“WALKING IN MY SHOES” – STOP, AND THEY LABELED?
In X5, a system that will track products with labels and share data with the government and suppliers is called “Marcus”. We will tell in order how and who developed it, what its technology stack is, and why we have something to be proud of.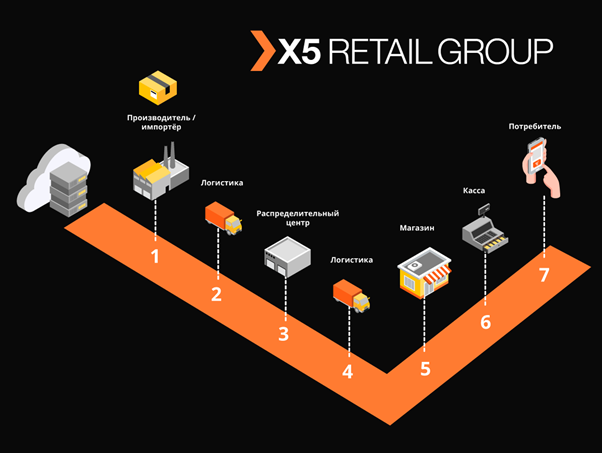
Real HighLoad
“Marcus” solves many problems, the main one being the integration interaction between X5 information systems and the state information system of marked products (GIS MP) to track the movement of marked products. The platform also stores all the marking codes that have arrived to us and the entire history of the movement of these codes by objects, and helps to eliminate re-sorting of marked products. On the example of tobacco products, which was included in the first groups of labeled goods, only one cigarette wagon contains about 600,000 packs, each of which has its own unique code. And the task of our system is to track and verify the legality of the movements of each such pack between warehouses and stores, and ultimately check the feasibility of their implementation to the end customer. And we record cash operations about 125,000 per hour, and we also need to fix how each such bundle got into the store. Thus, taking into account all the movements between objects, we expect tens of billions of records per year.
Team M
Despite the fact that Marcus is considered a project within the framework of X5, it is being implemented according to the product approach. The team works on Scrum. The start of the project was last summer, but the first results came only in October – our own team was fully assembled, the system architecture was developed and the equipment was purchased. Now the team has 16 people, six of whom are involved in the development of the backend and frontend, three of them are system analysis. Manual, stressful, automated testing, and product support are involved in six more people. In addition, we have an SRE specialist.
The code in our team is written not only by developers, almost all the guys are able to program and write autotests, load scripts and automation scripts. We pay special attention to this, since even product support requires a high level of automation. Colleagues who did not program before, always try to prompt and help, to give some small tasks to work.
In connection with the pandemic of coronavirus infection, we transferred the entire team to remote work, the availability of all development management tools built by workflow in Jira and GitLab made it easy to go through this stage. The months spent on the remote site showed that the team’s performance was not affected, for many the comfort in work increased, the only thing is that there is not enough live communication.
MEETING THE TEAM BEFORE DELETING:

