What to do to prevent exploitation from turning into endless firefighting

My name is Vladimir Medin, I work in the SberWorks division, which implements DevOps and MLOps practices. I would like to share our experience in increasing the reliability of enterprise systems put into operation, especially for the first time. For some, this article will be more of a lifeline, but with parting words. Many approaches to ensuring reliability are regulated in our country, but there are also “non-statutory” solutions that are developed only with experience. Some may not understand some of the subtleties dictated by the conditions of a large company, so as the story progresses I will explain why this is important. However, in my opinion, these rules are applicable in the work of a company of any size that values the stability of the quality of its services.
Is production necessary?
At Sberbank, putting any system into operation means allocating some budget and equipment, and holding special events to confirm the quality of the product. Therefore, first of all, we get used to answering the question: “Is this product necessary at all?” But why did it arise at all?
First we must define the service type. This influences the choice of conveyor for quality testing. The service can be internal, that is, both it and its consumers are located inside the corporate network:
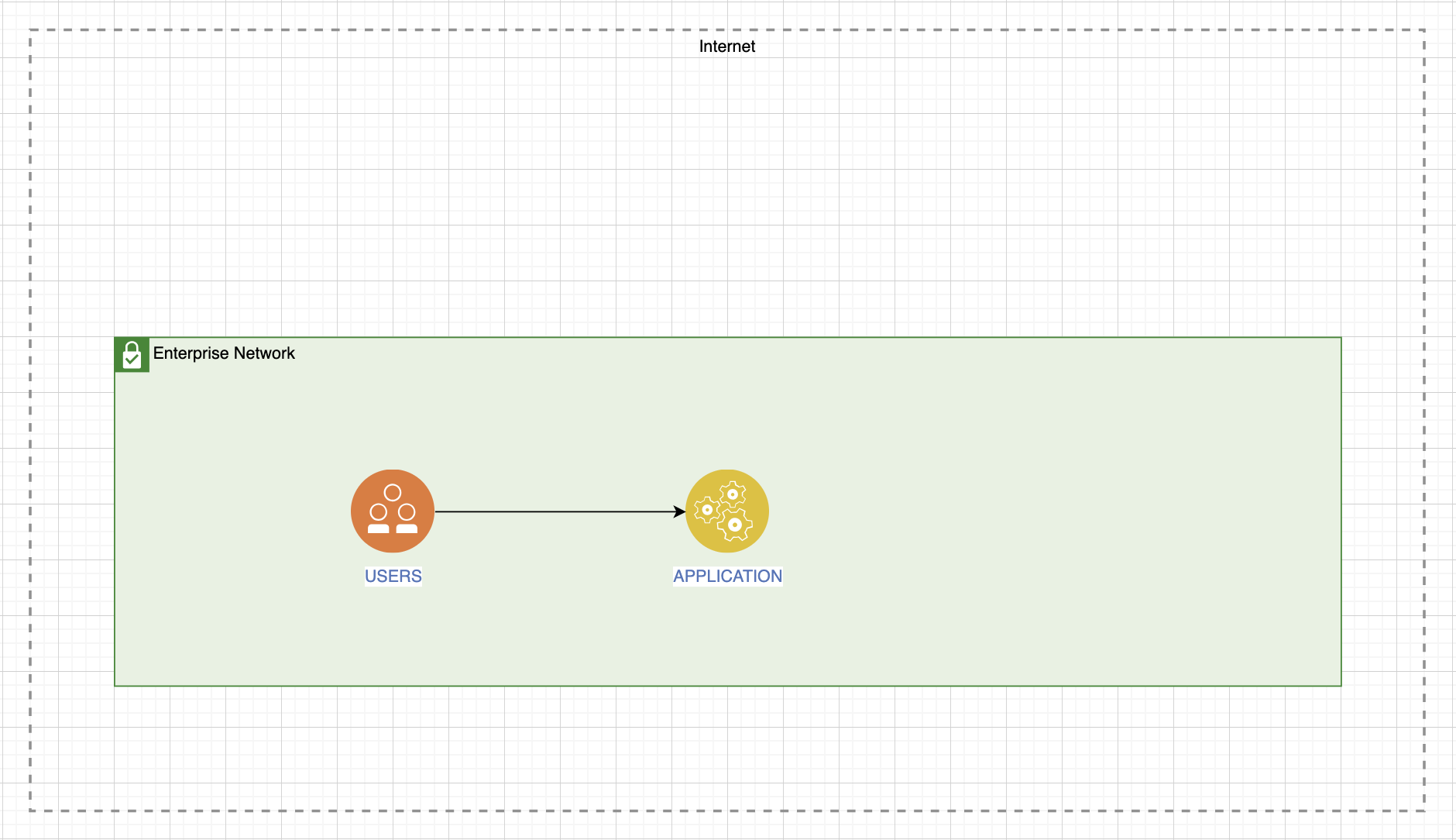
The service can be presented as a service for external users, but at the same time located within our perimeter:
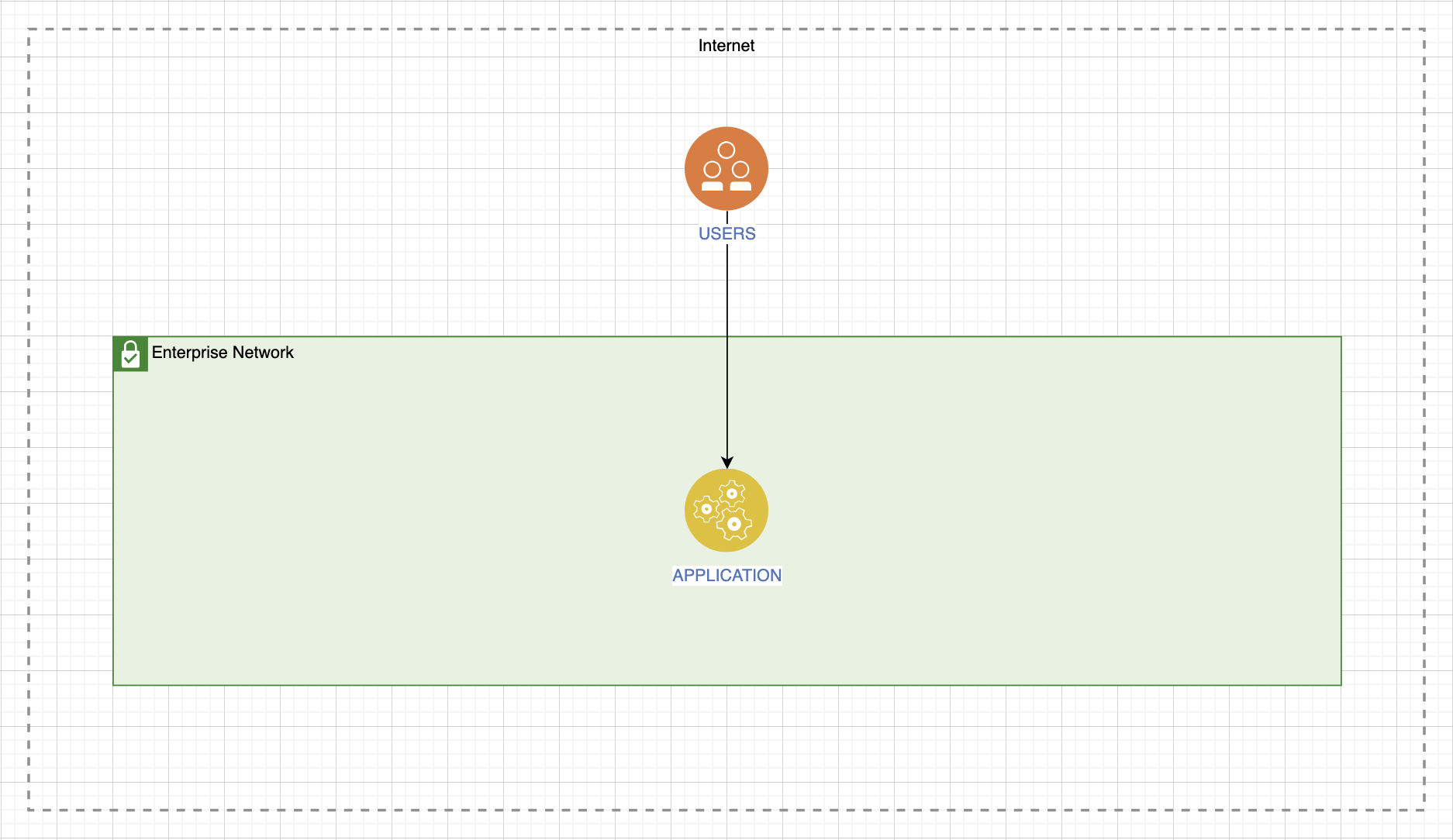
Or it can be completely external:

