Notes optimizer 1C (part 2). Full text index or how to quickly search by substring
In the last issue of the optimizer notes, I promised to return to other practical use cases for the QProcessing program. So, today we will talk about the full-text index in highly loaded 1C databases. Or rather, about an alternative that can be offered instead of full-text search from 1C or MS SQL.
We will talk about search queries by substring, which on the SQL side turn into a construct LIKE ‘%text%’. With two %%. In this case, standard indexes do not work and SQL performs a full table scan.
The idea of replacing the standard substring search mechanisms appeared six years ago, and in 2018 an article was published on this topic. I will not give a link to a third-party resource, but 1C-nicknames know where to look :-). Over the years, we have repeatedly implemented the replacement of the standard 1C search in forms through our methodology. Before describing the approach, let me remind you of a few points why such a need exists in principle. After all, there is a full-text search engine from the DBMS and there is a full-text search from 1C.
Where is substring search in demand in terms of business tasks?
In most cases, these are dynamic lists: a directory of contracts, counterparties, orders, payment documents, etc. There is a search field or the magic combination “Ctrl + F”. Users are looking for someone by full name, looking for an order number, passport number, payment number, etc. As a rule, they are looking not for the full name, name or number, but for some significant part. For example, the contract number is searched without prefixes or without leading zeros. In addition, very often they start typing a line in the search field and the system, without waiting for the end of the input, starts the search almost after the first character entered.
I described an approximate range of tasks. Now I will briefly list some of the pitfalls that accompany full-text search from 1C and from the SQL engine. I will not dive into details, because. Much has already been written about this. It is important to understand that full-text search is not for everyone and requires careful maintenance.
So, here are some features of full-text search that you should keep in mind.
Full text SQL index:
Population of the index occurs asynchronously and changes are applied with some delay relative to the main transaction, depending on the length of the index update queue. The delay can be either a few seconds or several hours.
Full text search can only search from the beginning of a word. Those. if we are looking for, for example, a contract number without prefixes and leading zeros, then a full-text search will return nothing or not at all what we expect. Accordingly, if there is such a task, then it is necessary to prepare a separate column where the contract number is divided into significant parts.
Full text search 1C:
The platform version and compatibility mode greatly affect how full-text search works. So, on older versions of the platform, full-text search may not work correctly or not work at all, giving an empty result.
During abnormal restarts of the DBMS server, the full-text data search (FDR) index may become unusable.
With a significant or intensive change in data, the scheduled task to update the PPD index has a significant load on the system. The time to rebuild the index can be measured in tens of hours.
Full-text search must be enabled for all configuration objects that can be used as the primary table of a dynamic list. Also, the full-text search should include all the details of configuration objects that can be displayed in a dynamic list and for which a search may be required.
The search is performed not on all columns of the dynamic list (and the configuration object), but only on those columns that are displayed in the table. And the search by reference fields is performed by the fields of the view, which also need to be remembered to be added to the full-text index.
All these aspects make the index maintenance procedure rather laborious. After all, if something is configured incorrectly, the index will not work and the search will either return nothing or switch to the standard mechanism.
The substring search task is in great demand, and in our practice of supporting highly loaded systems, we met different options for its implementation, but mostly these were self-written search mechanisms. At the same time, regular search in many forms was very often prohibited at the level of rights and interfaces, or rewritten with various restrictions: the composition of the search fields, the number of characters to be entered is at least N, splitting the string into significant characters and distributing them into columns and using search by initial characters .
We need a substring search, but we do not want to use a full-text index. How to be?
The main problem with full-text indexes is to customize them for practical purposes and keep the composition of indexed fields up to date in order to ensure data consistency when searching. By consistency, I mean quite common situations when using full-text search, when it returns an empty or incorrect selection. This may lead to incorrect user actions. For example, a user will add a new product to the directory, which will turn out to be a duplicate, because the search did not find it, but it is in the directory. Or the user will announce to the client about the absence of an item in the catalog, in the warehouse, etc.
I’ll tell you about our experience in implementing a quick search using the QProcessing program.
