Working with duplicates in the data management system “Unidata”

Duplicate handling is one of the most painful topics in an analyst’s work. In our platform, we try to automate this process as much as possible in order to reduce the load on the NSI experts and increase the productivity of colleagues with data processing. Today we will look at how the platform helps to form a single golden record using the example of one of the most common and basic reference books – the “counterparties” directory.
Let’s consider one of the typical scenarios. Suppose a large B2B distributor receives goods from different suppliers and sells them to clients – legal entity. persons. If in practice everything is more or less good with the maintenance by the supplier, then the processing of the client base sometimes requires a whole dedicated team of experts. This is due to the fact that usually companies use several systems-sources of customer data: ERP, CRM, open sources, etc. The work is especially difficult when there are several departments in the company, each of which maintains its own customer base within the same territory … In this case, part of the customer data is duplicated in the redistribution of one base, and also implicitly intersects between different customer bases. In an ERP system, serious processing of duplicate records is required to obtain a so-called master record, with which you can work in the future. The Unidata platform has a special mechanism for finding and processing duplicate records, which successfully copes with such tasks.
Let’s get started
The platform is based on the metamodel of the used domain. Domain is a structured set of registries, directories. their attributes and the relationships between them, which together describe the data structure of the domain. We’ll talk about the metamodel itself later, but now we’ll see how the platform allows you to work with duplicate records in an existing data model. In our example, there is a register of “counterparties”, where the main attributes are: the name of the counterparty (usually short and full), TIN, KPP, legal and actual addresses, address of registration of the legal entity, etc.
The platform uses a consolidation mechanism to handle duplicates. The essence of consolidation is that we set up certain rules for finding duplicates, define data sources and for each data source we set special weights that are responsible for the level of trust in the information received from the source system, and then the duplicates found by the system are merged into a single reference record. In this case, duplicate records disappear from the search results, but remain in the history of the reference record. All settings are made in the platform administrator interface and do not require programming. If the merging of records is done in error, then there is always the possibility to undo the merge. Thus, most of the work with duplicates is taken over by the system itself, the user can only control this process. Let’s consider the application of the consolidation mechanism on the cases of the indicated example.
Let’s say that the Unidata platform has been introduced into the company’s integration bus, which receives data on counterparties from the CRM system, ERP system and the mobile sales system. The platform removes duplicates, enriches and harmonizes the data, and then transfers the reference records to the receiving systems.
Case 1. Matching TIN and KPP
The easiest way to find duplicate counterparties is to compare them by TIN and KPP, in most cases even one TIN is enough. To implement such a rule for searching for duplicate records, it is enough to set up an exact match rule for the INN and KPP attributes.
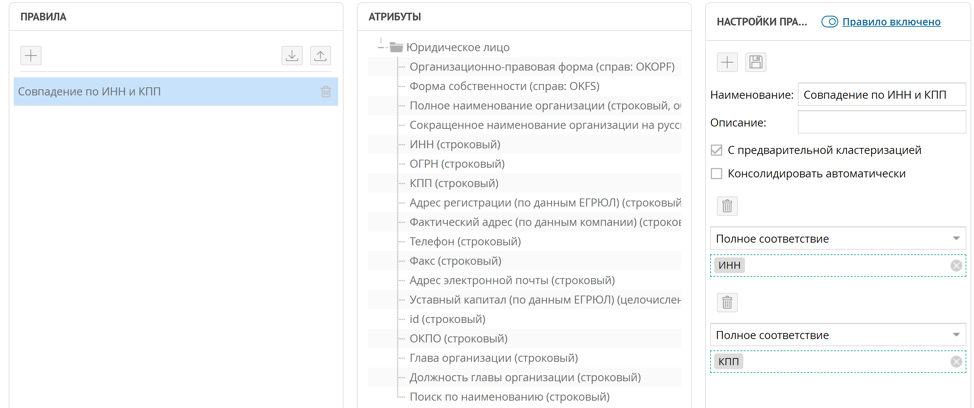
According to this rule, when a new record arrives in the platform, the configured duplicate search rule is automatically launched if the rule is set to “pre-clustering”. All found tuples of records by coincidence of INN and KPP are collected in duplicate clusters. In the duplicate cluster window, Unidata allows you to create a master record from duplicate records.