Then you need to understand what the consequences will be if each type of service fails. I have collected all three options in one illustration:

In some cases, a drop in service is not at all critical. Let's say, if this is a greeting card generator within our organization, then no one will be very offended if it sits for a while. And if this service helps you earn money and brings profit, then such losses will not be forgiven. Between these extremes there are services whose inoperability is unpleasant, but not critical; you can wait.
What kind of products do we need?
Having decided on the type of service, we understand how to build our pipelines in order to begin development and complete everything with commissioning, and we know about the possible consequences. Let's look at the whole process using the example of a service with the highest possible requirements.
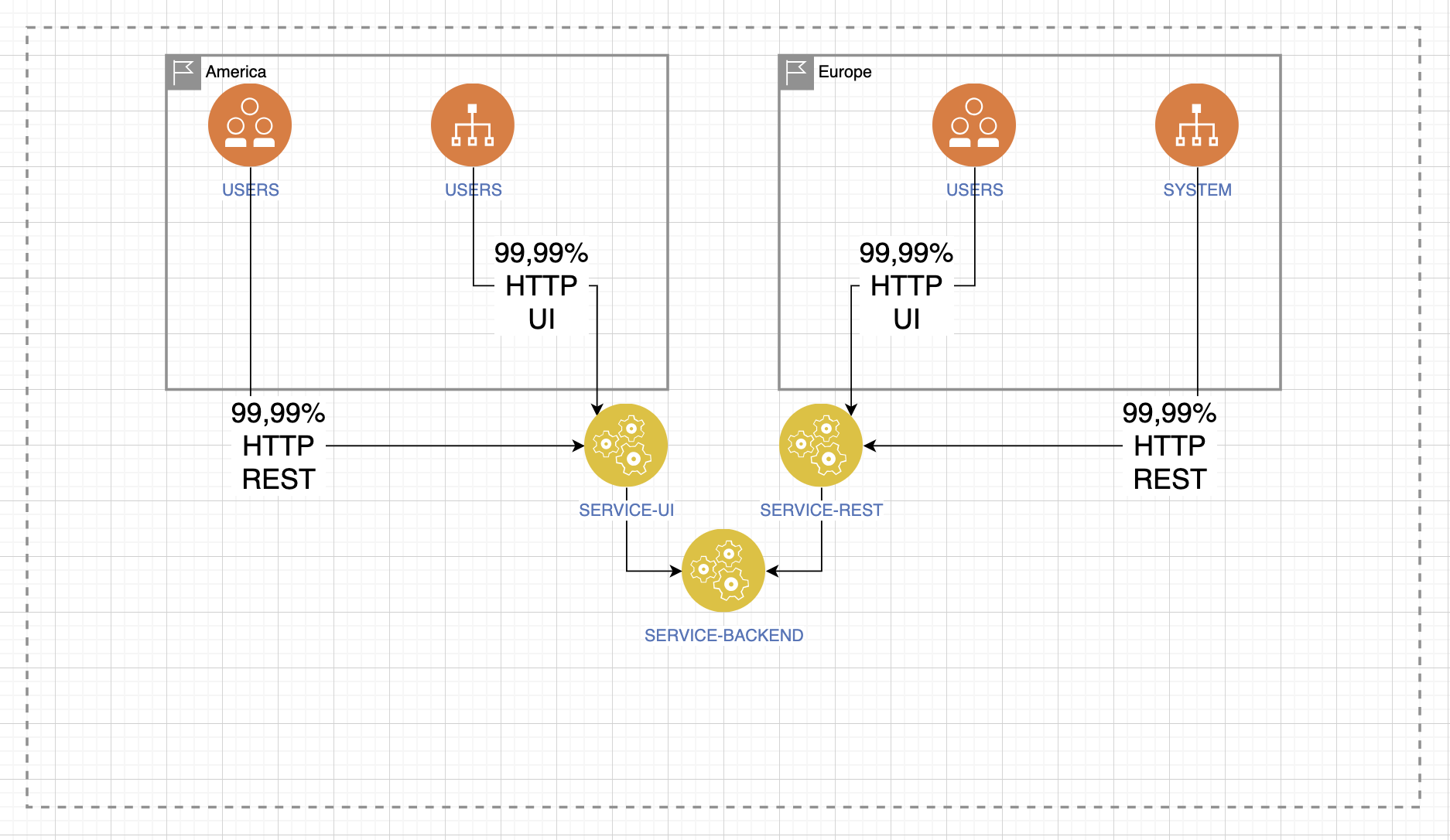
First you need to determine your target availability level. Let's move from simple circuit diagrams to more complex ones, so that as the story progresses I can explain how the situation can change when adding one or another argument.
We have users and an application that provides a service. His expected availability level is four nines. This is important because we already have to remember about geo-reservation, switching, placement in data centers and other mechanisms. We should already understand that everything will be serious. What technologies are used to operate this service? Let it be a regular web interface using the HTTP protocol.

But where are our users? And as soon as we come to this issue, the scheme immediately becomes more complicated: new endpoints are added, system integrations appear, and the use of a REST service. Because the diverse geography of not only our industrial environment, but also our users, will greatly influence how we deliver accessibility.

Then you need to answer the question: “monolith or not?” Building a pipeline from development to operation, to connecting all stages with a continuous process of delivering artifacts, quite strongly depends on the application architecture.
When it comes to going live soon, think about how it was designed and the environment. By environment I mean one or another reverse proxy, be it a load balancer, Nginx, HAProxy – it doesn’t matter what databases, cache or queue services we need to provide for the minimal launch of our application?

