In the Land of Flows – Kafka, Part 2: Raising Consumers

Streaming ledger of Kafka
In the previous article, we discussed exactly how the producer side works when sending messages, and given the data stored inside the theme, let’s now delve into the consumer side.
The purpose of this part is to cover the following:
How the consumer side works;
How consumer group scaling works;
How scaling works with a parallel consumer;
Setting to avoid slow consumers.
You can find relevant code samples on Github Here.
A typical Kafka Consumer Loop should look something like the following snippet:

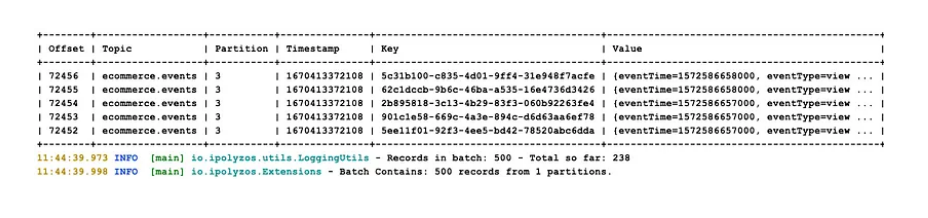
We run the method poll() for the consumer, we simulate a small amount of work and finally show the records that it has processed.
Note: Method show() for records is derived from the extension’s helper function for printing records in a convenient and structured way:
So let’s try to better understand what’s going on here. The following diagram gives a more detailed explanation.
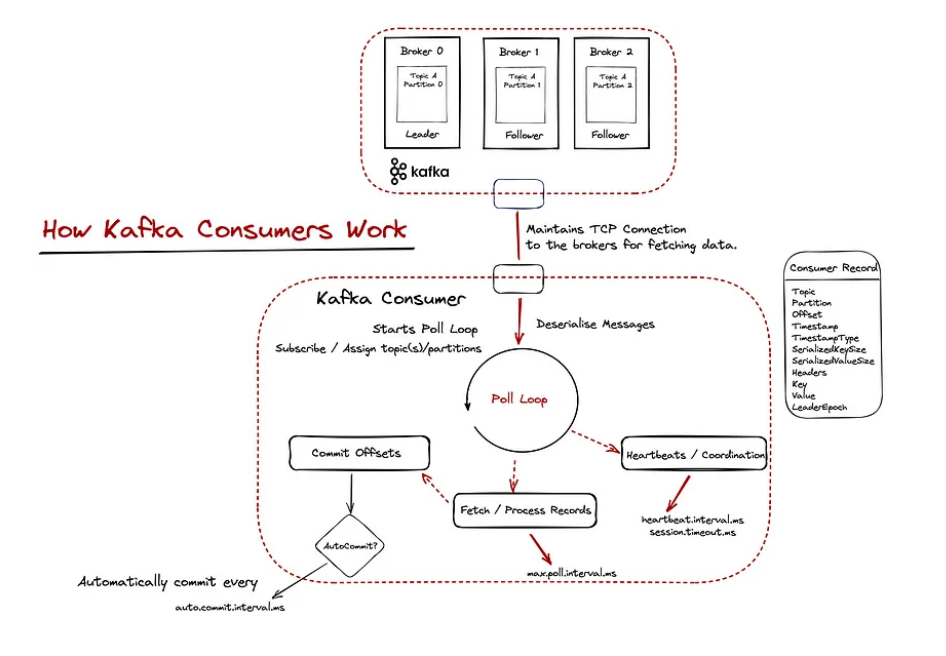
Kafka uses a model based on data extraction. At the “heart of the consumer” is the poll loop. The poll loop is important for two reasons:
It is responsible for data sampling (providing Consuming Records) for processing by the consumer;
sends alerts and coordinates consumers so that the consumer group is aware of available consumers and needs to be rebalanced.
Consumer applications maintain TCP connections to brokers and send fetch requests to retrieve data. The data is cached and periodically returned from the method poll(). When data is returned from a method poll()the actual processing takes place, and as soon as it is completed, additional data is requested, and so on.
What’s important to note here (and we’ll get into that in the next part of the article) is the capture of message offsets. This is Kafka’s way of knowing that a message has been received and processed successfully. By default, offsets are captured automatically at regular intervals.
Data volume – how much data will be retrieved, when more data needs to be requested, etc. – defined by configuration options such as fetch.min.bytes, max.partition.fetch.bytes, fetch.max.bytes, fetch.max.wait.ms. You might think that the default options might work for you, but it’s important to test them and think carefully about your use case.
To make this clearer, let’s assume you are fetching 500 records from a loop poll() for processing, but processing for some reason takes too long for each message. max.poll.interval.ms defines the maximum time the consumer can be idle before retrieving additional records; those. call the poll method, and if this threshold is reached, the consumer is considered lost and a rebalance will be triggered – although our application was just slow to process.