It was necessary to modernize the search mechanism among payment documents in the field “Purpose of payment”, which may contain full name, contract number, passport, etc. The search should give the user a list of documents that contain the typed search string.
The client has already implemented his own search, completely self-written (in 1C). Search time on average took 5-20 seconds (not really prohibitively large numbers), but at the same time, search maintenance was time-consuming, took a lot of time from technical support, refilling the “index” often did not have time to be completed within the scheduled window and overlapped with the working period, which led to a drop in the performance of the entire system, up to downtime.
In summary, the task was formulated as follows:
Speed up the search in 1C to select payment documents by part of the comment from the field “Purpose of payment” (no more than 5 … 8 seconds).
Reduce labor costs for servicing the search mechanism so that it is guaranteed to fit into the technological window (1-2 hours).
We approached the solution in two stages.
Step 1: Use SQL Full Text Index
Break the string into parts. The separator can be a space, semicolon, comma, etc. For splitting, a special Word Breaker SQLNGRAM.DLL library was used.
Create a unique non-clustered index on one column. In any document (or directory) there is such a column – this is Link.
if not exists( select top 1 1 from sys.indexes where name = N'sfp_index4fulltext ' and object_id = object_id(N'_Document272')) create unique nonclustered index sfp_index4fulltext on _Document272 (_IDRRef)Create a separate column for full-text search – expanded_descr, which will contain a combination of the required characters for the search.
if not exists ( select top 1 1 from sys.columns where name = N'expanded_descr' and object_id = object_id(N'_Document272')) alter table _Document272 add expanded_descr nvarchar(max)The created column is filled with the necessary data
if exists( select top 1 1 from sys.triggers where name = N'sfp_update_exp_description') declare @disable_tr nvarchar(max) select @disable_tr="disable trigger ["+tr.name + '] on ['+t.name+']' from sys.triggers tr inner join sys.tables t on t.object_id = tr.parent_id and tr.name="sfp_update_exp_description" exec sp_executesql @disable_tr go UPDATE x SET x.expanded_descr = /* select expanded_descr = */ replace( replace( replace( replace( replace( replace( lower(x._Description + N' '+ x._Fld17764) , N' ', N'@@'), N',', N'.'), N'(', N'#<'), N')', N'#>'), N'&', N'#$'), N'!', N'##') FROM _Document272 x WHERE x._Folder = 0x1 AND x._Fld1401 = 0 GO if exists( select top 1 1 from sys.triggers where name = N'sfp_update_exp_description') declare @enable_tr nvarchar(max) select @enable_tr="enable trigger ["+tr.name + '] on ['+t.name+']' from sys.triggers tr inner join sys.tables t on t.object_id = tr.parent_id and tr.name="sfp_update_exp_description" exec sp_executesql @enable_tr goA trigger is added that updates the contents of the expanded_descr column if changes have been made to the dictionary element. At the same time, characters are escaped, which can be auxiliary in terms of full-text search.
SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO IF OBJECT_ID ('sfp_update_exp_description', 'TR') IS NOT NULL DROP TRIGGER sfp_update_exp_description; GO CREATE or ALTER TRIGGER [dbo].[sfp_update_exp_description] ON [dbo].[_Document272] AFTER UPDATE ,INSERT AS BEGIN SET NOCOUNT ON IF NOT ( UPDATE (_Description) OR UPDATE (_Fld17764) /* НаименованиеПолное */ ) RETURN; UPDATE x SET x.expanded_descr = /* select expanded_descr = */ replace( replace( replace( replace( replace( replace( lower(x._Description + N' '+ x._Fld17764 ) , N' ', N'@@'), N',', N'.'), N'(', N'#<'), N')', N'#>'), N'&', N'#$'), N'!', N'##') FROM _Document272 x INNER JOIN inserted i ON x._IDRRef = i._IDRRef WHERE x._Folder = 0x1 AND x._Fld1401 = 0 ENDA full-text search catalog is created and, in fact, the full-text search index itself.
if not exists (select top 1 1 from sys.fulltext_catalogs where name="basic_ftc") CREATE FULLTEXT CATALOG [basic_ftc] WITH ACCENT_SENSITIVITY = OFF AS DEFAULT AUTHORIZATION [dbo] GO if exists( select top 1 1 from sys.fulltext_indexes where object_id = object_id(N'_Document272')) drop fulltext index on _Document272 create fulltext index on _Document272 (expanded_descr Language 1) key index sfp_index4fulltext with change_tracking = Auto
Then, using QProcessing, using a set of rules, the search query by substring (LIKE @P4) is replaced with a full-text search by a previously prepared column: CONTAINS (T1. expanded_descr, @P4).