If you multiply all this by the number of environments, then the thought persistently arises that we definitely won’t control this with our hands.
Logging
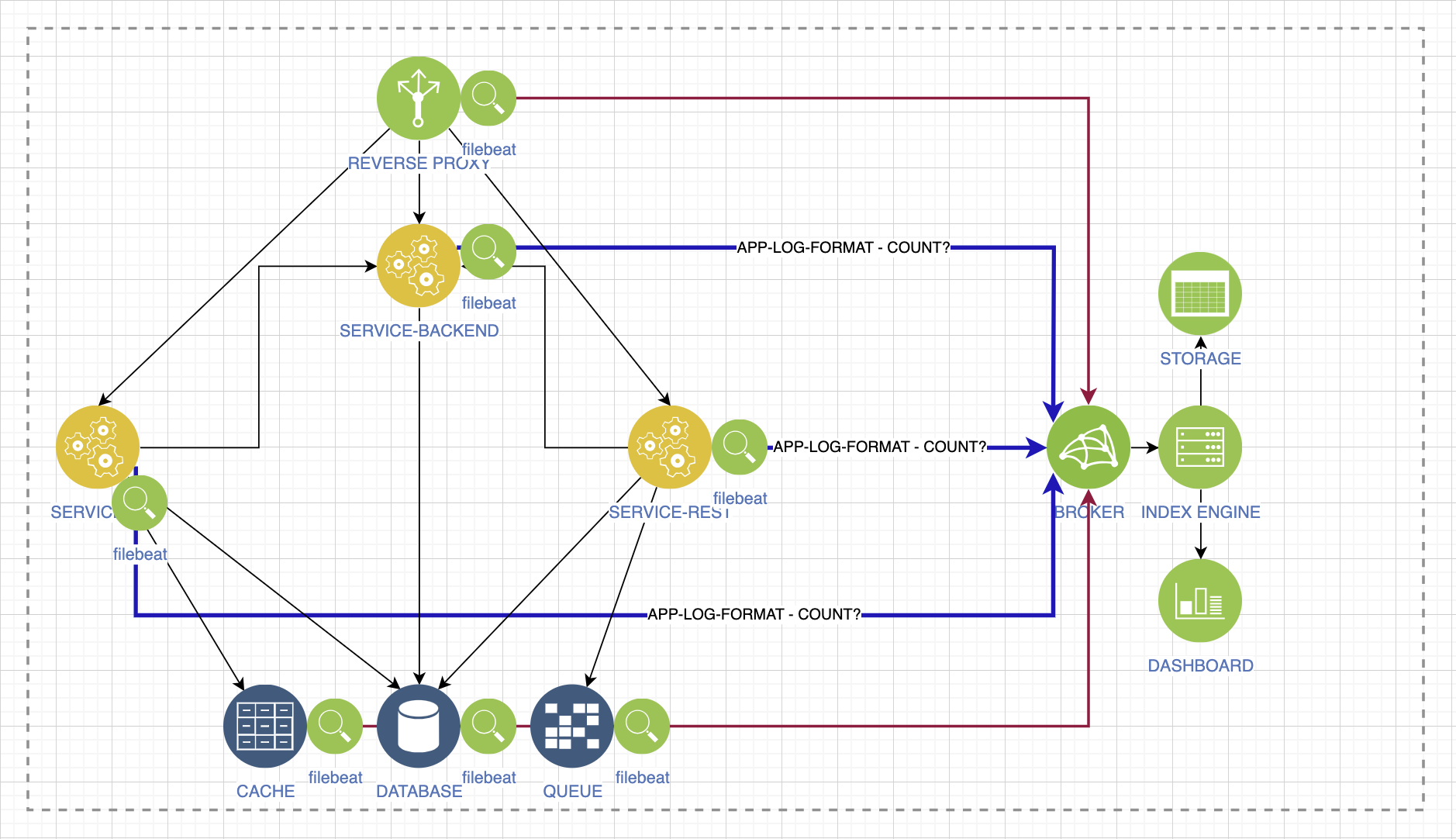
The next question we need to answer is: “what about logging?” Let's imagine a regular service with a microservice architecture. We have some kind of log aggregator, we have an environment.

Logs should not have different formats: log, frog, grog. Otherwise, it will be impossible to track critical incidents, degradation and other changes. Agree with the developers so that at the application level the logs are in the same format, with a common set of attributes. Some of these attributes are important to support lines, some are important to the developers themselves, and some are important to the business.

Ready for load
Any aggregation system should consume and process the same stream of logs as your services, if they are all connected to this system. If your service is a little more complicated than the simplest, then it’s bad manners to go to the consoles of virtual machines or pods to look at the logs. In a wild rush, you simply won’t notice the most important things. Therefore, check whether your aggregation system can process the entire log stream. Calculate the possible load, for example, with the help of system analysts.

Don’t forget that there are also logs of the environment that ensures the operation of your service. Everything that happens there must be qualitatively collected in one place and made available to all interested parties.

Repeatability
We recently added one of the utilities that collects logs, and we already see many elements that you need to be able to manage, and repeat this regardless of your stage.
The log aggregation system will grow, new services will appear, and manually you will not be able to ensure repeatability. Even if some stand was completely lost. Automate. The infrastructure-as-code approach allows you to repeat the environment, conveniently manage it and build something new, even test hypotheses.

What about monitoring?
Finally, I’ll tell you about the golden rules, each of which will have a lot of context. Determine the tools with which you will collect metrics. Here's a bad example where different levels are monitored by different systems:

You don't have to do that. Choose one system that will meet all your needs and collect everything in it.

Divide incoming data into metric tracking layers. Determine what you need for the service to work, which may affect the quality of the service provided. Collect all types of metrics. There are now excellent exporters for each type of environment, or you can develop them yourself if you have time. Here I tried to separate the standard levels that need to be monitored to monitor the health of our stack:

The first layer is the metrics of our proxy, which is the first to accept requests from our users. The second layer is the application layer; at least four golden signals provide us with transparency of behavior. We have environmental metrics: database, cache or queue. We have low-level metrics that reflect the platform our stack runs on. And dependent metrics. That is, in the process of work we can use Active Directory, external systems for storing secrets and other confidential information. All this is extremely important and will affect your work, even if it seems to you that these are iron-clad services. This is wrong.
Provide alerts from all levels you collect. Levels are also divided by importance. The most critical, for example, are notifications about a decrease in the quality of service.

