Setting up the Amazon SageMake environment on a local machine

Amazon SageMaker provides more than just the ability to manage notebooks in Jupyter, but a configurable service that lets you create, train, optimize, and deploy machine learning models. A common misconception, especially when getting started with SageMaker, is that you need SageMaker Notebook Instance or SageMaker (Studio) Notebook to use these services. In fact, you can run all services directly from your local computer or even your favorite IDE.
Before we move on, let’s understand how to interact with Amazon SageMaker services. You have two APIs:
SageMaker Python SDK Is a high-level Python API that abstracts code for building, training, and deploying machine learning models. In particular, it provides evaluators for first-class or built-in algorithms, and it also supports frameworks like TensorFlow, MXNET, etc. In most cases, you will use it to interact with interactive machine learning tasks.
AWS SDK Is a low-level API that is used to interact with all supported AWS services, not necessarily for SageMaker. AWS SDK is available for most popular languages such as Java, Javascript, Python (boto), etc. In most cases, you will use this API for things like creating automation resources or interacting with other AWS services that are not supported by the SageMaker Python SDK.
Why local environment?
Cost is the first thing that comes to mind, but also the flexibility of using your native IDE and the ability to work offline and run tasks in the AWS cloud when ready play an important role.
How the local environment works
You write the code to build the model, but instead of an instance of SageMake Notebook or SageMaker Studio Notebook, you do it on your local machine in Jupyter or from your IDE. Then, when everything is ready, you will start training on SageMaker instances on AWS. After training, the model will be stored in AWS. You can then run the deployment or batch conversion from your local machine.
Setting up the environment with conda
It is recommended to set up a Python virtual environment. In our case, we will use conda to manage virtual environments, but you can use virtualenv. Again Amazon SageMaker uses conda to manage environments and packages. It is assumed that you already have conda installed, if not, then you here…
Create a new conda environment
conda create -n sagemaker python=3We activate and verify the environment

Installing the required packages
To install packages, use the commands conda or pip… Let’s choose the option with conda…
conda install -y pandas numpy matplotlibInstalling AWS packages
Install AWS SDK for Python (boto), awscli and SageMaker Python SDK. The SageMaker Python SDK is not available as a conda package, so we’ll just use pip…
pip install boto3 awscli sagemakerIf this is your first time using awscli, you need to configure it. Here you can see how to do it.
The second version of the SageMaker Python SDK will be installed by default. Be sure to check for breaking changes in the second version of the SDK.
Installing Jupyter and building the core
conda install -c conda-forge jupyterlab
python -m ipykernel install --user --name sagemakerWe verify the environment and check the versions
Launch Jupyter via jupyter lab and select core sagemakerthat we created above.
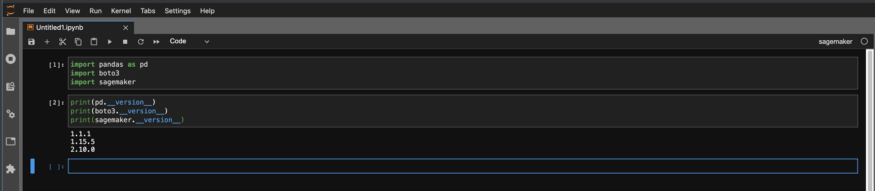
Then check the versions in notebook to make sure they are the ones you want.
We create and train
You can now start building your model locally and start learning on AWS when you’re ready.
Importing packages
Import the required packages and specify the role. The key difference here is that you need to specify directly arn roles, not get_execution_role()… Since you are running everything from your local machine with AWS credentials and not a notebook instance with a role, the function get_execution_role() will not work.
from sagemaker import image_uris # Use image_uris instead of get_image_uri
from sagemaker import TrainingInput # Use instead of sagemaker.session.s3_input
region = boto3.Session().region_name
container = image_uris.retrieve('image-classification',region)
bucket="your-bucket-name"
prefix = 'output'
SageMakerRole="arn:aws:iam::xxxxxxxxxx:role/service-role/AmazonSageMaker-ExecutionRole-20191208T093742"Create an appraiser
Create an evaluator and set hyperparameters as you normally would. In the example below, we train an image classifier using the built-in image classification algorithm. You also specify the type of Stagemaker instance and the number of instances you want to use for training.
s3_output_location = 's3://{}/output'.format(bucket, prefix)
classifier = sagemaker.estimator.Estimator(container,
role=SageMakerRole,
instance_count=1,
instance_type="ml.p2.xlarge",
volume_size = 50,
max_run = 360000,
input_mode="File",
output_path=s3_output_location)
classifier.set_hyperparameters(num_layers=152,
use_pretrained_model=0,
image_shape = "3,224,224",
num_classes=2,
mini_batch_size=32,
epochs=30,
learning_rate=0.01,
num_training_samples=963,
precision_dtype="float32")
Learning channels
Specify learning channels the way you always do it, there are also no changes compared to how you would do it on your notebook copy.
train_data = TrainingInput(s3train, distribution='FullyReplicated',
content_type="application/x-image", s3_data_type="S3Prefix")
validation_data = TrainingInput(s3validation, distribution='FullyReplicated',
content_type="application/x-image", s3_data_type="S3Prefix")
train_data_lst = TrainingInput(s3train_lst, distribution='FullyReplicated',
content_type="application/x-image", s3_data_type="S3Prefix")
validation_data_lst = TrainingInput(s3validation_lst, distribution='FullyReplicated',
content_type="application/x-image", s3_data_type="S3Prefix")
data_channels = {'train': train_data, 'validation': validation_data,
'train_lst': train_data_lst, 'validation_lst': validation_data_lst}We start training
Start the training task in SageMaker by calling the fit method, which will start training on your SageMaker AWS instances.
classifier.fit(inputs=data_channels, logs=True)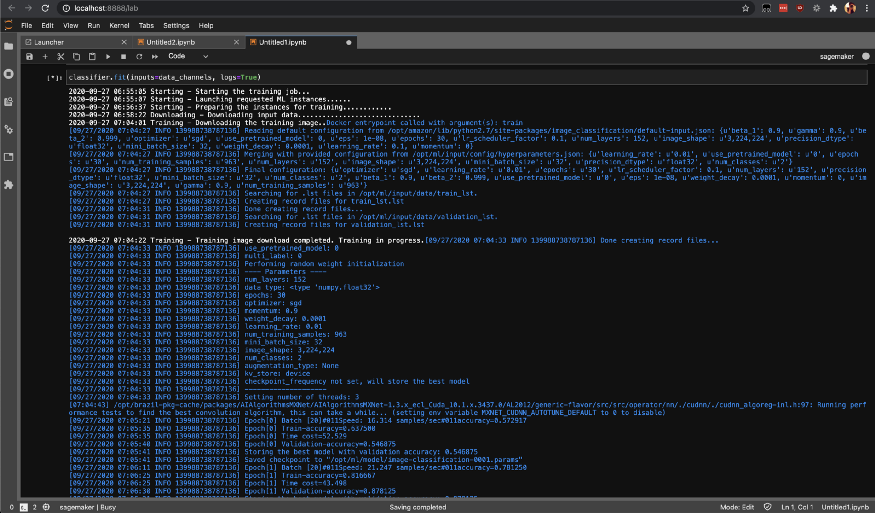
You can check the status of training tasks with list-training-jobs…
That’s all. Today we figured out how to locally set up the SageMaker environment and build machine learning models on a local machine using Jupyter. Besides Jupyter, you can do the same from your own IDE.
Happy learning!






