6 utilities to speed up your localizations
Our Mobile Team Doc&Loc “Kaspersky Lab” is engaged in the preparation of documentation and localization of the company's B2C products for mobile devices. The main difficulty (and at the same time the trick) of our work is that it is necessary to regularly prepare translations into 34 languages in an extremely short time.
My name is Yuliana Solomatina, I am a Doc&Loc engineer, and in this article I will talk about automation tools that help us cope with the influx of tasks and meet deadlines without sacrificing quality. By the way, we developed many of these tools ourselves.

If you are interested in learning about the processes themselves, I highly recommend this article by my colleague Nikita Avilov. He explained in detail why we translate all texts from English, how we introduced machine translation, how we interact with contractors, and described step-by-step algorithms for localizing GUI texts, online references and legal documents. I will focus specifically on the tools that we use in our work.
Sinker
This is a service for two-way synchronization of localized resources between closed VCS used in the company (tfs, git/monorepo) and an externally accessible service in which freelance linguists can work. During synchronization, two-way conversion of formats from many used into one universal one is performed – XML, which is uploaded to cloud CAT for translation. The Smartcat service is used as a CAT. Sinker helps localizers upload resource files, help and agreements from working directories to Smartcat and back in a couple of clicks.
Visually, Sinker is a web page with a list of configuration files. For each product and type of localized resources, its own config file is created.

To start synchronization, you must fill in the following fields:
BranchSource, BranchTarget — branches for downloading and uploading files, respectively;
IntSource, IntTarget — the directory in which the source (English) file is stored, and the directory into which the translated file will be downloaded;
ExtSource, ExtTarget — names of files in Smartcat;
ToExt1, ToInt1 — names of parsers for converting from the source format to xml and back;
ExtPush, ExtPull — commands for loading and unloading indicating the project ID in Smartcat.
At the bottom of the config, in a special variable Languages, language codes for localizations are specified. This variable is involved in filling out fields IntTarget, ExtSource, ExtTarget. This ensures that the translated files are downloaded into the appropriate language folders.
When working on a localization task, an engineer needs to make only minimal changes to the config structure, namely:
The remaining fields remain unchanged and are edited only when structurally important changes occur in the project (for example, new files appear or the project ID in Smartcat changes).
After setting up the config, the localizer just needs to start the upload by clicking on the Run button and wait for the upload to complete (i.e., the state changes to Completed).

Parsers
At different stages of localization, we use different programs that read different file formats. Therefore, in order for localized files to be quickly and correctly converted from formats used in development (html, txt, etc.) to a format that can be read by SmartKat (XML), and vice versa, we use parsers. Ours are based on rules and regular expressions. Parsers have a single template with fixed fields:

Rules – list of rules.
Each rule has the following rules:
segment type: type (regular segment type – string);
regular expressions defining the beginning and end of a segment: (begins, ends).
map — a dictionary of replacements in the specified order.
map_data — an optional dictionary of replacements for parts of the file that are not related to the text being translated. It may be missing, then replacements in the entire file will be made according to the map dictionary.
map_pre_parse — an optional dictionary of replacements for the entire contents of the source file (after uploading from VCS, before parsing). May be missing.
map_post_parse — an optional dictionary of replacements for the entire contents of the xml file (after parsing, before loading into CAT). May be missing.
map_use_regex — if the parameter is present, the regular expression mode (regex.sub) is enabled for map and map_data replacements.
map_empty — optional replacement of an empty source segment with a specified sequence of characters. Needed to bypass the inability of the SC to work with empty source segments.
source_encoding — default encoding, can be overridden at startup.
The use of parsers allows us to save time and minimize the risk of errors in the process of moving from one file format to another, and thanks to the use of a single template for writing rules, it is convenient and easy for us to maintain our parsers – make changes, correct errors and add new rules.
Autotests
When processing such a large pool of localizations, it is impossible to manually track all possible errors. Of course, we could run QA tools such as XBench or AssurIT on each language of each task, but this is a rather monotonous and time-consuming task. So here we are very helped by autotests – a system for automatically checking localization resources for technical and linguistic errors. Autotests work around the clock, they update local copies of project repositories and check project files, both in the background and at user requests. Most tests perform static analysis of localization files (that is, they do not simulate any product or test environment) based on regular expressions, whitelists, predefined rules and heuristics.
Most tests check any file passed to them, but there are also tests that contain specific checks that only apply to specific types of resources (online help, agreements, etc.). Upon completion of the checks, the system generates a report available to users on the service portal. It is important to note that autotests do not make any changes to the files – they only indicate errors, after which the localization engineer needs to make changes to the necessary lines of the file himself or with the help of linguists. The team of engineers involved in autotest support periodically creates new tests, makes improvements to existing tests at the request of the teams, since from time to time new projects are added to the tests, the formats of glossaries and other external data sources change, which can lead to false positives or, conversely, , missing errors.

What errors can autotests catch? For example, missing tags in html files, punctuation errors, inconsistency with the glossary, typos in product names, correct spelling of copyrights, incorrect text formatting, and others.
In the mobile team, automated tests are mainly used to check legal agreements, which allows you to quickly find and correct errors. This is very important, since final agreements come to localization on the eve of release, and saving time is a particularly important issue.
HashID
One of the most time-consuming tasks in localization is to ensure that the names of interface elements in the documentation exactly match the program interface. This is an important task, because if the names of GUI elements in the help differ from the names in the application, this significantly degrades the user experience. It is irrational to check all names manually due to tight deadlines, numerous localization languages and large volumes of documentation. Therefore, instead of checking GUI elements after translation, we came up with the idea of substituting them directly from GUI files and for this we introduced HashID – unique identifiers of interface elements.
HashIDs are formed from two parts: the file name in the Smartcat project and the internal string identifier in this file. We connect them using the separator “|” and we get, for example, strings.xml#master.xml| str_license_title. But it’s inconvenient to use identifiers in this form: they turn out to be cumbersome, which increases the likelihood of errors when copy-pasting. Then we can calculate the MD5-hash from this string. We get: ca70549529adf14ec2b2733f12f743c9. Next, we encode it in base58 (unlike base64, this encoding does not contain ambiguous characters like 0 and O – this helps with manual input), we get: 7gwLirr8FcSEfTkLXg6j7hMp45biixPaTg5zdP8Rb7jn. Such an identifier is still very long, and, in fact, this length is redundant. If we reduce it to the last 6 characters, we get 586 =38 billion unique combinations. On a project of 20 thousand lines, the probability of a collision is less than 0.5%. So, HashID is formed from the last 6 characters of the MD5 hash, previously encoded in base58.
For convenience, all identifiers are enclosed in paired square brackets [[]]. This “tag” is rarely used and looks more or less compact. You need to indicate both the beginning and the end of the name, for example:
In the Settings section, enable Kill Switch. ->
In the [[MNGyRqjR]]Settings[[]] section, enable [[RirfPA5g]]Kill Switch[[]].
Putting hashes in the documentation text is the task of a technical writer. To do this, you must first generate an XLSX table with GUI elements and their hashes exported from the desired project in Smartcat. The table looks like this:
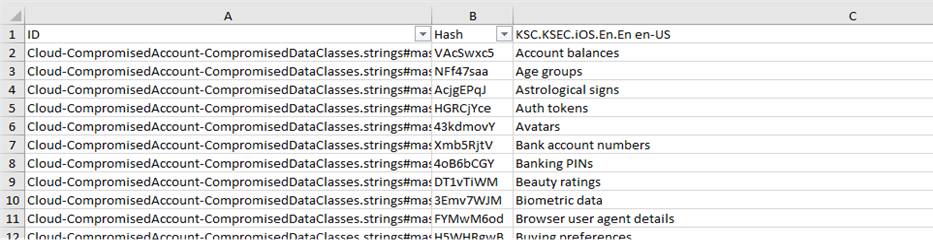
Next, you need to add to each GUI element in the help topics in AuthorIT its HashID, taken from the second column in the table. The texts of GUI elements are in the third column, the first column (full identifier) helps to find the correct string when there are several matching or similar options.
After substituting the HashID, the writer exports the help to html format and sends it to localizers. The exported help will contain hashes enclosed in double square brackets (as in the example above). You cannot submit it in this form for translation: identifiers in square brackets will look like ordinary words to the translator, this will create additional fuzzy matches and, as a result, extra work. To avoid this, you can convert the tag format from square brackets to HTML … tags:
In the Settings section, enable Kill Switch.
tags are not visible in the browser, but SmartCat recognizes them and escapes them so that the translator cannot change them. This is what the main screen of the utility in which we work with identifiers looks like:

Having received translations of documentation, the localizer must substitute translations from the GUI instead of hashes. To do this, he selects all the languages he needs, connects the corresponding project from Smartcat and selects the option Replace tags in html in the utility. The hash replacement process takes a few minutes, after which the certificate is sent for publication.
Thus, using HashID significantly simplifies and speeds up the process of working on help, and also reduces to zero the likelihood of errors or inconsistencies in references to GUI elements.
ScreenshotLab
One of the important stages of localization is checking translated texts on screenshots in order to identify and correct possible cosmetic and linguistic bugs. To automate this process, we created a special utility called ScreenshotLab. It performs two main functions: creating a package to send to a linguist for testing (comparing Source <-> Target screenshots) and adding bugs to screenshots.
Having received screenshots in all the required languages using “Autoscreenshot” (another program that automatically takes screenshots of applications according to specified parameters), the localizer creates special packages for testing. The package is a file in the *.klscreen format, in which English and localized screenshots are compared in pairs in one window.