Each type of alert should be provided to a different type of consumer. Some of these metrics are very important for business, some are important for the 24/7 duty shift, some are simply needed for notification, because we have some kind of change that is not critical, but cannot be ignored.
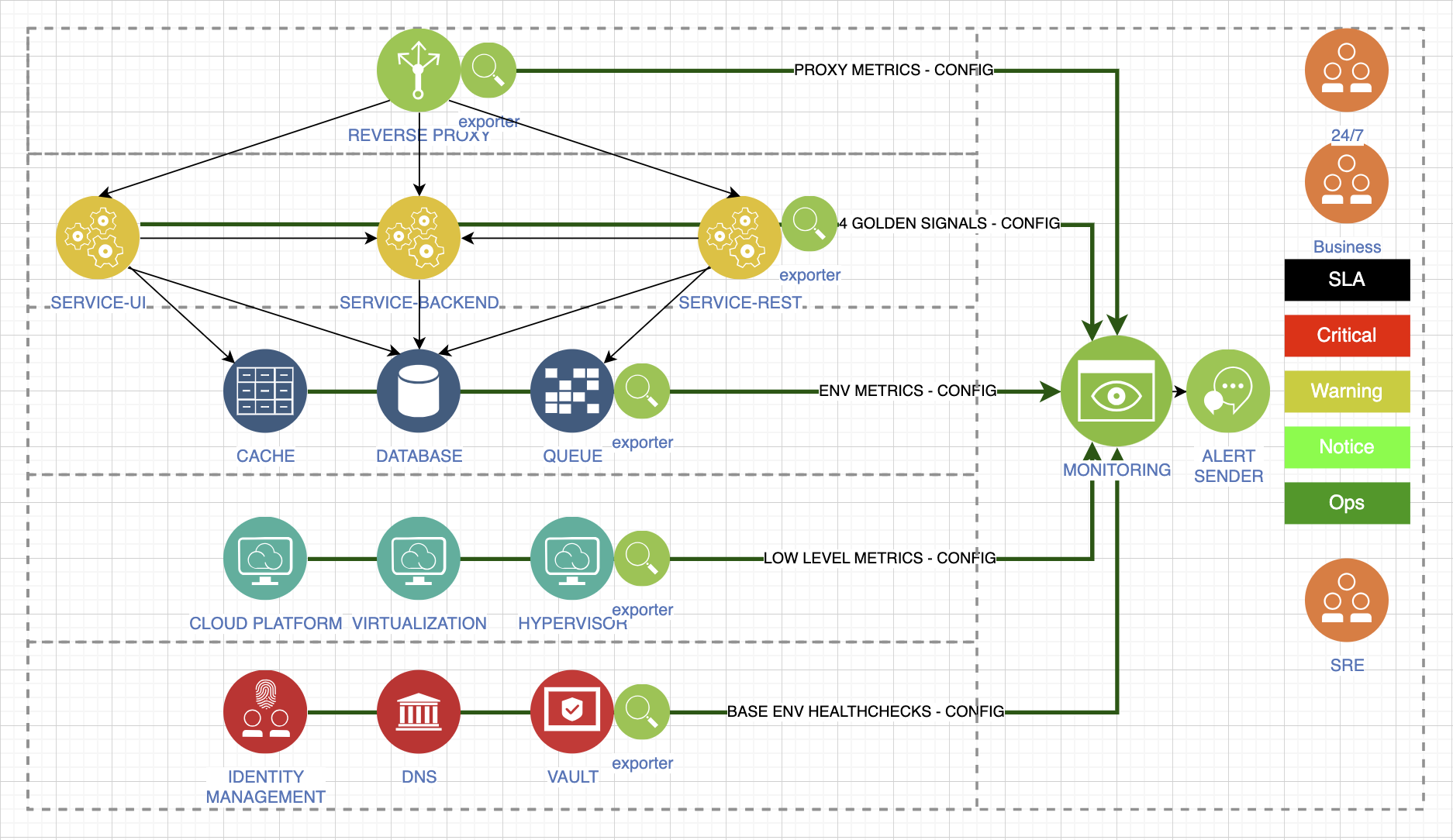
Manage alerts during scheduled work as well. There is no need to increase the amount of spam in a difficult situation, it can confuse you.

