sessions that are not tied to specific end users. When creating such a session, any microservice can set any data lifetime. Such long-lived sessions can be called “non-client”, “service” or “technical” – all this is about them.
Let me give you an interesting example. Suppose, when creating client sessions, rarely changed reference books are loaded into them. This allows you to access persistent storage only once in each session. But the solution can be optimized if all directories from storages are loaded into one “non-client” session and periodically updated by an asynchronous worker. Then, when creating each client session, it will be enough to simply transfer the necessary directories from the “non-client”, that is, from RAM to RAM, without accessing the disk.

For example, if client sessions are created very often in a service, then 100,500 calls to persistent directory storage are performed every minute. And with the use of a “non-client” session, this is only one call per minute from an asynchronous updater worker. Loaded persistent storages will say “thank you” for this.
Automatic injection of sidecar into consumer service
And finally, I’ll tell you about our plans for the implementation of the slave sidecar by the Kubernetes operator. As I wrote in second part in the “Storage not in a container” section, we now have the slave sidecar in a container inside consumer pods, which can be very numerous. They connect our sidecar to the pods according to the instructions:
• insert a description of the slave sidecar container into the Deployment:

• insert a description of the volumes for our sidecar into the Deployment:

• add to your distribution a configuration file with sidecar launch options (turns into a ConfigMap when deployed):

• add to your distribution ConfigMap with sidecar runtime behavior parameters:

Doing this manually is routine, and mistakes can be made. Especially considering that the copied YAML pieces can change when the version of the slave sidecar changes.
At the same time, we want to give the optional ability for low-load consumers to work without our caching slave sidecar. In this case, our client jar in the consumer application will immediately access the master store.
Therefore, we plan to make a Kubernetes operator that will inject our sidecar into the Deployment of consumers. This will make their work easier and will allow you to conveniently connect and disconnect our sidecar. The user will only need to add annotations to the Deployment for our operator. Enable the sidecar flag and set its parameters:

Or just turn off sidecar. In this case, the consumer will change the localhost URL for communicating with the slave to the master URL in its settings:

The operator will monitor the appearance of each new Deployment in the namespace of the consumer and implement the slave sidecar there, if indicated in the annotations.

This solution will allow consumers to easily connect and disconnect our sidecar without doing routine work.
Summing up
In this and previous articles, I talked about how we develop our own Platform V SessionsData product, which helps Sber microservices store customer session data. At the same time, Platform V SessionsData will perfectly cope with similar tasks in applications outside of Sberbank.
I hope my story was helpful to you. Thank you for your attention and see you soon!





