features of internal implementation
Atomics in Go is one of the methods for synchronizing goroutines. They are in the standard library package sync/atomic. Some articles compare atoms With mutex, since these are low-level synchronization primitives. They provide benchmarks and speed comparisons, such as Go: How to Reduce Lock Contention with the Atomic Package.
However, it is important to understand that while these are low-level synchronization primitives, they are inherently different. First of all, atomics are “low-level atomic memory primitives”, as noted in the documentation, that is, they are low-level primitives that implement atomic memory operations. In this article I will talk about some of the features of their internal implementation and the difference from mutexes.
internals of atomics
Let’s first take an example from the documentation and look at the Swap operation:
The swap operation, implemented by the SwapT functions, is the atomic equivalent of:
old = *addr
*addr = new
return oldSwapT refers to all Swap operations with various data types. Let’s take SwapInt64 as an example. The function is described in sync/atomic/doc.go:
func SwapInt64(addr *int64, new int64) (old int64)However, its implementation is no longer in Go, but in assembler and is in sync/atomic/asm.s:
TEXT ·SwapInt64(SB),NOSPLIT,$0
JMP runtime∕internal∕atomic·Xchg64(SB)However, here we see a jump to another function (simple jump) called Xchg64 and this function is in the Go runtime. Here we can already see the division by processor architectures.
Here is the code for 64-bit Intel 386:
// uint64 Xchg64(ptr *uint64, new uint64)
// Atomically:
// old := *ptr;
// *ptr = new;
// return old;
TEXT ·Xchg64(SB), NOSPLIT, $0-24
MOVQ ptr+0(FP), BX
MOVQ new+8(FP), AX
XCHGQ AX, 0(BX)
MOVQ AX, ret+16(FP)
RETAnd this one is for ARM64:
// uint64 Xchg64(ptr *uint64, new uint64)
// Atomically:
// old := *ptr;
// *ptr = new;
// return old;
TEXT ·Xchg64(SB), NOSPLIT, $0-24
MOVD ptr+0(FP), R0
MOVD new+8(FP), R1
MOVBU internal∕cpu·ARM64+const_offsetARM64HasATOMICS(SB), R4
CBZ R4, load_store_loop
SWPALD R1, (R0), R2
MOVD R2, ret+16(FP)
RET
load_store_loop:
LDAXR (R0), R2
STLXR R1, (R0), R3
CBNZ R3, load_store_loop
MOVD R2, ret+16(FP)
RETIt’s worth noting here that Go uses its own assembly language. This is done to compile for various platforms and you can read more about it, for example, here: A Quick Guide to Go’s Assembler. It is important to note that the compiler operates on a semi-abstract instruction set. Instruction selection occurs in part after code generation. For example, the MOV operation can end up as a separate operation, or it can be converted into a set of instructions, and this will depend on the processor architecture. The language itself is based on Plan 8 assembler.
