RecTools – OpenSource library for recommendation systems
If you’ve ever worked with recommender systems, you know that all the necessary and most frequently used tools are scattered across different libraries. Moreover, each of these libraries has many unique features that need to be adjusted to (for example, different input data formats).
It turns out that just to test a basic pool of approaches on your problem, you need to suffer a lot. It turns out quite sad.
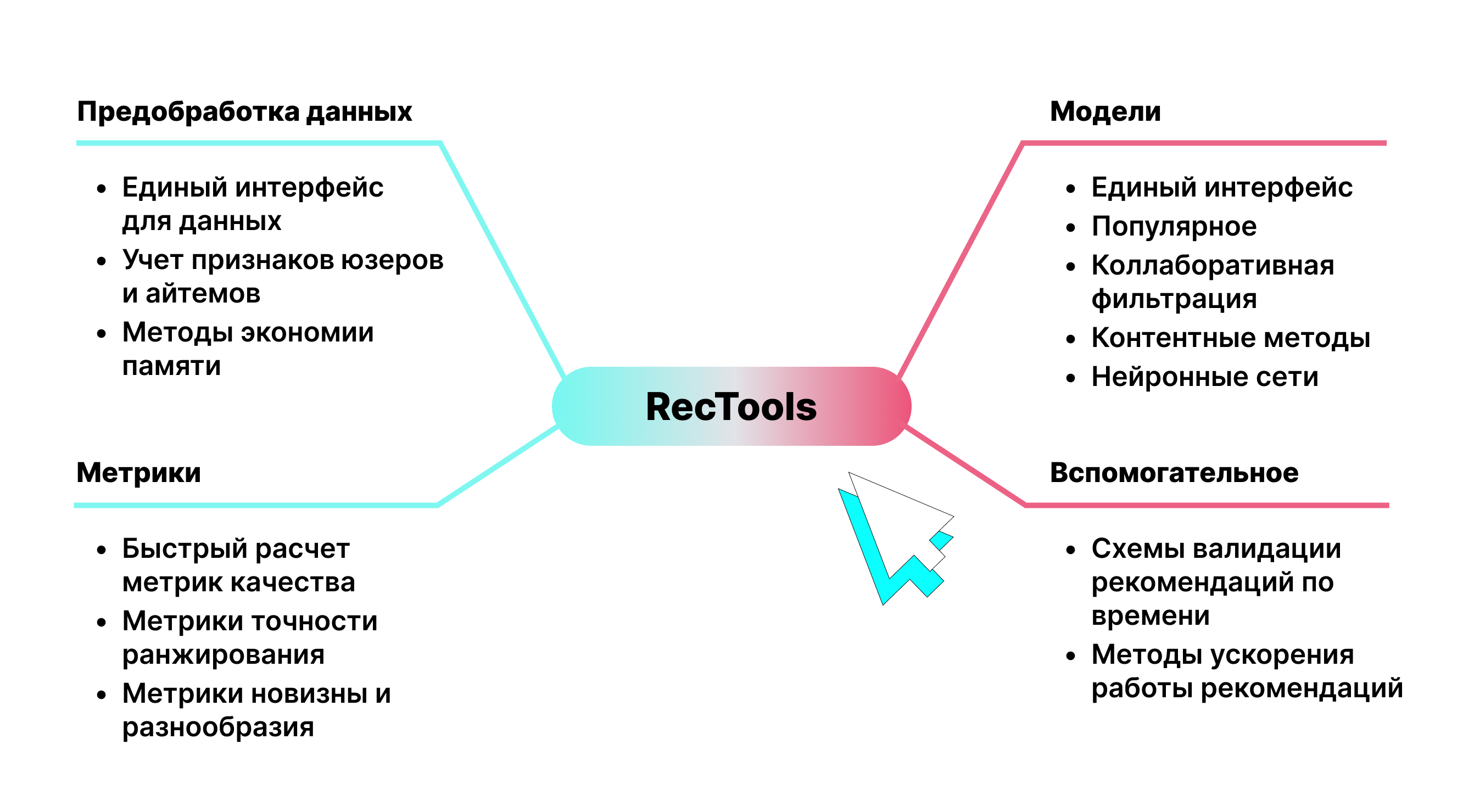
Apparently, the guys from MTS came to the same conclusion – and rolled out RecTools to the open source. This is a library containing the most commonly used models for recommendation systems. Also, with its help you can evaluate the necessary metrics as simply and quickly as possible.
Let’s see what RecTools can do and how to work with it.
Installation
No special effort is required here; we install it through the usual manager:
pip install rectoolsIn addition, you can install additional extensions:
LightFM: wrapper for the LightFM model
torch: models based on neural networks
nmslib: fast ANN recommendations
How to install the extension:
pip install rectools[extension-name]If you want to install all extensions at once:
pip install rectools[all]How to submit data
We have already mentioned that different libraries often require different input data formats. RecTools solves this problem too. Inside there is a container that aggregates everything that exists for the task. So we processed it once and applied it equally to all models.

In fact, the user is required to have a regular table, where each row reflects one interaction: in the first column is the user id, in the second – the item, and in the third – the speed of interaction (for example, bought/not bought). If you have time data, you can add that too.