We again came from a simple scheme to a complex one, although we described the collection of metrics for only one type of environment: you need to maintain repeatability, automate it, use infrastructure configuration management practices as code. Having understood what service we need, we need to decide on technologies and monitoring.
But what is the expected load?
Without an answer to this question, even the previous tips may not help you much. Research your client. Determine the geography of the load, where it may come from. Let's look at the example of intercontinental interaction.
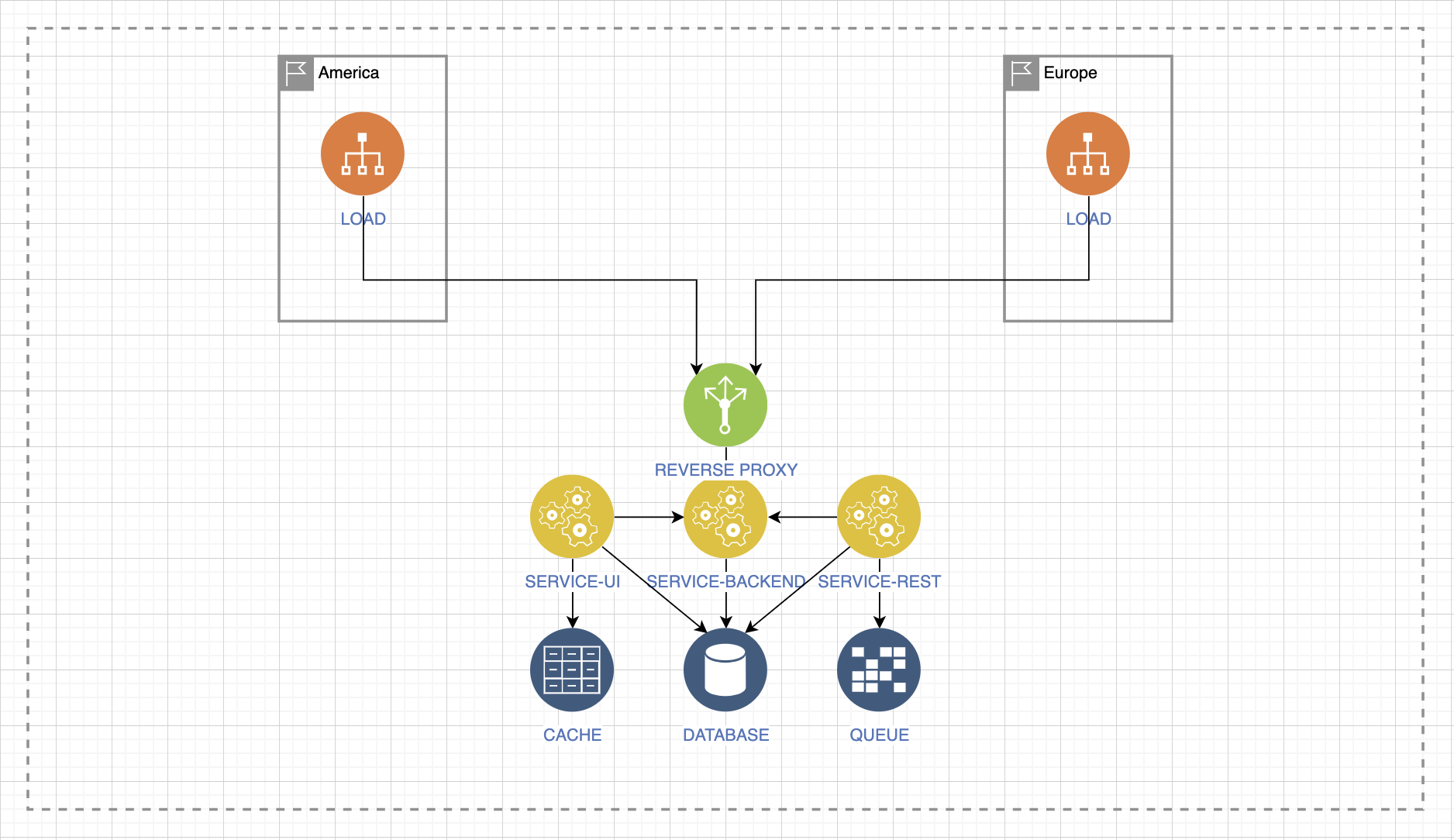
Let's say that mostly requests come to us from Europe, and they are the most important, and in America the most important answer is that our service gives. At the same time, the load from Europe only requests static information, and the load from America expects a quick response in JSON format.

Therefore, the load pressure changes its behavior and leads to a wave-like response within the system, already behind the balancing input point or behind the reverse proxy input point, be it an endpoint, a service or something else.