Thus, we cannot always be sure from the standard library code that there will be no changes in the compiled code for our architecture. Let’s see what code will be compiled as a result for the operation in question SwapInt64:
package main
import (
"sync/atomic"
)
func main() {
var old, new int64 = 1, 10
println(old, new)
new = atomic.SwapInt64(&old, new)
println(old, new)
}I used IDA64 to parse a binary file, but I advise you to look at the disassembled code in Compiler Explorer (you can choose different architectures, versions of Go, etc.). It will also be interesting to look at the compilation steps, ast representations, and optimizations applied in Go SSA Playground. Now let’s find the main function in the disassembled code:
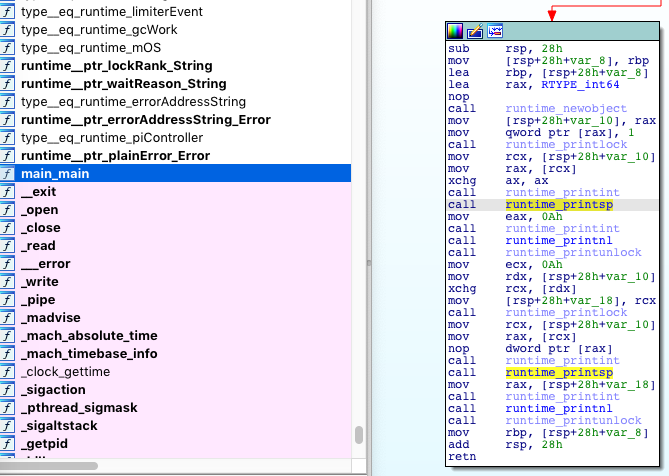
Code for new = atomic.SwapInt64(&old, new) located exactly after the first call runtime_printunlock and until the next сall runtime_printlock
mov ecx, 0Ah
mov rdx, [rsp+28h+var_10]
xchg rcx, [rdx]
mov [rsp+28h+var_18], rcxWe have only four instructions: three mov and one xchg. Further analysis is difficult because the number of cycles of a particular instruction may depend on several factors, such as the model and architecture of the processor, types of operands (registers, memory) and some other conditions (cache miss, for example). If you are interested in more detailed calculations and details, then you can refer to this manual or to Intel® 64 and IA-32 Architectures Optimization Reference Manual (APPENDIX D. INSTRUCTION LATENCY AND THROUGHPUT).
Despite the difficulty of calculating the speed of execution of processor instructions, we can see that the assembler code is minimal and in most cases it will most likely execute faster than the mutex implementation. Next, we will look at how the mutex is arranged in order to confirm the assumptions or refute them.
mutex internals
A mutex is much more complex than an atomic structure than it might seem at first glance. First of all, we have two kinds of mutexes: sync.Mutex And sync.RWMutex. Each of them has methods Lock And Unlocky RWMutex there is an additional method RLock (blocking for reading). In both types, methods Lock quite long compared to atomics.
At Mutex method code Lock includes two types of blocking. The first option is when you manage to capture a non-locked mutex, the second option is quite long and it runs if the mutex is locked:
// Lock locks m.
// If the lock is already in use, the calling goroutine
// blocks until the mutex is available.
func (m *Mutex) Lock() {
// Fast path: grab unlocked mutex.
if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked) {
if race.Enabled {
race.Acquire(unsafe.Pointer(m))
}
return
}
// Slow path (outlined so that the fast path can be inlined)
m.lockSlow()
}As you can see, the first option is quite fast and includes one atomic operation. The second option includes quite a lot of code and will not be analyzed in detail here: it also uses atomics in the blocking process, but it is obvious that it is executed even longer than the first option (Fast path).
At RWMutex method code Lock includes a method call Lock structures Mutex:
// Lock locks rw for writing.
// If the lock is already locked for reading or writing,
// Lock blocks until the lock is available.
func (rw *RWMutex) Lock() {
if race.Enabled {
_ = rw.w.state
race.Disable()
}
// First, resolve competition with other writers.
rw.w.Lock()
// Здесь пропущена часть кода ...
}
}And the structure itself RWMutex includes structure Mutex as one of the fields:
type RWMutex struct {
w Mutex // held if there are pending writers
// Здесь пропущена часть кода ...
}Method RLock at RWMutex much faster and contains less code, but nevertheless no faster than the atomics that are involved there:
func (rw *RWMutex) RLock() {
// Здесь пропущена часть кода ...
if atomic.AddInt32(&rw.readerCount, 1) < 0 {
// A writer is pending, wait for it.
runtime_SemacquireMutex(&rw.readerSem, false, 0)
}
// Здесь пропущена часть кода ...
}Conclusion
As a conclusion, I would like to say once again that comparisons of the performance of atomics with mutexes in Go will not be in favor of the latter. In the article, we analyzed the internal structure of atomics using the example SwapInt64 and take a look at the interior Mutex And RWMutex. Knowing the details of their implementation, we can say that atomics are faster than mutexes without measurements. However, it is worth mentioning here that the use of atomics is limited to certain cases (they may not always suit us).