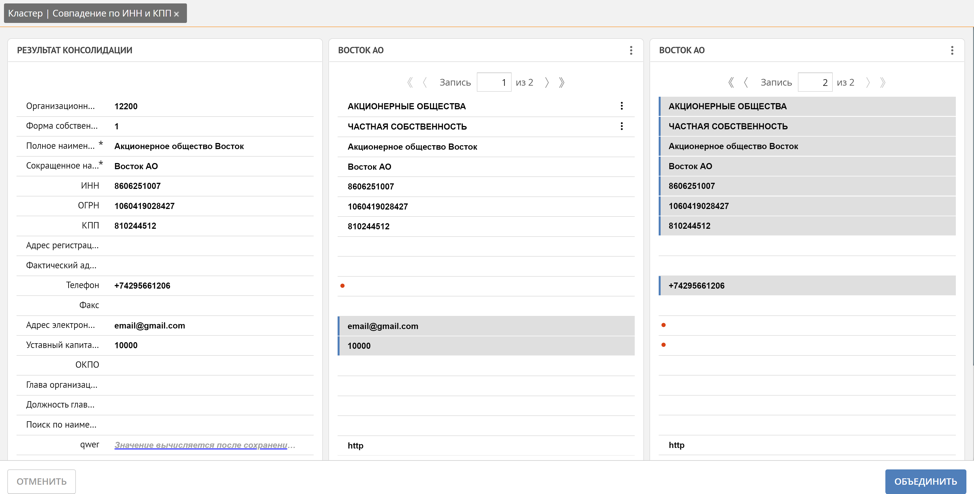
Here the user can manually track which record automatically becomes the reference and, if necessary, correct it by manually marking the values of the attributes of the duplicate records that should be included in the reference record, or by marking the entire record. Additionally, Unidata supports a mechanism for enriching missing values based on similar records. For example, telephone, mail and share capital were automatically obtained from 2 different duplicate records.
As we have already noted, the platform, when forming a cluster of duplicates, automatically determines how the reference record will be formed. This is due to the previously mentioned trust weights of the source systems. The higher the weight of the system where the record came from, the more significant the values of its attributes are for the reference record. But often there are situations when the values of certain attributes for a certain source system should prevail over all others, for example, we trust the actual delivery address of the client most of all to the agent who directly negotiates on the client’s territory and knows the address exactly, which means in our example mobile sales system. To solve such problems, the platform has the ability to set weights not only for data sources, but also for record attributes in the context of each data source. This combination of weights allows you to flexibly configure the rules for generating a reference record.

Case 2. Fuzzy correspondence by the name of the legal entity
Although the TIN is a mandatory attribute, let us assume that the information on the client has not been updated for a long time, he has changed his organizational and legal form. In this case, an entry with a different TIN will already come to the platform and the TIN match will not work. In this case, the platform allows you to form a fuzzy match rule by the value of the attributes, in this case by the name of the legal entity.

Fuzzy search does not have preliminary clustering, since this operation is quite resource-intensive, which means that this rule will not work immediately when a new record is added. To start fuzzy search rules, a special operation of finding duplicates is used, which is started manually by the administrator or by the system on a schedule. After the duplicates are found, the formed clusters can be viewed in a special section of the data operator interface.