Among the features: the column names are fixed. Therefore, the columns will need to be renamed using the class Columns. Then it’s just a matter of wrapping everything in Dataset and you’re done:
from rectools import Columns
ratings = pd.read_csv(
"ml-1m/ratings.dat",
sep="::",
engine="python",
header=None,
names=[Columns.User, Columns.Item, Columns.Weight, Columns.Datetime],
)
# Prepare a dataset to build a model
dataset = Dataset.construct(ratings)Library models
The library implements a single API for all well-known models: Implicit ItemKNN, ALS, SVD, Lightfm, DSSN, etc. That is, all the various mechanics of the tools are hidden under the hood, and the models themselves work out of the box – using uniform fit – recommend methods.
Model “popular”
This is the base. The algorithm works simply: based on the data, it draws conclusions about which products users most often interact with (watch or buy) and recommends them to everyone. Of course, the method does not have a particularly positive reputation, but it can be improved with a simple trick. It just needs to be recommended with some randomization. For example, each time take 10 random items from the top 100 most popular. It’s called reranking diversity.
It may seem that this is too naive. But in practice, this approach shows a stable statistically significant effect and is so strong that it often outperforms many popular models on AB, including ALS and LightFM. In addition, such recommendations are very cheap for businesses.
In short, if you are looking for where to start, start with the popular ones. In RecTools you can implement the model like this:
from rectools.models import PopularModel
# Fit model and generate recommendations for all users
model = PopularModel()
model.fit(dataset)
recos = model.recommend(
users=ratings[Columns.User].unique(),
dataset=dataset,
k=10,
filter_viewed=True,
)
Matrix decompositions
Matrix decompositions are such collaborative filtering methods. In short: it is predicting user actions based on the actions of other users with similar behavior. Let’s imagine that we have some user-item matrix. Rows are users, columns are items. At the intersection of the user and the item there is a number reflecting the interaction.
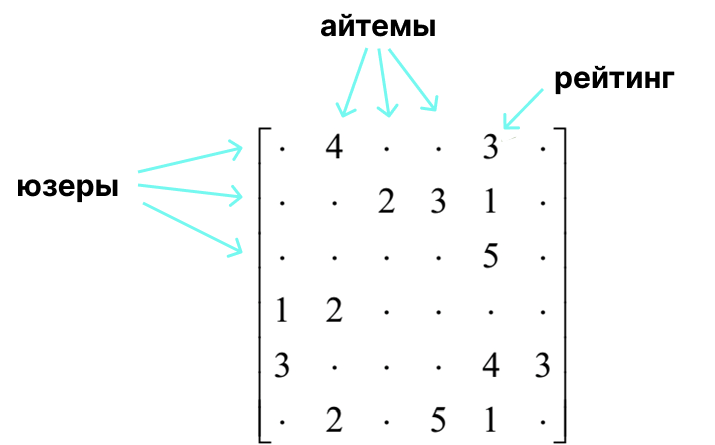
Based on such a matrix, we can describe user behavior and item characteristics. For this purpose, spectral decomposition methods are used. One of them is algebraic matrix decomposition, SVD (singular value decomposition). It is based on the decomposition of the original matrix into the product of 3 others:

Here U And S – matrices of user and item views, respectively. Using these matrices, we can then receive recommendations.
In RecTools this tool can be used using the class IPureSVDModel:
from rectools.models import PureSVDModel
# Fit model and generate recommendations for all users
model = PureSVDModel()
model.fit(dataset)
recos = model.recommend(
users=ratings[Columns.User].unique(),
dataset=dataset,
k=10,
filter_viewed=True,
)
The algorithm is quite transparent, but it has drawbacks. First, it is not interpretable, since predictions are made based on hidden representations. Secondly, the calculation of such expansions is very labor-intensive.
Therefore, in practice, ALS (alternating least squares) is more often used – this is a heuristic approximate algorithm for decomposing matrices. As a result, we again receive embeddings of users and items, with the help of which we make recommendations.
Using this algorithm from the RecTools magic box is a little different from the previous algorithms. Since this implementation is just a wrapper for the implicit model, the class object needs to be supplied as input Base model (more details here), inside which you can already specify the necessary parameters, like this:
from rectools.models import ImplicitALSWrapperModel
from implicit.als import AlternatingLeastSquares
model = ImplicitALSWrapperModel(
AlternatingLeastSquares(
factors=64,
regularization=0.01,
alpha=1,
random_state=2023,
use_gpu=False,
iterations=15))Training and receiving recommendations themselves does not change – for this, as before, you can use methods fit And recommend.
Implicit KNN
In addition to the wrapper for the ALS model from the implicit library, RecTools also provides a wrapper for the item-to-item KNN recommender model from the same library. The essence is this: we search in the matrix using the nearest neighbors method for people similar to our user, and average their ratings of the item – we get a rating for the target user.
from rectools.models import ImplicitItemKNNWrapperModel
from implicit.nearest_neighbours import TFIDFRecommender
model = ImplicitItemKNNWrapperModel(
model=TFIDFRecommender(K=5)
)
model.fit(dataset)As you can see, you also need to put the base model inside. In the code above it is TFIDFRecommenderbut in fact this time we have several candidates for this role, depending on the distance by which the similarity will be measured in the nearest neighbors algorithm: CosineRecommender, TFIDFRecommender or BM25Recommender. You can read more about the difference between them Here.