MEETINGS DURING THE REDUCTION:
Technological Solution Stack
The standard repository and CI / CD tool for X5 is GitLab. We use it for code storage, continuous testing, and deployment on test and production servers. We also use the practice of code review, when at least 2 colleagues need to approve the changes made by the developer to the code. SonarQube and JaCoCo static code analyzers help us keep the code clean and provide the required level of coverage with unit tests. All changes to the code must go through these checks. All test scripts that are run manually are subsequently automated.
For the successful implementation of business processes by Marcus, we had to solve a number of technological problems, each in order.
Task 1. The need for horizontal scalability of the system
To solve this problem, we chose a microservice approach to architecture. It was very important to understand the areas of responsibility of services. We tried to separate them according to business operations, taking into account the specifics of the processes. For example, acceptance at the warehouse is not a very frequent, but very voluminous operation, during which it is necessary to quickly obtain information from the state regulator on the accepted units of goods, the amount of which in one delivery reaches 600,000, check the admissibility of acceptance of this goods to the warehouse and give all necessary information to the warehouse automation system. But shipment from warehouses has much greater intensity, but at the same time operates with small amounts of data.
We implement all services according to the stateless principle, and even try to separate internal operations into steps using, as we call them, Kafka self-topics. This is when the microservice sends a message to itself, which allows you to balance the load on more demanding operations and simplifies product maintenance, but more on that later.
We decided to separate the modules of interaction with external systems into separate services. This allowed us to solve the problem of frequently changing APIs of external systems, with virtually no impact on services with business functionality.
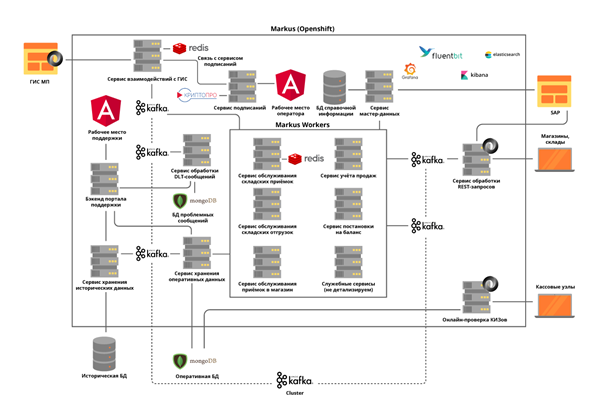
All microservices are deployed in an OpenShift cluster, which solves both the scaling problem of each microservice and allows us not to use third-party Service Discovery tools.
Task 2. The need to maintain a high load and a very intensive exchange of data between platform services: in the launch phase of the project alone, about 600 operations per second are performed. We expect this value to increase to 5,000 op / s as trading objects connect to our platform.
This problem was solved by the deployment of the Kafka cluster and the almost complete rejection of synchronous interaction between platform microservices. This requires a very careful analysis of system requirements, since not all operations can be asynchronous. At the same time, we not only transmit events through a broker, but also transmit all the required business information in a message. Thus, the message size can reach several hundred kilobytes. The limit on the volume of messages in Kafka requires us to accurately predict the size of messages, and, if necessary, we divide them, but the division is logical, related to business operations. For example, goods that arrived in a car, we divide by boxes. Separate microservices are allocated for synchronous operations and rigorous load testing is carried out. Using Kafka posed another challenge for us – checking the operation of our service taking into account the integration of Kafka makes all our unit tests asynchronous. We solved this problem by writing our own utility methods using Embedded Kafka Broker. This does not eliminate the need to write unit tests for individual methods, but we prefer to test complex cases using Kafka.
We paid a lot of attention to log tracing so that their TraceId would not be lost when exceptions occurred during the operation of services or when working with Kafka batch. And if there were no special questions with the first one, then in the second case we are forced to log all the TraceId with which batch came and select one to continue the trace. Then, when searching for the original TraceId, the user can easily find out how the tracing continued.
Task 3. The need to store a large amount of data: more than 1 billion markings per year comes from tobacco alone to X5. They require constant and quick access. In total, the system must process about 10 billion records for the history of movement of the data of marked goods.
To solve the third problem, NoSQL MongoDB database was chosen. We have built a shard of 5 nodes and in each node of the Replica Set of 3 servers. This allows you to scale the system horizontally, adding new servers to the cluster, and ensure its fault tolerance. Here we faced another problem – ensuring transactionality in the mongo cluster, taking into account the use of horizontally scalable microservices. For example, one of the tasks of our system is to identify attempts to resell goods with the same labeling codes. Here overlays with erroneous scans or with erroneous operations of cashiers appear. We found that such duplicates can occur both inside one processed batch Kafka, and inside two parallel processed batch. Thus, checking for the occurrence of duplicates by querying the database yielded nothing. For each of the microservices, we solved the problem separately based on the business logic of this service. For example, for checks, a check was added inside the batch and separate processing for the appearance of duplicates upon insertion.
So that the work of users with the history of operations does not affect the most important thing – the functioning of our business processes, we have allocated all historical data to a separate service with a separate database, which also receives information through Kafka. Thus, users work with an isolated service, without affecting the services that process data on current operations.
Task 4. Queue reprocessing and monitoring:
In distributed systems, inevitably there are problems and errors in the availability of databases, queues, and external data sources. In the case of Marcus, the source of such errors is integration with external systems. It was necessary to find a solution that allows repeated requests for erroneous answers with some specified timeout, but at the same time not to stop processing successful requests in the main queue. For this, the so-called “topic based retry” concept was chosen. For each main topic, one or several retry topics are created, into which erroneous messages are sent, and at the same time, the delay in processing messages from the main topic is eliminated. Interaction Scheme –
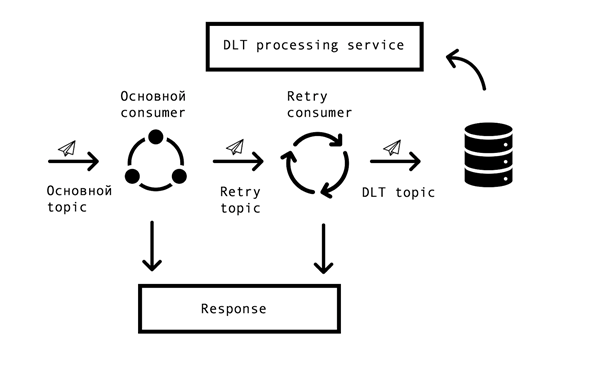
To implement such a scheme, we needed the following – to integrate this solution with Spring and avoid code duplication. On the open spaces of the network, we came across a similar solution based on Spring BeanPostProccessor, but it seemed to us unnecessarily cumbersome. Our team made a simpler solution that allows you to integrate into Spring’s consumer creation cycle and add Retry Consumers. We proposed the prototype of our solution to the Spring team, you can see it here. The number of Retry Consumers and the number of attempts of each consumer is configured through the parameters, depending on the needs of the business process, and for it to work, all that remains is to put the annotation org.springframework.kafka.annotation.KafkaListener familiar to all Spring developers.
If the message could not be processed after all retry attempts, it falls into the DLT (dead letter topic) using the Spring DeadLetterPublishingRecoverer. At the request of support, we expanded this functionality and made a separate service that allows you to view messages that got into DLT, stackTrace, traceId and other useful information on them. In addition, monitoring and alerts were added to all DLT topics, and now, in fact, the appearance of a message in a DLT topic is an occasion for analysis and establishment of a defect. This is very convenient – by the name of the topic we immediately understand at what step in the process the problem arose, which greatly speeds up the search for its root cause.

More recently, we have implemented an interface that allows us to resend messages by our support forces, after eliminating their causes (for example, restoring the working capacity of an external system) and, of course, instituting an appropriate defect for analysis. Here our self-topics came in handy so as not to restart a long processing chain, you can restart it from the desired step.

Platform operation
The platform is already in productive operation, every day we carry out deliveries and shipments, connect new distribution centers and shops. As part of the pilot, the system works with the “Tobacco” and “Shoes” product groups.
Our entire team participates in piloting, analyzes the problems that arise and makes suggestions for improving our product from improving logs to changing processes.
In order not to repeat their mistakes, all cases found during the pilot are reflected in automated tests. The presence of a large number of autotests and unit tests allows you to conduct regression testing and set a hotfix in literally several hours.
Now we continue to develop and improve our platform, and constantly face new challenges. If you are interested, we will talk about our solutions in the following articles.