We write a search for semantically similar texts (or products) in half an hour in Go and Postgres (pgVector)
It would seem that postgres already has a good full-text search (tsvector/tsquery), and you can index your texts out of the box and then search them. But in fact, this is not quite what is needed – such a search only works based on clear matches of words. Those. postgres won't guess that “a cat is chasing a mouse” – it's pretty close to “a kitten is chasing a rodent”. How to overcome such a problem?
TLDR:
- We convert our texts into sets of numbers (vectors) using the openAI API.
- We save vectors in the database using pgvector.
- We easily search for vectors close to each other or search for them using a query vector.
- We speed it up with indexes.
Making a vector from text
So, let's look at converting text into a vector (this is called embedding). It is not necessary to delve deep into theory; in practice, everything is done very simply – you can simply use the OpenAI API. Currently it costs between 2 and 13 cents per million tokens. Almost for nothing.
At the input we take a set of words (one word or many at once), and at the output we get a vector.
What kind of vector is this anyway? It's just a set of numbers, essentially coordinates in a 1500-dimensional space. Moreover, the transformation from text to embedding occurs on a pre-trained model so that texts that are similar in meaning have a similar vector direction.
It turns out that we are working, as it were, with a space of meanings and trying to figure out where our text is in this space. After this, you can simply look at which texts are closer to which, purely geometrically.
A little practice:
You can get embeddings by simply sending a request to the OpenAI API (the token can be obtained on their website for 10 bucks)
curl https://api.openai.com/v1/embeddings \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"input": "Your text string goes here",
"model": "text-embedding-3-large"
}'But in general, of course, there are wrapper libraries, for example, github.com/sashabaranov/go-openai
strings := []string{"котик гонится за мышкой", "кошка ловит грызуна"}
client := openai.NewClient("your-token")
ctx := context.Background()
response, err := client.CreateEmbeddings(ctx, openai.EmbeddingRequestStrings{
Input: strings,
Model: "text-embedding-3-large",
Dimensions: 2000,
})Default model text-embedding-3-large produces a vector with dimension 3072, and text-embeddng-3-small — 1536. But in the request you can specify if you want less (dimensions parameter)
Let's shove this into postgres
A few months ago, Karuna sent me to a database conference where they talked about pgvector.
In general, in postgres there is extensionwhich provides the data type vectorand a number of operations: addition, subtraction, multiplication (elementwise), cosine distance, Euclidean distance, scalar product. As well as the functions sum(), avg(), and two types of indexes.
See their page for methods of installing the extension, and to get a feel for it, you can simply use a docker image pgvector/pgvector:pg16 is postrges 16 with pgvector.
The extension must be activated before use.
CREATE EXTENSION IF NOT EXISTS vectorLet's create a table to store texts and their embeddings
CREATE TABLE embeddings (
id SERIAL PRIMARY KEY,
text TEXT UNIQUE,
embedding vector(2000) NOT NULL
);and write embeddings there for descriptions of such products:
"котик гонится за мышкой"
"котик гонится за мышками"
"собака лает, караван идёт"
"однажды в студёную зимнюю пору"
"кошка охотится на грызуна"
"котёнок ловит крысу"
"на марсе не растут грибы"
"умирает конь"So, I wrote a Go program on my knee that receives embeddings for phrases and writes them to the database. By the way, there is a library https://github.com/pgvector/pgvector-gowhich simplifies interaction with the vector type, but in such a simple example you can do without it:
package main
import (
"context"
"log"
"github.com/jackc/pgx/v4/pgxpool"
"github.com/sashabaranov/go-openai"
)
func main() {
strings := []string{
