Have you ever looked at goroutines this way?

Don't worry about understanding the image above right now, we'll start with the very basics.
Goroutines are distributed across threads, which are managed by the Go Scheduler under the hood. We know the following about goroutines:
Goroutines are not necessarily faster than threads in terms of execution speed, since they require threads to execute them.
The key advantage of goroutines is in such nuances as the switching context, the amount of memory they occupy and the cost of creation and “deletion”.
You've probably heard of Go's scheduler before, but how much do we know about how it works? How does it connect goroutines to threads?
Let's look at the operations that the scheduler performs one by one.
1. M:N Scheduler
The Go team has made it easier for us to compete. Just think about how all you need to do to create a goroutine is to add a prefix go to the function declaration.
go doWork()But behind this simple step there is a much more complex system.
Go simply doesn't give us access to threads. Threads are managed by a scheduler, which is a key part of Go's runtime.

So what about M:N?
This means that the role of the Go scheduler is to bind M goroutines to N kernel threads, forming an M:N model. You can either have more OS threads than kernels or more goroutines than threads.
Before we dive deeper into how the scheduler works, let's clarify two terms that are often used together: concurrency and concurrency.
Competitiveness: This is about having several tasks executed simultaneously, but not necessarily at the same point in time.
Parallelism: This means that multiple tasks are running at the same time, most likely using more than one CPU core.

Let's look at how the Go scheduler manages threads.
2. PMG model
Before we unravel the inner workings, let's understand what P, M and G are.
G (goroutine)
A goroutine is the smallest execution unit in Go and operates like a lightweight thread.
Together with Go runtime, a goroutine is a structure g. As soon as it is declared, it finds its place in the local execution queue of the logical processor P. P, in turn, passes it on to the OS thread (M) for execution.
A goroutine can be in three (main) states:
Waiting: In this state, the goroutine is idle. For example, it pauses for operations with channels or locks, or can be stopped by a system call.
Runnable: The goroutine is ready to be executed, but is not yet executed. She is waiting her turn on stream (M).
Running: The goroutine is executed on a thread (M). This will continue until the work is done, or until it is interrupted by the scheduler, or something else blocks it.

Goroutines NOT used once and then thrown away.
When a new goroutine is initiated, the Go scheduler goes to the pool of goroutines to pick one up, and if there are none, it creates a new one. This new goroutine is added to the processor's execution queue (P).
P (Logical Processor)
With the Go scheduler, when we say “processor,” we mean a logical entity, not a physical processor.
However, by default the number of P is set to the number of available cores on the host, you can change this value using runtime.GOMAXPROCS(int).
runtime.GOMAXPROCS(0) // получить доступное количество логических ядер на хосте
// Output: 8 (зависит от процессора)If you plan to change this value, it is best to do it once at the start of the application. If you change it in runtime, it will lead to STW (stopTheWorld), the entire application will pause while the number of processors is changed.
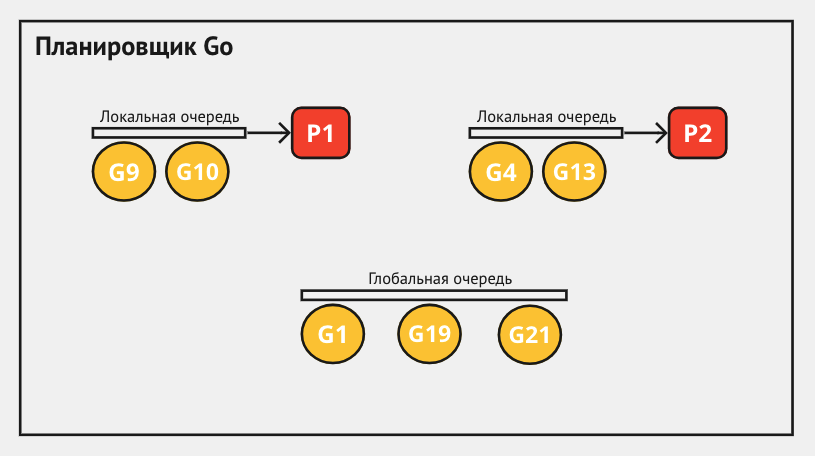
Each P contains its own list of runnable goroutines, called a Local Run Queue, which can be up to 256 goroutines in size.

Initiating a goroutine: using
go func()Go runtime creates a new goroutine, or uses an existing one from the pool.Queue positioning: The goroutine looks for space in the local queues of logical processors (P), and if they are all full, it is placed in the global queue.
Linking to a stream: in this step thread (M) comes into play. The thread takes P and starts executing goroutines from its local queue. As soon as a thread starts executing a goroutine, the processor (P) that had the goroutine in its queue is associated with that thread (M) and becomes unavailable to other threads.
“Work stealing”: if a processor's (P) local queue is empty, thread M tries to borrow half of the runnable goroutines from another processor's (P) local queue. If nothing is found, thread (M) checks the global queue and then Net Poller (there is a process diagram below work stealing).
Resource allocation: After thread M selects goroutine G, it provides it with all the necessary resources.
“What about blocked streams?”
If the goroutine makes a system call that will take a long time (such as reading a file), thread M will wait.
But the planner is not happy with those who just sit and wait. It unbinds a busy thread M from its processor P, and associates another runnable goroutine from P's queue to a new or existing free thread M that is associated with that processor.

Work stealing process
When thread M has completed all its tasks and has nothing else to do, this does not mean that it will be idle.
The thread will look for goroutines in the local queues of other logical processors and take half of their goroutines:

Every 61 ticks, thread M checks the global queue, and if there is a runnable goroutine in it, work stealing stops.
Thread M checks for runnable goroutines in the local queue associated with its processor P.
If the thread doesn't find anything in the local queue, it checks the global queue again.
The thread checks the network poller for any waiting goroutines working on the network.
If the thread still has not found any tasks after checking the network poller, it will go into active cyclic search mode.
In this state, the thread will try to borrow goroutines from the local queues of other processors.
After all these steps, if the thread still has not found a job, it stops actively searching.
Now, if new goroutines appear and there is a free processor without a thread associated with it, another thread can be attracted to work.
Please note that the global queue is checked twice: once every 61 ticks and if the local queue is empty.
“If M is associated with his P, how can he take goroutines from another processor? Is a thread changing from one processor to another?”
The answer is no.
Even if M then takes goroutines from an unrelated processor P, it will execute these goroutines using their processor. Thus, while the thread is executing other people's goroutines, it does not lose contact with its own processor.
“Why 61?”
When developing algorithms, and especially hashing algorithms, it is a practice to use prime numbers that are divisible only by 1 and themselves.
This can reduce the chance of patterns emerging that ultimately lead to collisions or other unwanted behavior.
If you check more often, it may take too many resources; if you check less often, the goroutines may wait too long for execution.
Network Poller
We did not cover the topic of network poller, but we mentioned it in the work stealing diagram.
Like the Go scheduler, the Network Poller is a Go runtime component and is used to execute network-related requests, such as network I/O operations.
There are 2 types of system calls:
Network related system calls: When a goroutine performs a network I/O operation, instead of blocking the thread, it is added to the network poller. Netpoller waits for the operation to be executed asynchronously, and when it waits, the goroutine becomes runnable again and its execution becomes available to the thread.
Other system calls: if they are potentially blocking and are not executed by the network poller, the goroutine will completely occupy the OS thread, this thread will be blocked and Go runtime will execute the remaining goroutines on other free threads.
approx. lane Network poller is a Go runtime unit that implements multiplexing of network I/O operations. For example, in Linux this concept is implemented by the epoll tool.