So, when reducing the number of records the poll() loop has to return, and/or better configuring some configurations such as heartbeat.interval.ms and session.timeout.ms, in this case it may be reasonable to use the consumer’ group to coordinate ov.
Starting the consumer
At this point I will start one consuming instance in my ecommerce.events. Remember from part 1 that this partition consists of 5 partitions. We will execute in our cluster Aiven for Kafka, using the consumer’s default configuration settings, and my goal is to see how long it takes the consumer to read 10,000 messages from a topic, assuming a 20ms per message processing time. You can find the code Here.
We can see that it takes about 4 minutes for one consumer to do this kind of processing. So how can we do better?
Consumer side scaling
Consumer groups and parallel consumption model
Consumer groups are Kafka’s way of dividing work among different consumers, as well as a level of concurrency. The highest level of concurrency you can achieve with Kafka is having one consumer consuming from each topic partition.
Scenario 1: #Partitions = #consumers
In this scenario, the available partitions will be distributed equally among the available consumers in the group, and each consumer will own those partitions.
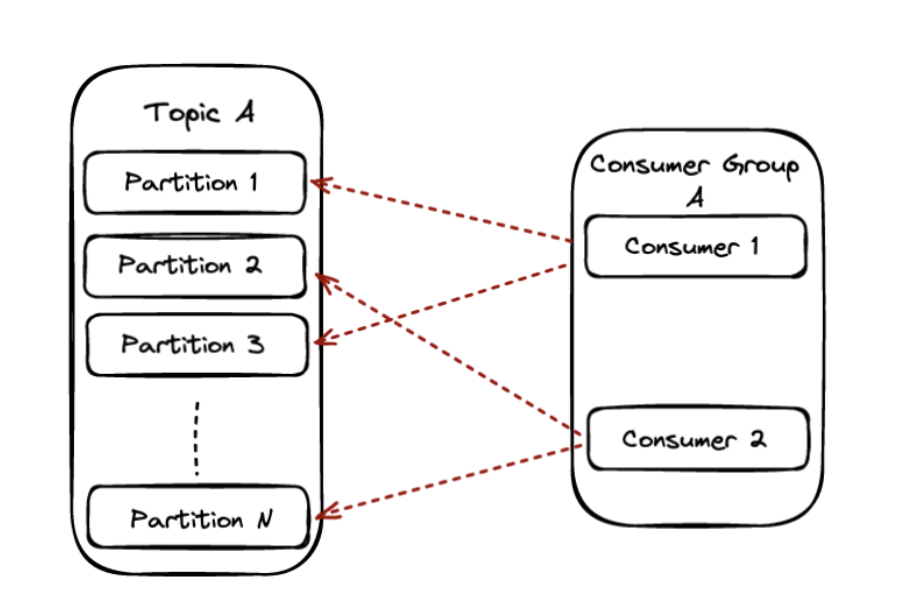
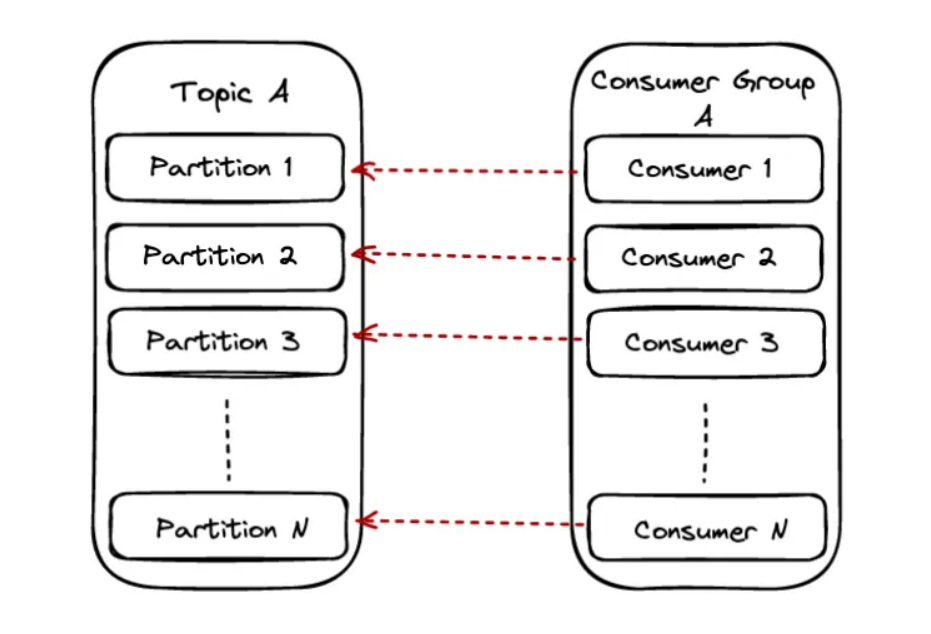
Scenario 2: #Partitions = #consumers
When the partition number equals the available consumers, each consumer will read data from exactly one partition. In this scenario, we also achieve the maximum parallelism that we can achieve on a particular topic.
