QCon Conference. Mastering Chaos: Netflix’s Guide to Microservices. Part 4
QCon Conference. Mastering Chaos: Netflix’s Guide to Microservices. Part 1
QCon Conference. Mastering Chaos: Netflix’s Guide to Microservices. Part 2
QCon Conference. Mastering Chaos: Netflix’s Guide to Microservices. Part 3
Unlike operational drift, introducing new languages to internationalize service and new technologies such as containers are conscious decisions to add new complexity to the environment. My operations team standardized the “tarmac road” of the best technologies for Netflix, which were baked into predefined best practices based on Java and EC2, but as the business grew, developers began to add new components such as Python, Ruby, Node-JS and Docker.

I am very proud that we were the first to advocate for our product to work perfectly, without waiting for customer complaints. It all started quite simply – we had operating programs in Python and several back-office applications in Ruby, but everything became much more interesting when our web developers announced that they intend to abandon the JVM and were going to transfer the web application to the Node software platform. js. After implementing Docker, things got a lot more complicated. We were guided by logic, and the technologies invented by us became reality when we implemented them for customers, because they made a lot of sense. I will tell you why this is so.
The API gateway actually has the ability to integrate great scripts that can act as endpoints for user interface developers. They converted each of these scripts in such a way that, after making the changes, they could deploy them to production and further to user devices, and all these changes were synchronized with the endpoints that were launched in the API gateway.
However, this repeated the problem of creating a new monolith when the API service was overloaded with code so that various failure scenarios occurred. For example, some endpoints were deleted or scripts randomly generated so many versions of something that these versions occupied all the available memory of the API service.
It was logical to take these endpoints and pull them out of the API service. To do this, we created Node.js components that ran as small applications in Docker containers. This allowed us to isolate any problems and failures caused by these node applications.
The cost of these changes is quite large and consists of the following factors:
- Productivity Tools. Managing new technologies required new tools, because a UI team using very successful scripts to create an effective model did not have to spend a lot of time managing the infrastructure, it only had to write scripts and check their performance.
Insight and sorting capabilities – a key example is the new tools needed to identify information about performance factors. It was necessary to know how much% the processor is occupied, how memory is used, and collecting this information required different tools. - Fragmentation of basic images – a simple basic AMI has become more fragmented and specialized.
- Node management. There is no off-the-shelf architecture or technology available that allows you to manage nodes in the cloud, so we created Titus, a container management platform that provides scalable and reliable container deployment and cloud integration with Amazon AWS.
- Duplication of a library or platform. The provision of the same basic platform functions to new technologies required its duplication in the cloud tools of Node.js developers.
- Learning curve and manufacturing experience. The introduction of new technologies inevitably creates new problems that must be overcome and lessons learned.
Thus, we could not limit ourselves to one “asphalt road” and had to constantly build new ways to advance our technologies. To reduce costs, we limited centralized support and focused on the JVM, new nodes, and Docker. We set priorities according to the degree of effective impact, informed the teams about the cost of their decisions and stimulated them to look for the possibility of reusing the already developed effective solutions. We used this approach when translating the service into foreign languages to deliver the product to international customers. Examples are relatively simple client libraries that can be generated automatically, so it’s easy enough to create a Python version, a Ruby version, a Java version, etc.
We were constantly looking for the opportunity to use the proven technologies that have proven themselves in one place and in other similar situations.
Let’s talk about the last element – changes, or variations. See how the consumption of our product varies unevenly by day of the week and by hour throughout the day. We can say that at 9 in the morning for Netflix comes the time of hard tests, when the load on the system reaches its maximum.

How can we achieve a high speed of implementing software innovations, that is, constantly make new changes to the system without causing interruptions in the delivery of the service and without creating inconvenience to our customers? Netflix did this by leveraging Spinnaker, the new global cloud-based management and continuous delivery (CD) platform.

It is critical that Spinnaker was designed to integrate our best practices so that as we deploy components to production, we can integrate their results directly into media delivery technology.

We managed to use two technologies that we highly value in the delivery pipeline: automated canary analysis and phased deployment. Canary analysis means that we direct a trickle of traffic to the new version of the code, and pass the rest of the production traffic through the old version. Then we check how the new code copes with the task – better or worse than the existing one.
Phased deployment means that if problems occur with deployment in one region, we will move on to deployment in another region. At the same time, the checklist mentioned above is necessarily included in the production conveyor. I’ll save a little time and recommend that you familiarize yourself with my previous presentation, “Netflix Global Operations Engineering in the Cloud Service,” if you want to delve deeper into this issue. You can watch the video recording of the performance by clicking on the link at the bottom of the slide.

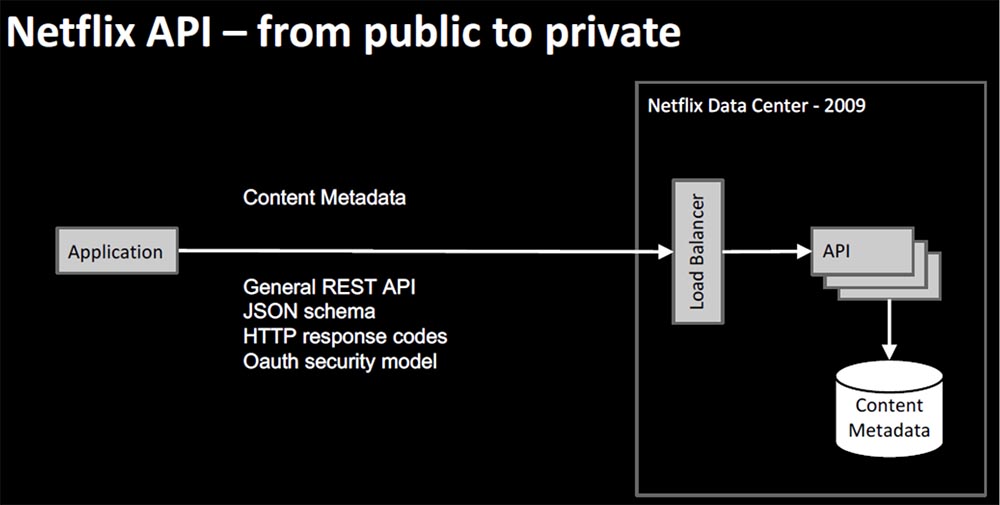
At the end of my presentation, I will briefly talk about the organization and architecture of Netflix. At the very beginning, we had a scheme called Electronic Delivery – electronic delivery, which was the first version of streaming media content NRDP 1.x. Here you can use the term “reverse flow”, because initially the user could only download content for later playback on the device. The very first Netflix electronic delivery platform of the year 2009 looked something like this.

The user device contained the Netflix application, which consisted of a UI interface, security modules, service activation and playback, based on the NRDP platform – Netflix Ready Device Platform.
At that time, the user interface was very simple. It contained the so-called Queque Reader, and the user went to the site to add something to Queque, and then viewed the added content on his device. The positive thing was that the client team and the server team belonged to the same Electronic Delivery organization and had a close working relationship. The payload was created based on XML. In parallel, the Netflix API for DVD business was created, which stimulated third-party applications to direct traffic to our service.
However, the Netflix API was well prepared to help us with an innovative user interface, it contained metadata for all content, information about which movies are available, which made it possible to generate watchlists. It had a common REST API based on the JSON scheme, the HTTP Response Code, the same as that used in modern architecture, and the OAuth security model is what was required at that time for an external application. This allowed us to move from a public model for delivering streaming content to a private one.
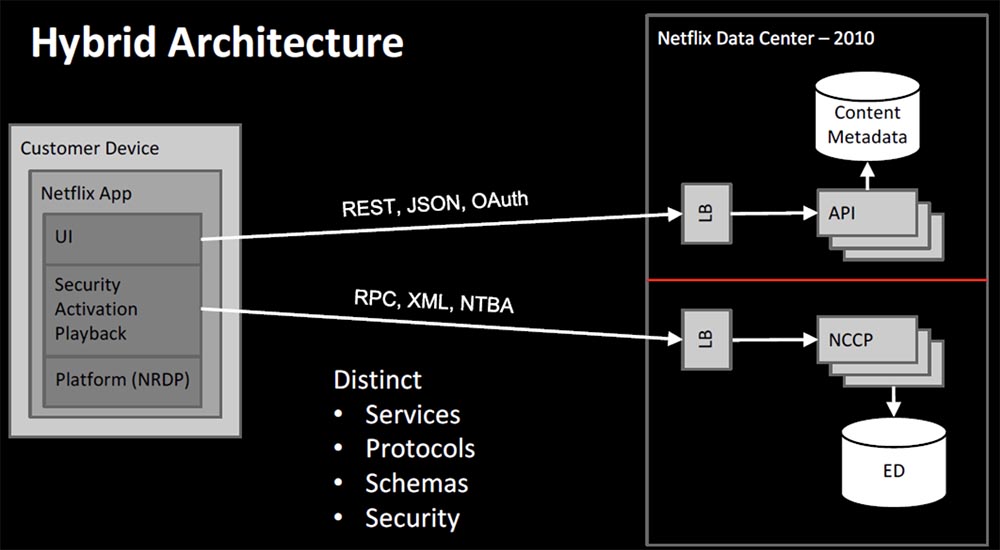
The transition problem was fragmentation, as now two services were functioning in our system based on completely different operating principles – one on Rest, JSON and OAuth, the other on RPC, XML and the user security mechanism based on the NTBA token system. This was the first hybrid architecture.
Essentially, there was a firewall between our two teams, because initially the API did not scale very well using NCCP, and this led to disagreement between the teams. The differences were in services, protocols, circuits, security modules, and developers often had to switch between completely different contexts.
In this regard, I had a conversation with one of the senior engineers of the company, to whom I asked the question: “What should be the right long-term architecture?”, And he asked the counter question: “You are probably more concerned with the organizational consequences – what happens if we integrate these things, and they will break what we have learned to do well? ” This approach is very relevant for Conway’s law: “Organizations designing systems are limited to a design that copies the communication structure of this organization.” This is a very abstract definition, so I prefer a more specific one: “Any piece of software reflects the organizational structure that created it.” I will give you my favorite saying, which belongs to Eric Raymond: “If four development teams work on the compiler, you will end up with a four-pass compiler.” Well, Netflix has a four-pass compiler, and that’s how we work.
We can say that in this case the tail is waving the dog. We do not have a solution in the first place, but an organization, it is it that is the driver of the architecture that we have. Gradually, we moved from a hash of services to an architecture called Blade Runner – “Blade Runner”, because here we are talking about boundary services and the capabilities of NCCP to separate and integrate directly into Zuul proxies, API gateways, and the corresponding functional “pieces” were turned into new microservices with more advanced security features, playback, data sorting, etc.
Thus, it can be said that departmental structures and the dynamics of the company’s development play an important role in shaping the design of systems and are a factor contributing to or preventing changes. The architecture of microservices is complex and organic, and its health is based on discipline and introduced chaos.
Some advertising
Thank you for staying with us. Do you like our articles? Want to see more interesting materials? Support us by placing an order or recommending to your friends, cloud VPS for developers from $ 4.99, A unique analogue of entry-level servers that was invented by us for you: The whole truth about VPS (KVM) E5-2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps from $ 19 or how to divide the server correctly? (options are available with RAID1 and RAID10, up to 24 cores and up to 40GB DDR4).
Dell R730xd 2 times cheaper at the Equinix Tier IV data center in Amsterdam? Only here 2 x Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV from $ 199 in the Netherlands! Dell R420 – 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB – from $ 99! Read about How to Build Infrastructure Bldg. class using Dell R730xd E5-2650 v4 servers costing 9,000 euros per penny?