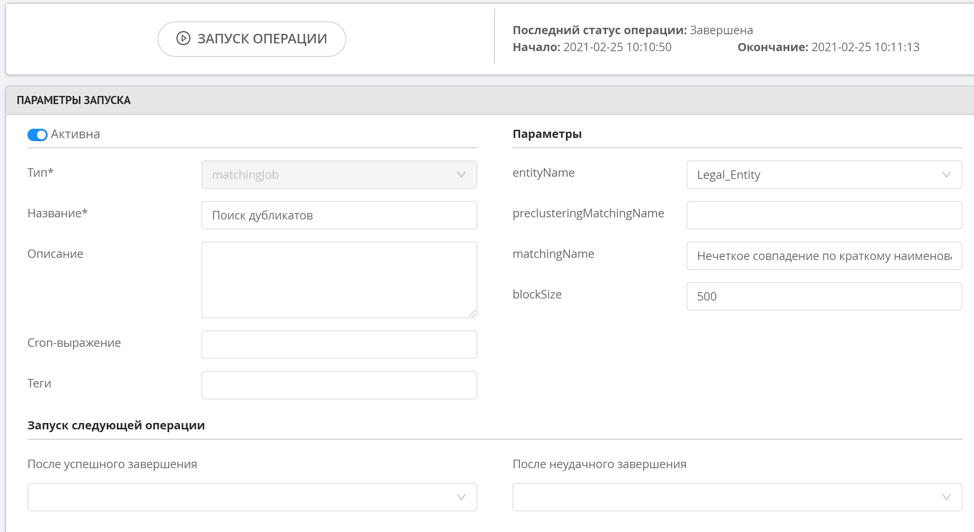

Fuzzy duplicate search works in such a way that we determine similar string values that differ by 1-2 characters or require no more than two permutations (Levenshtein distance), there is also the possibility of searching by n-grams. This approach allows you to find similar records with high accuracy, while not loading resources for calculating all possible string manipulations if the strings are very different from each other.
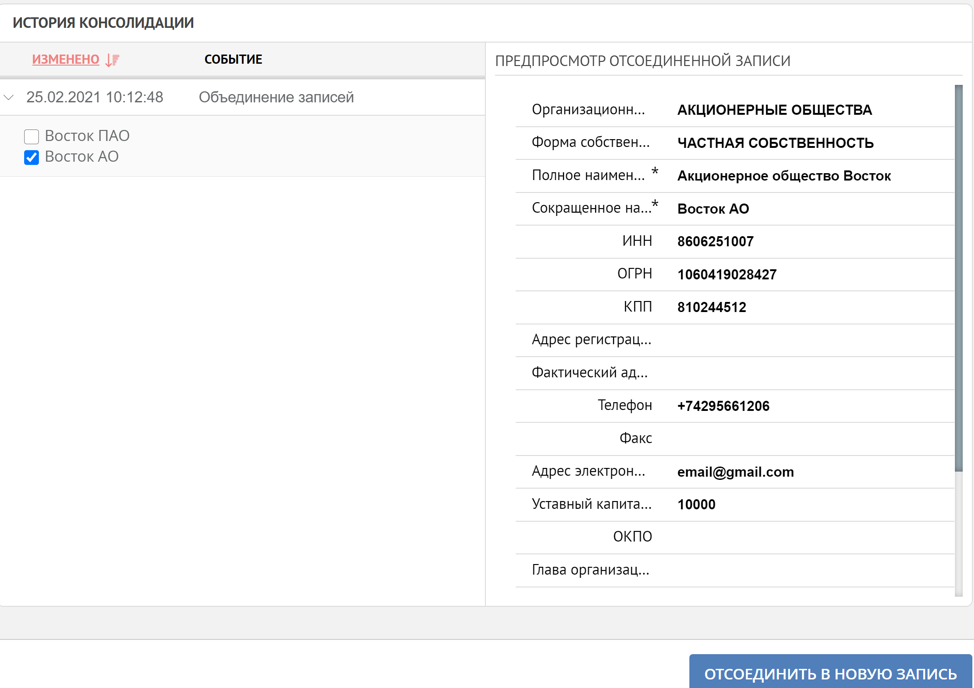
Thus, we have demonstrated in simple typical cases the principles of the platform when working with duplicate records. Duplicate processing can be performed either completely under user control or automatically. If the consolidation of data has occurred by mistake, then, as mentioned at the beginning, the system always has the opportunity to view the history of the formation of the reference record and, if necessary, start the reverse process.
We do not stop there, we research new algorithms and approaches when working with duplicates, we strive to ensure the maximum data quality in a variety of enterprise systems.