Scenario 3: #Partitions = #consumers
This scenario is similar to the previous one, only now we will have one consumer running but not running. On the one hand, this means that we are wasting resources, but we can also use this consumer as Failover in case another consumer in the group goes down.
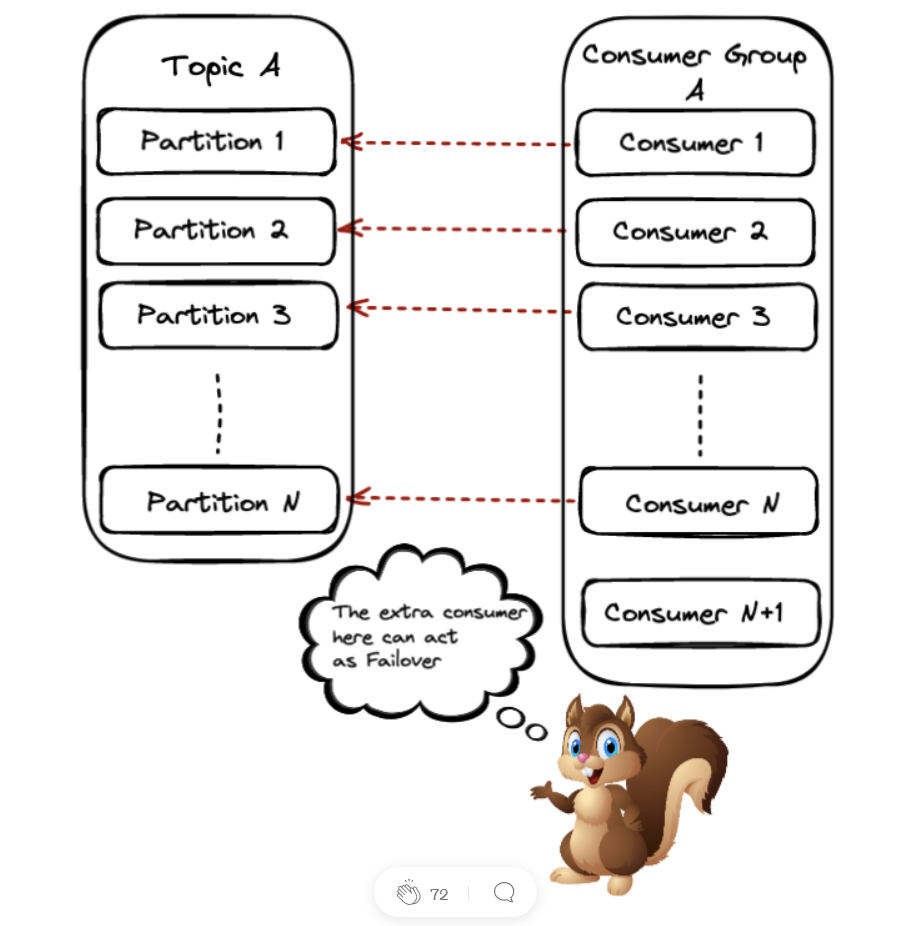
When a consumer goes down, or similarly, a new one joins the group, Kafka will have to initiate a rebalance. This means that partitions need to be revoked and reassigned to the available consumers in the group.
Let’s run our previous example again – consuming 10k messages – but this time with 5 consumers in our consumer group. I will be creating 5 consuming instances from a single JVM (using kotlin coroutines), but you can easily reconfigure the code (found here) and just run multiple JVMs.
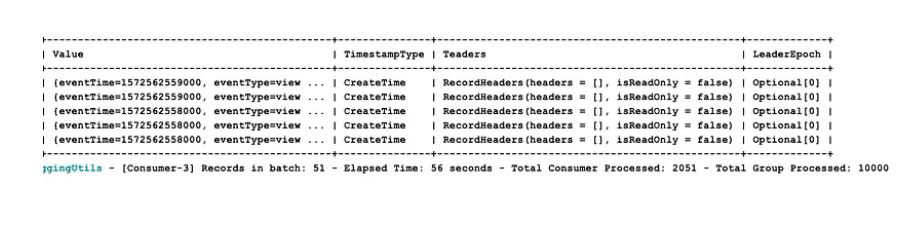
As expected, we see that the consumption time has been reduced to less than a minute.