In this case, we see that under heavy load, requests for static information will put pressure on the cache, on backend services, and on the UI service. At the same time, other services will be idle.
There may also be another situation where a quick response in the form of JSON files, which can be large in size, is important.

Then there is pressure on other services. You must understand what will happen to your service when it receives different types of load.
Let's say there are two load flows from Europe and America. And there is a service that distributes the load between two data centers. This is the most practical option for balancing and providing fault tolerance at the mainland level.
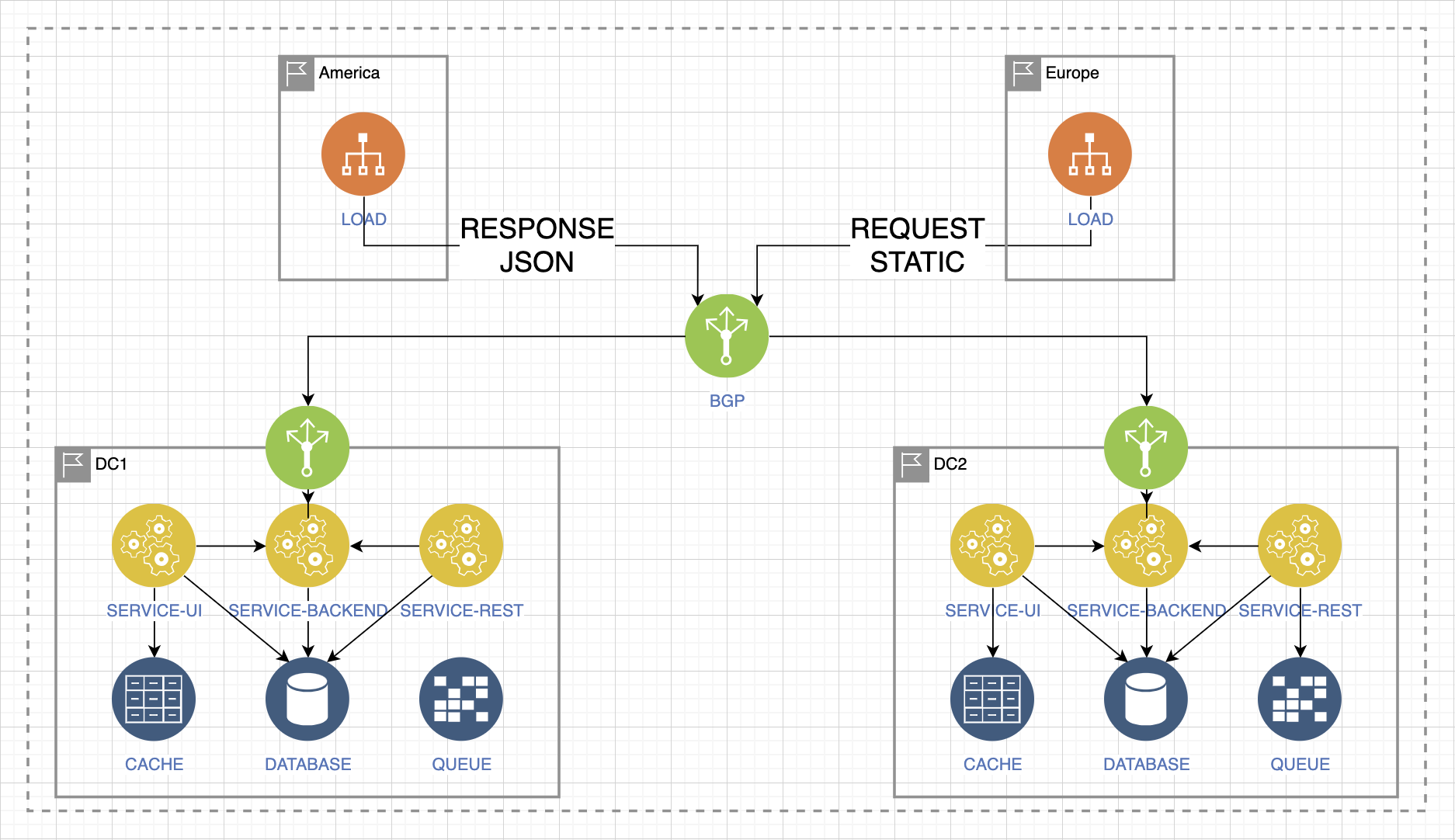
We have a controlled zone and an uncontrolled zone. An uncontrollable one is one that we cannot control. Controlled is the one where we can change the entire situation in case of unforeseen events.