"котик гонится за мышкой",
"кошка охотится на грызуна",
"котёнок ловит крысу",
"котик гонится за мышками",
"собака лает, караван идёт",
"однажды в студёную зимнюю пору",
"на марсе не растут грибы",
"умирает конь",
}
ctx := context.Background()
embeddings := getEmbeddingsFromStrings(ctx, strings)
db := initDb(ctx)
if _, err := db.Exec(ctx, "CREATE EXTENSION IF NOT EXISTS vector"); err != nil {
log.Fatalf("couldn't create extension: %v", err)
}
if _, err := db.Exec(ctx, `
CREATE TABLE IF NOT EXISTS embeddings (
id SERIAL PRIMARY KEY,
text TEXT UNIQUE,
embedding vector(2000) NOT NULL
)`); err != nil {
log.Fatalf("couldn't create table: %v", err)
}
for str, embedding := range embeddings {
_, err := db.Exec(ctx,
`INSERT INTO embeddings
(text, embedding) VALUES
($1, $2::float4[]::vector)`, str, embedding)
if err != nil {
log.Fatalf("couldn't insert: %v", err)
}
}
}
func getEmbeddingsFromStrings(ctx context.Context, strings []string) map[string][]float32 {
client := openai.NewClient("your-token")
response, err := client.CreateEmbeddings(ctx, openai.EmbeddingRequestStrings{
Input: strings,
Model: "text-embedding-3-large",
Dimensions: 2000,
})
if err != nil {
log.Fatalf("error: %v", err)
}
result := make(map[string][]float32)
for _, data := range response.Data {
embedding := data.Embedding
result[strings[data.Index]] = embedding
}
return result
}
func initDb(ctx context.Context) *pgxpool.Pool {
db, err := pgxpool.Connect(ctx, "postgres://pgvector_test:pgvector_test@localhost:5432/pgvector_test?sslmode=disable")
if err != nil {
log.Fatalf("couldn't connect to database: %v", err)
}
return db
}
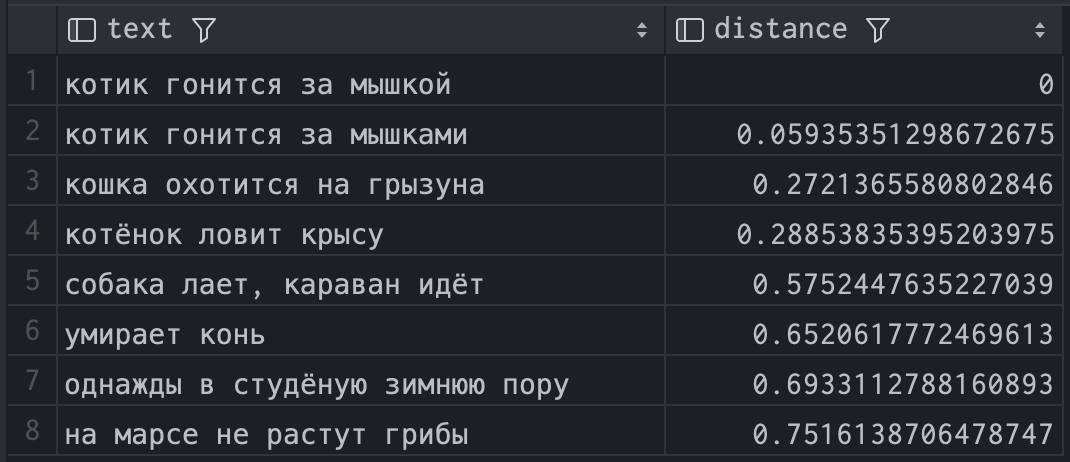
Then let’s take the vector for the phrase “the cat is chasing the mouse” and look for which vectors are closest in terms of cosine distance <=>:
select
text,
embedding <=> (
select embedding
from embeddings
where text="котик гонится за мышкой"
) distance
from embeddings
order by distance;and we get this result:
It can be seen that the distance to itself is zero, and then postgres found phrases that were quite close in meaning. The result, by the way, strongly depends on the dimension of the vectors. At 1500, “the horse dies” rises quite high on the list. I don’t know, maybe a horse is also a rodent in some sense, and it dies no worse than a mouse in the teeth of a cat. But at 2000 everything looks a little more logical.
One way or another, in any case, the results are much more interesting than the built-in full-text postgres search could find on this data.
In the example, I'm looking for how similar one existing text is to another, but you can also do a search for an arbitrary phrase: just take the text of the search string, convert it into a vector and put it in the query.
Speeding up using indexes
There are 2 indexes in the extension:
HNSW – indexes slowly, uses more memory, but queries are faster. Creates a multilayer graph.
-- пример индекса для ускорения расчёта косинусного расстояния
CREATE INDEX ON items USING hnsw (embedding vector_cosine_ops);IVFFlat works on a different principle, it divides vectors into lists and then searches for a subset of these lists that is closest to the query vector.
CREATE INDEX ON items USING ivfflat (embedding vector_cosine_ops) WITH (lists = 100);The IVFFlate index can only be built after the table is filled with data.
Nuances and conclusion
Since in the postgres there are simply vectors of a certain dimension, it seems to me that no one will bother adding a couple more dimensions to them. For example, if we are looking for similar products in an online store, then we can probably try adding numbers such as “length”, “width”, “color”, etc. to the vectors.
It is clear that dependence on the API of another service is bad, so you can try to make your own system for receiving embeddings. I googled a couple of ways to do this in Go, but I didn’t dig deep into this.
When using indexes, the result may differ slightly from a query without indexes. This is a compromise for speed.
subscribe to my channel Cross Joinif you are interested in such content.