But if Kafka’s maximum concurrency level is one consumer per partition, does that mean we’ve hit the scaling limit? Let’s see how to deal with this further.
What about the parallel consumption model?
Up to this point, we might have two questions in mind:
If #partitions = #consumers in a group of consumers, how can I scale even more if necessary? It is not always easy to pre-calculate the number of partitions, and/or we may need to account for sudden jumps.
How can I minimize rebalancing time?
One solution to this problem could be the parallel pattern consumer. You can have consumers in your group consuming from one or more topic partitions, but then they spread the actual processing to other threads.
One such implementation can be found here.
It provides three ordering guarantees − Unordered, Keyed and Partition.
Unordered – makes no guarantees.
Keyed – guarantees ordering by key, but with the caveat that the key space must be quite large, otherwise you may not notice a significant performance improvement.
Partition – at any time, only one message will be processed for each partition.
Along with that, it also provides various ways to fix the offset. It’s a pretty nice library that you might want to take a look at.
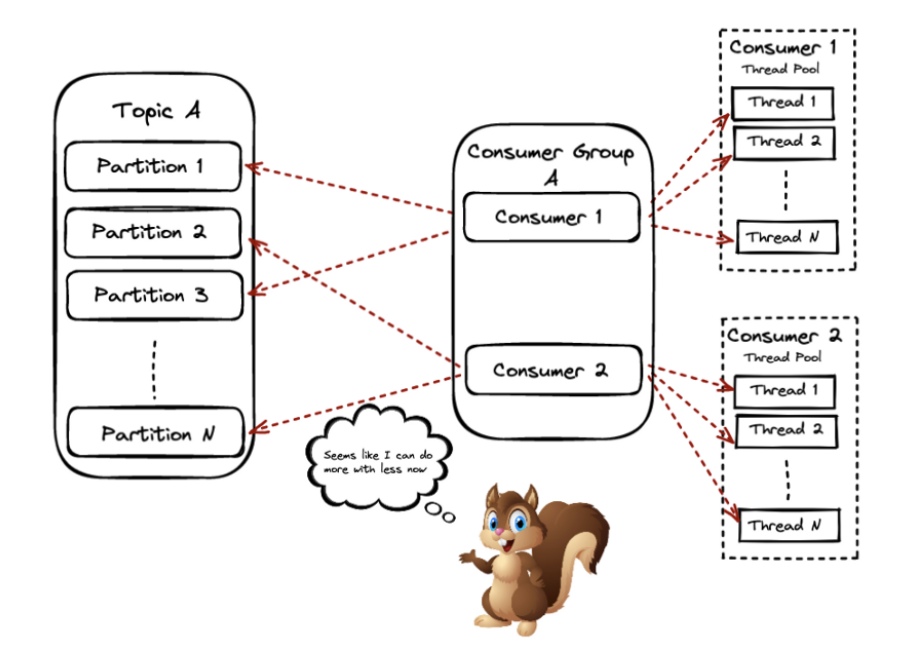
Returning once again to our example to answer the question – how can we violate the scaling constraint? We will use the parallel consumer pattern – you can find the code Here.
Using a single concurrent instance of consumer in our theme with 5 partitions, specifying key order, and using 100 threads concurrency.

As a result, the reception and processing time 10 thousand messages takes whole 6 seconds.
Notice in the screenshot how different packets are processed in different threads of the same consumer instance.
and if we use 5 concurrent consumer instances

we managed to shorten this time up to 3 seconds.
Notice in the screenshot how different packets are processed in different threads in different consumer instances.

“Apache Kafka for Developers” — an advanced course with practice in Java or Golang and the Spring+Docker+Postgres platform
Summarizing
In this part, we have seen how the consumer side of Kafka works. As a guideline when creating consumer applications:
We need to take into account the number of partitions that each theme has.
Think about our requirements in terms of processing and try to take into account the slowness of consumers.
How exactly can we scale both with groups of consumers and with a parallel consumption model?
Here you need to take into account message order, amount of key space, and partition guarantees and see which approach works best (or a combination of both).
Upgrade your developer skills with Apache Kafka!
You can’t just take … and not use Kafka.
Knowledge of Apache Kafka in 2023 is a must for infrastructure engineers and programmers who want to expand their capabilities.
An advanced course with practice in Java or Golang and the Spring + Docker + Postgres platform will take you to a new level of tool ownership.
We start on March 10, 2023. You are waiting for meetings, live broadcasts, answers to questions from speakers, discussion of Kafka with other intensive participants, a lot of practice on the stands and consolidation of the material.
In our course, in a few days you will begin to understand Kafka, as if you created it yourself, and we will also tell you about the architecture – register right now: slurm.club/3xKd9nl