Let’s say we lose access to data center 1 and the service for receiving requests drops:
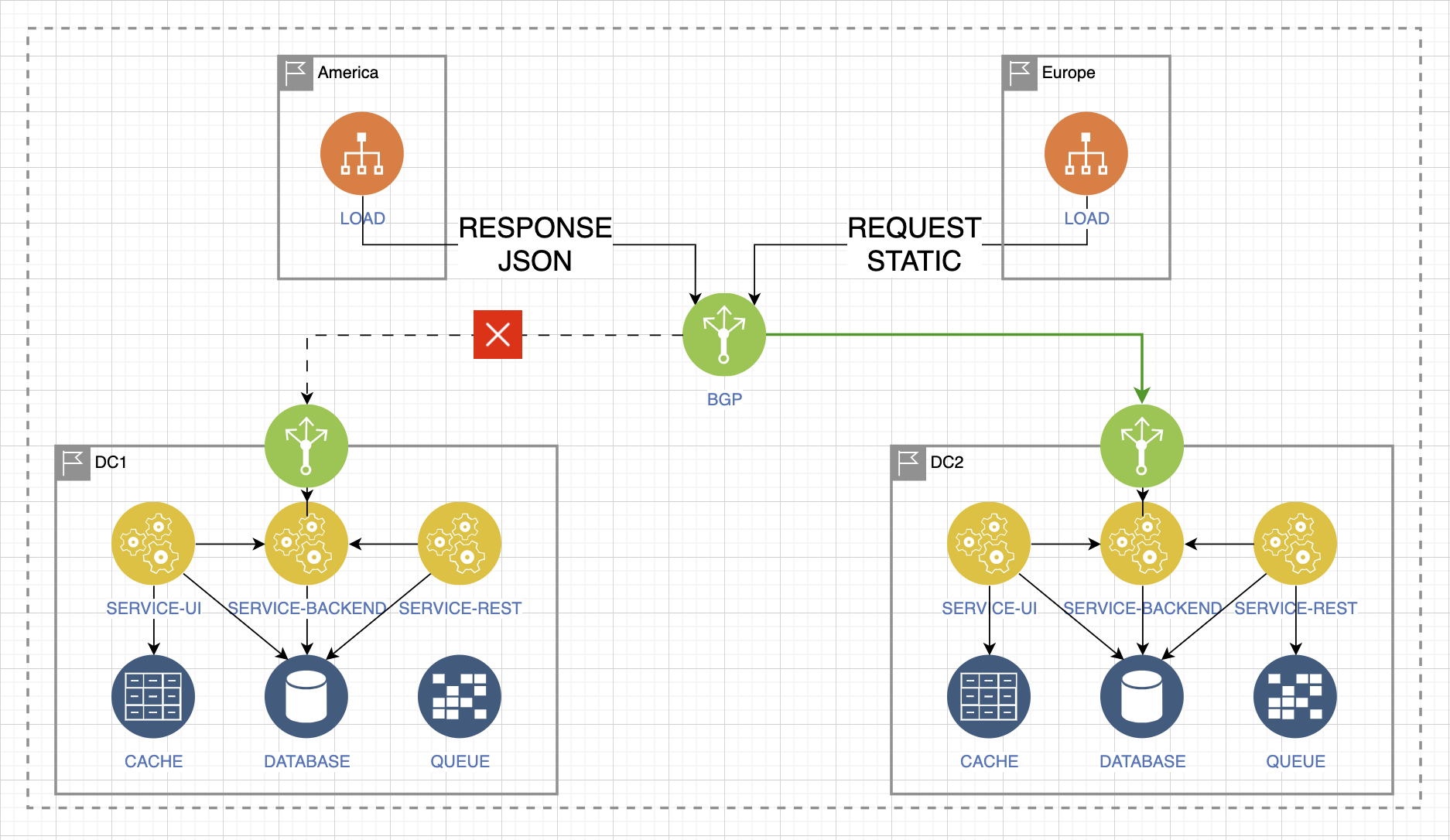
We need to make a quick decision and switch this traffic. It ends up in Data Center 2. At the same time, the database cannot withstand the increased load. We need to be able to quickly switch this traffic to the database in Data Center 1 via gray networks.

