OpenAI truncates ChatGPT Plus context length
There is an opinion that ChatGPT-4 began to work worse than before, and someone says that he is completely “stupid”, and is no longer “a cake”. I decided to look into this issue, determine and compare the context length of ChatGPT-3.5 and paid ChatGPT-4.
The amount of information that the model can hold in memory during the dialogue with the user depends on the length of the context. The context length is measured in the number of tokens. Depending on the language used, a different number of tokens are used in the dialogue with ChatGPT.
In theory, with an equal context length, ChatGPT should keep in memory 5 times more textual information written in English than in Russian. To determine the number of tokens, you can use tokenizer from OpenAI.
Example:

Goals of the experiment
Find out how the context length actually depends on the language used and how many times less information ChatGPT can remember in Russian than in English.
Determine the actual context length of ChatGPT-3.5 and compare it with the paid version of ChatGPT Plus, which costs $20 per month. And if according to the GPT-4 API it is officially known that the context length is 8 thousand or 32 thousand tokens, then information about the length of the context of the web version of ChatGPT-4 remains only a subject of discussion on the OpenAI forums. Some claim that it is 4 thousand tokens, others – 8 thousand.
Let’s find out what’s really going on and what users get for their money.
Check method
My verification method is as follows. I start by providing some initial data and then adding information by sending messages to the chat and counting the number of tokens in parallel, I try to determine the moment when the model loses access to this initial data. In other words, I want to find out at what point the addition of new information pushes the original data out of the context of the model.
I will say in advance that the results obtained by me through this empirical method surprised me greatly. Perhaps they can explain why lately many users have begun to notice a deterioration in the quality of ChatGPT-4.
So, let’s start with ChatGPT-4 and use the Russian language.

In the first prompt, I give the name of the boy who is the hero of the story I’m about to tell. It is worth noting that I also generated the story itself using the language model, and the name of the hero is not mentioned in it. By sending messages with fragments of this adventure story, I am in dialogue with ChatGPT. Periodically, I ask the model about the name of the main character. If the answer is correct, I delete the question about the name and continue the story, while counting the number of tokens.
Example of a correct answer:

It is important to note that the context includes both my messages and the model’s responses. At some point, ChatGPT-3.5 is unable to name the hero, which means that my first message with this information has been evicted from the model’s working memory.
In a similar way, I test in English, after which I go to ChatGPT-3.5 and test it in both languages.
Experiment results
Actual amount of ChatGPT-4 memory depending on the language used
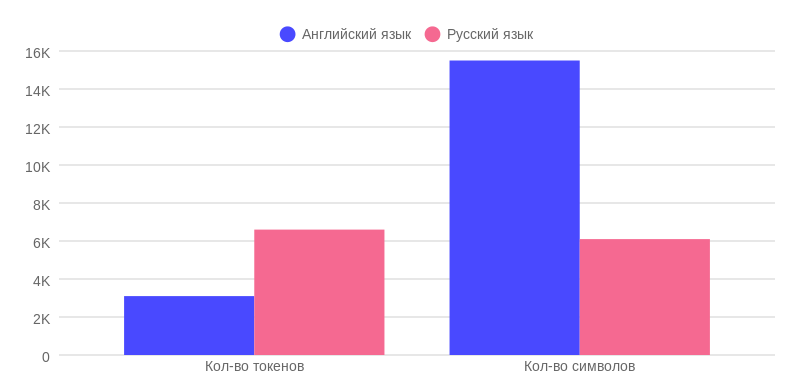
So, the first result immediately shows a deviation from the promised 8,000 tokens. The actual working memory of ChatGPT-4 in Russian is only 6,600 tokens. This is 1,400 tokens less than promised. Where could they go? Perhaps this is due to the fact that the GPT-4 architecture has a main model and several auxiliary ones, which makes it “smarter”. It is for communication between these models, the so-called system prompts, that these 1,400 tokens go.
I was even more surprised when I discovered that the working memory of ChatGPT-4 in English is only 3,100 tokens, which is significantly less than the claimed 8,000. I have repeatedly checked these data and still do not know how to explain that the model in English retains in memory two times less information in tokens than in Russian? Is it resource saving or something else? Why haven’t I heard about this before, especially since most ChatGPT Plus subscribers use the English language model?
Despite the fact that ChatGPT-4 still holds more characters in context in English than in Russian: approximately 15,500 versus 6,100 characters. However, the difference is not 5 times, but actually only 2.5 times. It turns out that the number of tokens for the “English” version was clearly cut.
Actual memory size of ChatGPT-3.5 depending on the language used
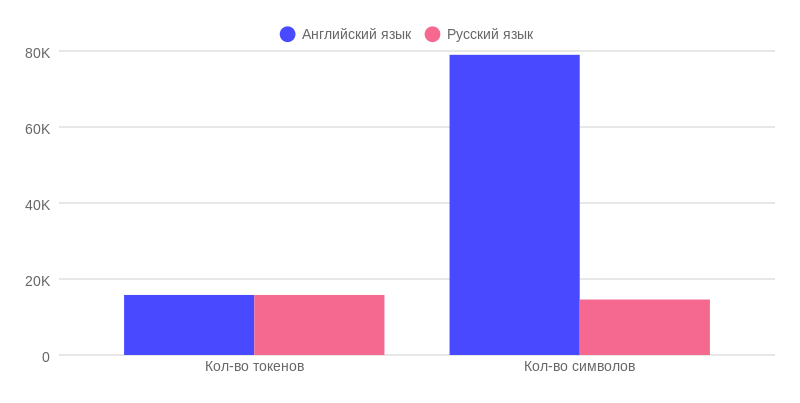
Now let’s take a look at the ChatGPT-3.5 results. Unlike the paid version, its actual memory is approximately 15,800 tokens for both languages. Given the error of +/- 100 tokens, depending on the version of the tokenizer, we get a result close to the declared 16,000 tokens.
The diagram above clearly shows the difference in actual memory size between English and Russian with the same number of tokens: 79,000 characters in English versus 14,600 characters in Russian. To better represent this amount of information, 80,000 characters is approximately 100 A4 pages.
It is also worth remembering that the quality of ChatGPT-3.5 responses in English is in most cases higher, since the model was trained on a significantly larger amount of data in English than in others.
ChatGPT Plus vs. Free ChatGPT-3.5
Maximum number of tokens in one message
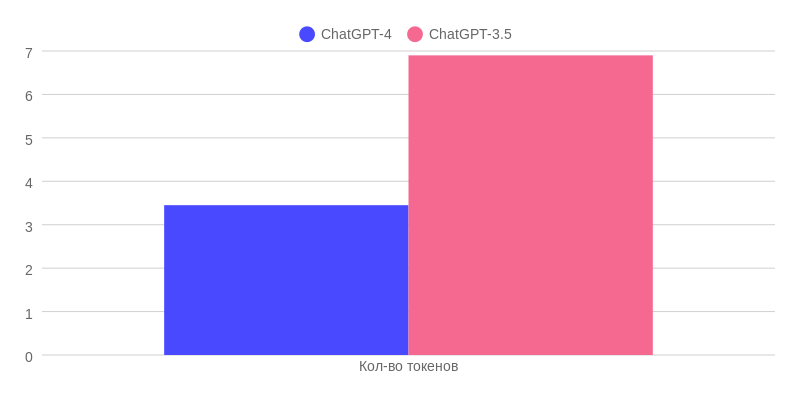
In ChatGPT-3.5, you can send twice as many tokens in one message – 6,900, which means more information than in ChatGPT-4. This can be used, for example, to demonstrate examples of the end result: describe the task and the end result, and add several examples to the same message. After all, the message size in ChatGPT-3.5 is twice as large.
Actual memory size of different ChatGPT models in tokens

The actual memory footprint of ChatGPT Plus is significantly less than that of ChatGPT-3.5. This is especially noticeable on the “English” version, where it does not even exceed 3,400 tokens.
What does this mean in practice?
If you give introductory information in the first message in English, and in the second message you use the maximum number of tokens, then ChatGPT-4 will no longer be able to tell you the name of the boy, since the introductory information was completely replaced by the second message. Even asking the boy’s name at the very beginning of the second message, ChatGPT-4 will not be able to answer correctly. Example:

Actual memory size of different ChatGPT models in characters
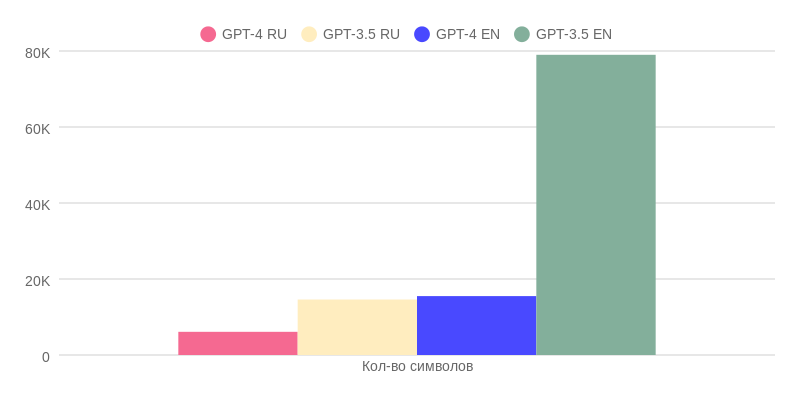
The amount of memory in ChatGPT-3.5 in Russian is almost two and a half times more than in ChatGPT-4. However, it is worth remembering that the quality of responses in the latter model is much higher.
If we use English, the difference in response quality between the two models is not so great. On the other hand, ChatGPT-3.5 has a five-fold advantage in actual memory space, since ChatGPT-4 had the context length truncated.
Instead of output
When using ChatGPT primarily in Russian, it makes sense to purchase a ChatGPT Plus subscription for $20 per month and use the fourth version, since the difference in the quality of answers is definitely worth it.
The situation with the English language is not so unambiguous, since ChatGPT-3.5 has significant advantages over ChatGPT-4: the ability to send twice as much information in one message and five times the amount of memory compared to the fourth version. True, it is inferior in terms of “intelligence”, that is, in terms of the quality of answers, but nevertheless, for certain types of tasks, ChatGPT-3.5 is certainly no worse than its new model.
But if ChatGPT-4 were offered with a context length of 32,000 tokens, or at least pure 8,000, and not these 3,100 tokens, then there would be a different conversation.
By the way, why do you think it was cut so much? It will be interesting to read your versions in the comments.
Words of gratitude
This article would not have been possible without the valuable contributions of Alexey Khakunov, the person who inspires me to explore the possibilities of ChatGPT in various fields: from business to personal use. I have been a part of his cool project from the very beginning, where there is a warm atmosphere and high quality educational content.
Lyosha also runs a telegram channel about artificial intelligence called “AI Happens”.
Recently, I got my own personal telegram channel “Taralas209”, where I write about IT in Europe, as well as about my personal experience and path in this area. If anyone is interested, you are always welcome