Since there can be a lot of languages and folders with screenshots within a single task, creating such packages manually would be difficult. To facilitate this step, another utility is used, which is installed in the Explorer context menu and allows you to create all packages for all folders with languages with one click: for this it is only necessary that the names for the same screenshot and the folder structure be the same for all languages ( this is the case by default).
Finished packages are sent to linguists for verification. The reviewer must mark each screenshot as correct or faulty. The list of processed screenshots looks like this:

If a bug is found in the screenshot, the testing linguist needs to describe the problem and offer a solution. Next, the localizer, taking into account the features of the product, the structure of the string format (including variables, placeholders, reuse of strings in other projects, etc.) and monitoring consistency, makes a decision on making the proposed amendment. To make it easier for the localizer to process the result, special fields are set in the comment writing window:
Actual result/Current result: line from the screenshot in which the bug was discovered;
Expected result/Suggested translation: correct translation for the same string, offered by the vendor;
Source text: same line in English.

So, ScreenshotLab allows you to significantly optimize the process of linguistic testing and ensures the convenience of creating and processing bugs.
Terminarium
Terminarium is a solution that helps us maintain consistent terminology across different company projects and across different platforms. The service consists of the following components:
Database — This is where all the concepts and terms are stored. Each concept and each term has a unique identification number (ID), so it is impossible to mix them up.
Web interface — used to add concepts and terms to the Terminarium database. You can also export term sets in it to an external xlsx file and, if necessary, import it back.
API — services that duplicate the functions of the web portal, which can be used by any employee of the docking station.
Plugins — they can be used for offline integration with CAT tools such as Passolo or Trados.
Integrations — logical connectors that allow, on the contrary, the use of external APIs. Currently there is integration with Smartkat.

To understand the structure of the Terminarium and the features of working with it, it is important to introduce the following concepts:
Concept – A domain-specific concept that appears in written company materials, such as graphical interfaces, user and administrator guides, or release notes. These include, for example, the names of applications and services, application features, general IT terms, etc. Such concepts are entered into the system in the form of clear definitions in English.
Term is a word or phrase used to express a concept. In many cases, a concept can be expressed using only one term. For example, for the concept “Name of the Kaspersky Lab website for managing devices and licenses” there can only be one term – “My Kaspersky”. Some concepts may have more than one term. For example, the term “Application Full Name” may vary between projects.
Functional area concept indicates the area in which this concept and related terms can be found. For example, a functional area could be “Licensing”, “GUI”, or “Update”.
Project@Platform@Version (abbreviated as PPV) is a hierarchy used to organize the structure of a project. For example, there is a Kaspersky Password Manager project. Within this project there are platforms macOS, Windows, Android, etc. Within each of these platforms there is its own versioning, where the terms may also differ. This structure allows for flexible versioning of project terms, similar to “branches” in a version control system.
Version main contains the most current terminology for the project and platform.
Platform Shared — a list of terms relevant for all platforms of this product. Since most of the terminology within a single project consists of terms that are relevant across all platforms (this could be the names of functionality or product licensing options), if you add such terms to the glossary of each platform, there is a possibility that over time they may become out of sync. Shared helps avoid this and makes the task of maintaining terminology more convenient.
Forbidden terms — a separate section with a list of terminology that is prohibited for use in the company’s products in accordance with generally accepted principles of politeness and morality.
Status — the current state of the term. For example, status Approved means that the term is approved and can be used in the product, and the status Obsolete assigned to obsolete terms.
The Terminarium contains not only a definition of the term in English, but also approved translations into all localization languages.

Thanks to integration with Smartkat, freelancers working on translations for our tasks can see all the terms that are present in the string and that need to be translated in a certain way. At the stage of linguistic testing, a check for compliance with the glossary also occurs: for this, in addition to sending the screenshots themselves, the localizer also assigns the Smartcat project to the translator, in which the terminology is connected as a thermal base.
What's next
We continue to actively improve the functionality of existing tools and plan to introduce new ones. Among our immediate plans is the development of a pipeline to automate the processing of user feedback on documentation. Our users from different countries regularly provide feedback on the online help for our products, and it is very important to promptly identify problem areas in the help and send information to the product team. We are already actively working on MVP, using modern data analysis methods, in particular NLP technologies.
And other teams within Doc&Loc have their own developments, which we periodically borrow and customize for our projects. For example, we plan to implement a utility for collecting statistics on screenshot runs, filtering screenshots and recognizing text on them, which is already actively used on Mac projects. This will help us further optimize the linguistic testing process.
By the way, you can also master new tools and integrate them into our work: come to us to the documentation and localization department (Doc&Loc) Kaspersky Lab. You can work with us on localization into a record 34 languages and use all the tools that I described, and if you wish, create your own 🙂