But at the same time, the traffic comes back, and due to the increased, atypical wave-like load in Data Center 1, the backend service breaks down. To maintain functionality, we need to quickly switch everything to Data Center 2 in this part of the integration.

But when the networks return and when all services become available again, our quorum may break down – the simplest example of a load and degradation scenario.

There is no need to do any full load testing or look for maximum points. Of course, this is very important, but it can take too much time to develop a methodology and study the consequences, although such scenarios can be put together by gathering with a team. So be prepared, immediately put these mechanisms in place and imagine how you will get out of such a situation. There are times when one problem leads to others, and something else happens at the same time. And without automation and rapid response tools, your entire operational environment could simply cascade down.
Manage your configuration. The controlled zone is much larger than the uncontrolled zone. Prepare scripts in advance, think about scripts, create a backlog, think about what scripts might be needed. Use all possible practices to avoid resorting to manual control.

Configuration management
I have spoken more than once about automation, management of distributed systems or operating environments without the use of hands. Let's talk about this. Let's imagine the simplest stack:

Now let’s multiply all services by a thousand. And then your current level of automation will immediately look different in your eyes:

The foundation of development is a standard cyclic picture: an engineer and a manual routine operation on a virtual machine.

This loop can run indefinitely. When something happens somewhere, the engineer will leave the point of balance and try to grab onto everything at once. And the priority of tasks can change quite often. Therefore, after successfully completing a manual operation, put the task in the backlog, sort it out and assign tasks to the team, transfer them to sprints, gradually executing and automating them. It’s not at all difficult to go into the IDE, write some script and put it into the version control system. It is not at all difficult to test this and deliver it to your environments, from test to production. Somewhere you think that automation will take too much time – skip them. First, accustom yourself to the endless process of setting tasks for yourself: “I did this manually, I must automate it.” You will free up your time and be able to further research and develop the system.

Decide on your tools. There is no need to use, for example, Ansible, Chef and Salt at the same time. Or Bitbucket, GitLab and SVN. This is all interesting and very tempting; it seems that this particular tool has what we always needed. But no, this zoo only leads to discord at the team level, and even at the level of the entire enterprise. Choose tools wisely and collaboratively.

Respect the code. Everything we automate is also code, just like the developers. You need to carry out checks and work with branches with the same attention. There is no starting point in this illustration because the process is endless:

Start this process as soon as you first need to deploy to a test environment. It will be much easier for you to get out before exploitation, and there will be much less technical debt. Automate testing and checking code cleanliness. Check your colleagues' code and correct them. Make automatic deliveries and monitor system behavior.
Deployment Management
I'll tell you about the main thing:
Define deployment mechanics. It could be blue/green, canary release, shadow copy or other mechanics – as long as it is the same for everyone. The zoo does not lead to anything good.
Automate smoke tests. This is the required final stage of deployment. Without it, you cannot guarantee that the changes were successful.
Consider the dependencies of running services. You cannot roll out an application without a working database, or roll out a cache without a working DNS service.
Imagine not having access to the console. This will give you the skill of working exclusively in code and teach you how to seamlessly build your pipelines.
SLA
From a business point of view, SLA is simple, but in reality everything is not so simple. To calculate the SLA, you need to do a lot of iterations and understand what exactly the final service is, what components work are responsible for the required level of service, and how to put it all into production.
For engineers, SLA is the best motivation for development.
Four nines is very difficult if you count correctly. Having deployed the system, we do not stop caring about its availability and reliability; this is constant work.
Parting words
Operation is a continuous and evolving process. If we launched some service and debugged it, this does not mean that our work ends. There are many practices and mechanisms that help us develop ourselves and develop the system. Feedback from support engineers should flow to developers and architects to grow their tool where the money is directly made.
Load is a constantly growing indicator, even for internal services. This is true for any company if the service is truly in demand, so plan for it.
Reliability has no higher limit. As I said before, achieving four nines is very difficult. Especially in a complex system, where there are a lot of different relationships and external integrations. Invest in it, study it. We've gotten to know the different tools and configurations well, but we still sometimes have to look into the hidden corners of the documentation.
DevOps is an integral part of production. Without the practices of this methodology, without automation, everything that Sber is currently achieving cannot happen.

![[Мастер-класс] Practical attacks on the USB interface](https://prog.world/wp-content/uploads/2020/04/iey9od_wrqnvtsrosaf5rkhx7ii-768x441.jpeg)