LightFM
This is a hybrid matrix factorization model, which also works well for the case of a cold start: this is when we come across products or users that are not represented in the interaction matrix.
Using the model is still easy, just don’t forget to install the library lightfm by using pip install lightfm and the corresponding extension for RecTools.
from rectools.models import LightFMWrapperModel
from lightfm import LightFM
model = LightFMWrapperModel(
# внутри модели указываем параметр no_components
# это размезность эмбеддингов, которые выучит модель
model=LightFM(no_components = 30)
)
model.fit(dataset)
recos = model.recommend(
users=ratings[Columns.User].unique(),
dataset=dataset,
k=10,
filter_viewed=True,
)More details about the algorithm can be found in original article 2015.
DSSM
We have already understood that if users and items are described by vectors of the same space, then the relevance of the item to the user is described by the proximity of their vectors. It turns out that searching for the top k most relevant items comes down to searching for the k nearest neighbors. This is called Approximate KNN.
That is, we need a model that models relevance using the dot product of embeddings. One of these models – DSSM – was invented in 2013 researchers from Microsoft. The idea of this simple neural network is this: let’s make two “towers” with fully connected layers and nonlinearities: one tower will be for users, the second for items.

At the output, each of these towers will produce embeddings of the user and the item, and the cosine of the angle between these vectors will model the relevance of the item to the user.
RecTools has an implementation of this algorithm. The authors implemented it themselves using the PyTorch Lightning framework. To use the model, do not forget to set the desired resolution.
from rectools.models import DSSMModel
model = DSSMModel(dataset,
max_epochs = 10,
batch_size = 64
)
model.fit(dataset)Adding Attributes to Models
Well, what if we want to take into account not only the interactions of users and objects, but also some of their distinctive features – attributes? It is clear that often the same products are liked by people of the same age, gender, profession, etc. And for objects, the attributes can be manufacturer, price, and much more, depending on what exactly we recommend.
RecTools has functionality that allows you to add user and item features to many of the models listed in the previous section (iALS, LightFM, DSSM, PopularInCategory).
First, you need to prepare data about users and/or items in a special way. Firstly, all the signs need to be “stretched” into one column valuelabeling each value with the name of the feature it relates to.
# загружаем данные
users = pd.read_csv(
"ml-1m/users.dat",
sep="::",
engine="python",
header=None,
names=[Columns.User, "sex", "age", "occupation"],
)
# отбираем только тех юзеров, которые есть в таблице взаимодействий
users = users.loc[users["user_id"].isin(ratings["user_id"])].copy()
# вытягиваем фичи в одну колонку и метим
user_features_frames = []
for feature in ["sex", "age", "occupation"]:
feature_frame = users.reindex(columns=["user_id", feature])
feature_frame.columns = ["id", "value"]
feature_frame["feature"] = feature
user_features_frames.append(feature_frame)
user_features = pd.concat(user_features_frames)
Afterwards, all that remains is to re-wrap the main dataset into a special class, while specifying the values of the arguments that are responsible for the features. If you only have numeric features, you can put make_dense_user_features=True. Otherwise, it is worth giving this argument meaning False – this will correspond to the sparse data presentation format.
sparse_features_dataset = Dataset.construct(
ratings,
# датасет фич
user_features_df=user_features,
# к этим фичам будет применен One Hot Encoding
cat_user_features=["sex", "age"],
# для `sparse` формата
make_dense_user_features=False
)After this, we are again ready to feed the dataset to the models (there are no changes in the code here). For example:
model = ImplicitALSWrapperModel(AlternatingLeastSquares(10, num_threads=32))
model.fit(sparse_features_dataset)Metrics
The developers have also added to RecTools all the basic metrics that may be useful when evaluating your recommendation models. At the same time, they not only maintain a single interface, but are also well optimized:
“We decided to use an approach that allows us to calculate metrics based on tabular data. This is similar to Single Instruction Multiple Data. That is, these are instructions in the processor itself that can apply the same simple operation (such as addition and multiplication) to several blocks of data . It takes less code, maintains interpretability, and also works hundreds of times faster.”
This is how you can calculate, for example, the classical ndcg for your recommendations:
ndcg = NDCG(k=10, log_base=3)
print("NDCG: ", ndcg.calc(reco=recos, interactions=df_test))
# 0.068In addition to this metric, the library also presents: Accuracy, F1Beta, IntraListDiversity, MAP, MCC, MRR, MeanInvUserFreq, Precision, Recall, Serendipity.
Conclusion
RecTools is an excellent library that contains all the most necessary models, metrics and tools for building recommendation systems. Methods for accelerating the operation of recommendations have also been introduced; many models support GPUs.
The library is constantly being improved and optimized, so don’t be stingy – give the guys a star on GitHub 🙂
Additional materials
If you want to dive deeper into the topic, you may find the following resources helpful: