Aggregates in the database – proxy tables
We conclude a mini-series on working with aggregates in PostgreSQL:
why, how, and is it worth it?
efficient processing of the “facts” stream
multidimensional superaggregates
And today we’ll talk about how you can reduce total insert delays many changes to the aggregate tables through the use of staging tables and external processing.

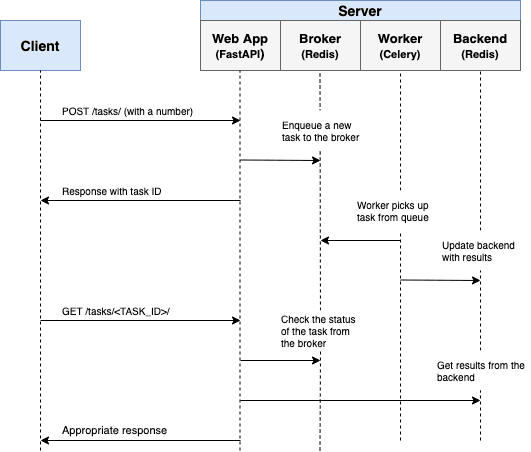
Let’s talk about this using the example of the collector of our PostgreSQL log analysis service, which I already talked about in previous articles:
We write in PostgreSQL on sublight: 1 host, 1 day, 1TB
Teleporting tons of data to PostgreSQL
From the point of view of further work with the table of aggregates, it is always beneficial after all have a single copy of the record in it, and not try to rewrite it many times, then we have options at our disposal intermediate in-memory aggregation process and separate rolling of changes…
If the first optimization is obvious enough (send to the base not “10 times +1”, but “1 time +10”), then the second is worth telling in more detail.
“Everything that has been acquired by overwork! ..”
So, we want to quickly see the statistics from which table / index how actively (and meaninglessly) they are reading. The picture should look like this:

Let’s see what exactly the time to insert a new instance of an aggregate record consists of.
I already said that we use the same for insertion into aggregates. COPYas in the “fact” tables + a trigger that converts the insert to INSERT ON CONFLICT ... DO UPDATE… We have significantly fewer aggregates than facts flying in them – that is, almost every insert leads to UPDATE! And what is it “technically” with us? ..
overlay RowExclusiveLock
find by index and subtract current recording image
write the service field xmax in him
insert a new recording image with modified data in WAL file and heap tables
we write the changes into all related indexes – if you’re lucky, there will be a HOT update with a little less load
Somehow a lot of “read” and “write” turns out. And in a second, the next one will arrive at the active unit UPDATE, and the next …
Create a proxy table
But it would be nice if it could be inserted immediately into such a plate – so that no indexes, no WAL files, no UPDATEs – only “clean” INSERT… But you can do that!
Let’s generate an intermediate table according to the target format:
CREATE UNLOGGED TABLE px$agg(
LIKE agg
);Why do you need UNLOGGED and what it gives you can read in detail in the article “DBA: We Arrange Synchronization and Imports Smartly”
Now all we want to record is we will write directly here without any triggers and indices…
Processing the proxy table
But now the data does not get into the target table in any way – it means that we need to entrust it to someone. Moreover, so that we do not have to solve any conflicts of parallelism, we will entrust this to someone alone, generally an outsider regarding data insertion.
In our architecture, the dispatcher-balancer described in the article “Dynamic load balancing in a pull-scheme” turned out to be just for this.
We can read all content every 10 seconds in the proxy table (yes it will Seq Scan, but this is the fastest way to access “all” table data), dynamically aggregate in memory of the PostgreSQL process without transferring to the client, and immediately insert into target table in one request.
If you don’t know how to combine the calculation of different aggregates in a single query, read “SQL HowTo: 1000 and One Aggregation Method”.
After we have read everything, aggregated and inserted, we will simply and quickly clean up the proxy using TRUNCATE:
BEGIN;
INSERT INTO agg
SELECT
pk1
...
, pkN
, <aggfunc>(val1) -- sum/min/max/...
, <aggfunc>(val2)
...
FROM
px$agg -- тот самый Seq Scan
GROUP BY -- агрегация в памяти в разрезе PK таблицы агрегатов = (pk1, ..., pkN)
pk1
...
, pkN;
TRUNCATE px$agg;
COMMIT;I will note that it is necessary do in one transaction, since you never know what errors can occur when inserting, and TRUNCATE outside of this transaction, everything will be cleaned up, and the data will be lost.
Parallel insertion protection
But the trouble is, while we were reading and aggregating, someone could write something else into the table. And we are clean up without processing…
Can of course be hung before starting LOCK on the entire table, so that no one can do anything with it for sure, but this is not our option – there will be too many inserts to wait.
But … we can almost instantly replace it with an empty one!
BEGIN;
SET LOCAL lock_timeout="100ms"; -- ждем блокировку не дольше 100мс
LOCK TABLE px$agg IN ACCESS EXCLUSIVE MODE; -- собственно, блокируем от всех
ALTER TABLE px$agg RENAME TO px$agg_swap; -- обменяли имена двух табличек
ALTER TABLE px$agg_ RENAME TO px$agg;
ALTER TABLE px$agg_swap RENAME TO px$agg_;
COMMIT;As soon as we wait for the lock, the renaming will take place. If we do not wait, then we will try next time, not scary.
In principle, you can do with two RENAME, but there should be more proxy tables:
px -> px0, px1 -> px
px -> px1, px0 -> px
The internal “mechanics” of the queue broker are similar. PgQ and replication based on it Londiste…
Proof
Now the most interesting thing is how much it all gave:
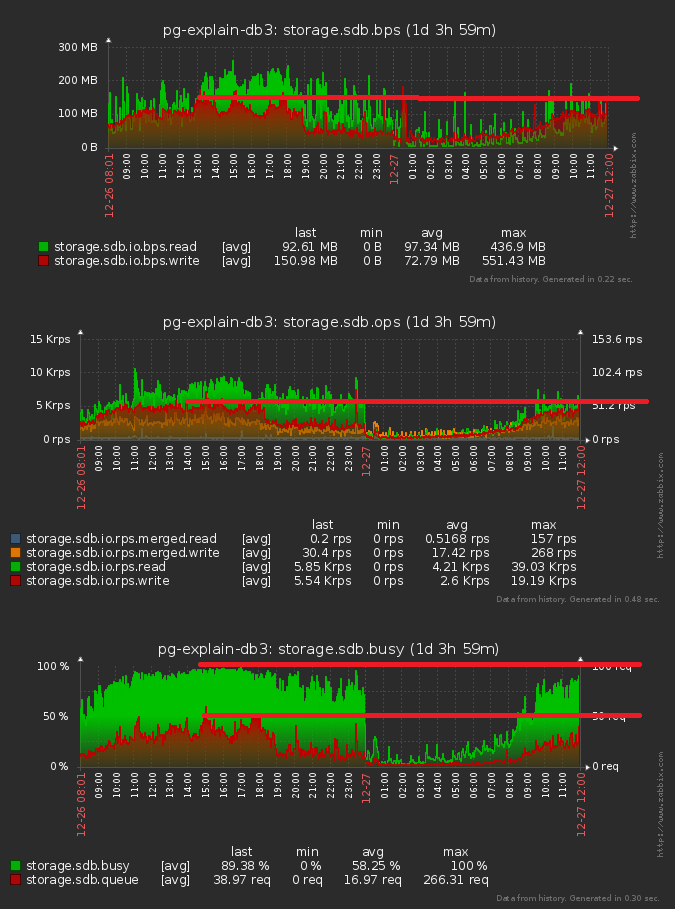
We got a decline by about 10% in terms of disk load, accelerated insertion into the aggregate table and got rid of waiting for locks on them.