Designing an efficient caching system for a high-load system
Introduction
The ability to process large volumes of queries and data in real time is a key aspect of the reliability and performance of modern information systems. One of the ways to increase reliability, reduce load and, as a result, server costs, is to use an effective caching system at the application level. In this article I will talk about possible pitfalls and effective strategies for building such a system.
What is caching
Caching is the process of temporarily storing copies of data in intermediate storage, called a cache, to speed up access to data and reduce load on servers. Cache is implemented at different layers, including software (such as web cache), hardware (such as processor cache), or even as a separate layer of a distributed system.
How caching is used
Consider an example: a news site that stores a list of the latest news. Without a caching system, the server must contact the database to obtain a list of news items every time a user requests the site's home page. This takes time and resources. Caching helps save them: the current list of news is stored in a quickly accessible cache after the first request. On subsequent requests, the server retrieves the list from the cache, significantly speeding up page rendering for users and reducing the load on the database.
What could go wrong
Caching is not a panacea, and if not carefully designed, it can lead to a number of problems. Let's look at the key problems and their causes:
Inefficient cache filling
Let's say that before providing the user with news, we want to enrich it with additional information, for example, about the weather. To obtain this information, we use a separate system that provides HTTP endpoints for retrieving weather data. To avoid putting unnecessary strain on this system, we decide to store weather data in a cache. However, high latency on the weather backend will result in high latency on our application. To prevent this situation, we set a low timeout on HTTP requests to the system that provides weather data. Thus, if the weather system does not have time to respond within the specified time interval, we simply do not include weather information in the news for the user. However, the weather data is not stored in the cache, which means that with each request we are forced to contact the backend to try to get this data. This can lead to additional load on the backend and deterioration in its performance.
Data unavailability during outages
During the unavailability of some backend or database, the user will not notice this unavailability if we give him data from the cache. However, if the time to live (TTL) of the cache entries has expired and the backend has not yet recovered by this time, the data will be inaccessible to the user. But in most cases, a strategy in which the user sees outdated data is preferable to seeing no data at all. In such cases, it is useful to be able to reuse stale data in the cache over some extended time interval to give the backends more time to recover.
Duplicate HTTP requests
The system may encounter multiple identical requests to a server or database when multiple users request the same data at the same time. This results in repeated processing of the same data, which increases the load on the infrastructure and can slow down query processing for all users. In some scenarios, the share of identical requests can reach tens of percent. For such cases, it is important that the caching system redirects all repeated requests to wait for the result of the first request.
How to prevent common problems
I will list modern solutions for creating advanced caching strategies that will help avoid the problems listed above.
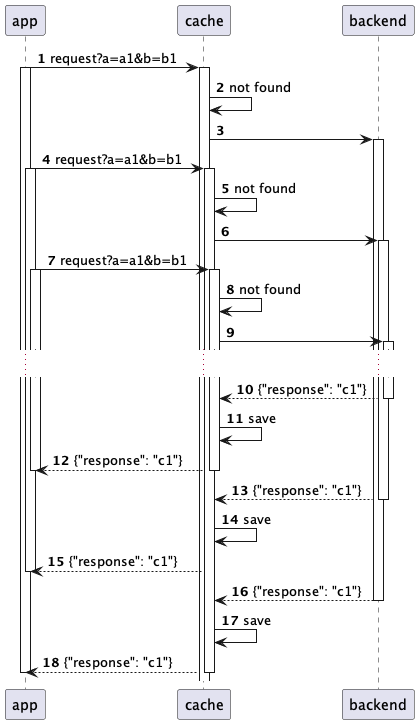
Singleflight as a separate caching layer
Singleflight is a pattern in which identical requests to the backend are deduplicated on the fly using a specific key. In a caching system, you can implement singleflight as the first layer in a multi-level cache that uses the caching key to deduplicate queries. Creating such a layer optimizes the processing of identical requests by ensuring that only one request is executed at a time, while other consumers simply wait for the result of the first request. Singleflight is effective in scenarios where identical requests are likely to arrive at the same time. This is especially useful for high-load web services where all users' data must be enriched with the same information, but long-term caching of this information is prohibited by business rules.
Before
After

Fallback to stale data in cache
For many systems, continuous access to data is more important than its relevance. For example, in a social media feed, it is better to show user avatars and nicknames with some delay than not show them at all. To ensure access to information during a service failure, you can use the “Fallback cache” pattern.
“Fallback cache” is a pattern that allows the system to use less current backup cache data when fresh data is unavailable due to errors or failures in the data source.
Fallback cache functionality can be added to the normal cache in an application by using two values instead of a single time to live (ttl): the time during which the data is considered fresh and no request to the real data source is required (cacheTtl), and the time during which the data will be considered obsolete, but can still be used as a backup if errors occur in the data source (fallbackTtl). Then the physical lifetime in the data store will be equal to max(cacheTtl, fallbackTtl)
Before

After

Additional timeout
If a downstream system or database experiences a crash and is delayed in responding, its requests will time out and not be cached. This will cause more and more records to gradually fade and increase the load, which will likely make the situation even worse. Increasing the timeout to this service may help, but it will affect other users by increasing the time they wait for a response.
To solve this problem, you can introduce an additional timeout – how much additional data you can wait in the background without interrupting the physical request. In this scenario, the impact of an outage on users will be reduced because the user will not experience an increase in response time, but the caching system will make maximum effort to wait for updated data.
Before

After

General implementation scheme
Let's look at how these proposed solutions might function in practice:
When a request is received, the system first checks to see if a request with the same key is already running. If a request is already running, the system simply waits for a response from the existing request.
The system then checks for current information in the cache that can satisfy the request. If such information is available, it is immediately returned to the user without further processing.
If there is no current data in the cache, we make a request to the real backend or database.
In case of failure or delays in the backend, the system can use outdated data from the cache as a temporary solution using the Fallback mechanism. This ensures continuity of the service and helps reduce the load on the backend. It is important to note that the request itself is not interrupted, and the system continues to wait for a response in the background in order to store the data in the cache. And all new requests, including retrays, will not create new network requests, but will connect to existing ones and wait for their result.
Conclusion
An effective caching system allows you to increase the stability and availability of the service under conditions of high loads or failures, which is extremely important in modern conditions. In my review, I presented effective mechanisms, including singleflight and fallback, that will help avoid system overload and ensure high performance and reliability of highly loaded systems.