Result. In general, everything worked, the search worked quickly. Correct in 99% of cases. But there were precedents that the search returned “nothing” or incorrect strings (links to documents) in which the substring was not found. For example, the first time the search returned the position, and when the request was repeated after a few seconds, it returned nothing.
In general, it was unpredictable, inexplicable and incomprehensible, and came down to the wording “Well, this is how a full-text index works.”
Therefore, the second stage appeared.
Stage 2. Your analogue of the full-text index
The main idea is to split the “Purpose of payment” line of each document into N parts with a window (interval) of 6 characters (6 is an empirically chosen limit on the minimum length of the search string) and an offset of one character to the end of the string. In this case, Window Offset takes into account separators such as “;”, “.”, “:”, “/”, etc. That is, if a window contains a separator character, then it is not included in the index.
An example of splitting a payment purpose line and packing it into a table, taking into account separators.
Платеж по договору №ФС-2134124124;Иванов Иван Иванович;паспорт№1378921
Substring of six characters | Is it indexed or not? |
Payment | Yes |
latezh | Yes |
age p | Yes |
tezh by | Yes |
… | |
124;Yves | No |
24;Willow | No |
4; Ivan | No |
;Ivano | No |
Ivanov | Yes |
… | |
to Ivan | Yes |
… | |
378921 | Yes |
The sequence of actions is similar to the previous step.
Create an index table
CREATE TABLE [dbo].[FullIndex]( [id] [varchar](6) NOT NULL, [ref] [binary](16) NOT NULL, [c] [bigint] IDENTITY(1,1) NOT NULL, CONSTRAINT [PK_FullIndex] PRIMARY KEY CLUSTERED ( [id] ASC, [ref] ASC, [c] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GOCreating a non-clustered index on an index table
CREATE NONCLUSTERED INDEX [ind1] ON [dbo].[FullIndex] ( [ref] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) GOCreate a stored procedure to split a string into words
CREATE PROC [dbo].[SetFullIndex] @Str varchar(max), @_IDRref binary(16), @fulltextindexname varchar(256) AS SET NOCOUNT ON declare @tempstr varchar(max) declare @int int declare @sql varchar(max) declare @delsql varchar(max) declare @startid int declare @endid int set @startid = 1 SET @tempstr="" SET @delsql="DELETE FROM " + @fulltextindexname + ' WHERE ref = 0x'+CONVERT(varchar(max),@_IDRref,2) +' ' SET @sql="INSERT INTO " + @fulltextindexname + '(id,ref) VALUES' SET @int = 1 WHILE CHARINDEX(';',@str)<>0 BEGIN SET @endid = CHARINDEX(';',@str) SET @tempstr = SUBSTRING(@str,@startid,@endid-1) /*print @Str print STR(@startid) print STR(@endid) print @tempstr*/ IF LEN(@tempstr) > 6 BEGIN SET @int = 1 WHILE @int + 5 <= LEN(@tempstr) BEGIN IF @sql <> 'INSERT INTO ' + @fulltextindexname + '(id,ref) VALUES' SET @sql = @sql + ',' SET @sql = @sql + '(''' + REPLACE(SUBSTRING(@tempstr,@int,6),'''','''''') + ''',0x'+CONVERT(varchar(100),@_IDRref,2) + ') ' SET @int = @int+1 END END ELSE BEGIN IF @sql <> 'INSERT INTO ' + @fulltextindexname + '(id,ref) VALUES' SET @sql = @sql + ',' SET @sql = @sql + '(''' + REPLACE(@tempstr,'''','''''') +''',0x'+CONVERT(varchar(100),@_IDRref,2) + ') ' END SET @Str = SUBSTRING(@str,@endid+1,len(@Str)-@endid) END --print @str IF LEN(@str)>0 BEGIN SET @tempstr = @str IF LEN(@tempstr) > 6 BEGIN SET @int = 1 WHILE @int + 5 <= LEN(@tempstr) BEGIN IF @sql <> 'INSERT INTO ' + @fulltextindexname + '(id,ref) VALUES' SET @sql = @sql + ',' SET @sql = @sql + '(''' + REPLACE(SUBSTRING(@tempstr,@int,6),'''','''''') +''',0x'+CONVERT(varchar(100),@_IDRref,2) + ') ' SET @int = @int+1 END END ELSE BEGIN IF @sql <> 'INSERT INTO ' + @fulltextindexname + '(id,ref) VALUES' SET @sql = @sql + ',' SET @sql = @sql + '(''' + REPLACE(@tempstr,'''','''''') +''',0x'+CONVERT(varchar(100),@_IDRref,2) + ') ' END END --print @sql Exec(@delsql) EXEC(@sql)Creating a trigger on a table with documents to change an index table
СREATE TRIGGER [dbo].[sfp_update_fulltextindex] ON [dbo].[_Document272] AFTER UPDATE ,INSERT AS BEGIN SET NOCOUNT ON IF ( UPDATE (_Fld23035) ) BEGIN DECLARE @fulldescr varchar(max), @IDRref binary(16) DECLARE fullindex CURSOR FOR SELECT _Fld23035 as fulldescr, _IDRRef FROM INSERTED OPEN fullindex FETCH NEXT FROM fullindex INTO @fulldescr, @IDRref WHILE @@FETCH_STATUS = 0 BEGIN EXEC SetFullIndex @fulldescr, @IDRref, 'FullIndex' FETCH NEXT FROM fullindex INTO @fulldescr, @IDRref END CLOSE fullindex; DEALLOCATE fullindex; END ENDInitial population of the index table.
The longest procedure and lasted more than a day. As a result, the index table took over 300 GB.
DECLARE @int int DECLARE @max int DECLARE @tempidrref binary(16) DECLARE @tempstr varchar(max) SET @int = 1 IF OBJECT_ID('tempdb..#AllRows') is null CREATE TABLE #AllRows (id int identity(1,1) primary key, _IdRref binary(16), _str nvarchar(4000)) ELSE truncate table #AllRows INSERT INTO #AllRows(_IDRref,_str) SELECT _IDRref, _Fld23035 expanded_descr from _Document272 SELECT @max = max(id) from #AllRows WHILE @int<=@max BEGIN SELECT @tempidrref = _IDRref,@tempstr = _str from #AllRows where id = @int Exec SetFullIndex @tempstr,@tempidrref,'FullIndex' SET @int = @int + 1 ENDNext, we set up QProcessing and replace regular search queries from LIKE%% from 1C to modified ones
original request
SELECT T1._IDRRef, T1._Marked, ... T1._Fld23035, ... FROM dbo._Document272 T1 WHERE ((T1._Fld2507 = @P10)) AND ((T1._Fld23035 LIKE @P11))', N'@P1 varbinary(16),@P2 varbinary(16),@P3 varbinary(16),@P4 numeric(10), @P5 numeric(10),@P6 numeric(10),@P7 numeric(10),@P8 numeric(10), @P9 numeric(10),@P10 numeric(10),@P11 nvarchar(4000)',0x8FE88206F16BC0A94F138691C51DBB25, 0x8FE88206F16BC0A94F138691C51DBB25, 0x8FE88206F16BC0A94F138691C51DBB25, 10,9,8,2,1,0,0,N'%Иванов Иван%'Changed request
Since the number of returned records from the index table can be quite large for popular rows (thousands and even tens of thousands), we insert additional filtering to reduce the selection in the substitution query, without excluding the main condition with LIKE. The condition contains not only the first six characters of the search string, but also the last six characters.
SELECT T1._IDRRef, T1._Marked, ... T1._Fld23035, ... FROM dbo._Document272 T1 WHERE ( T1._IDRRef IN ( SELECT t1.ref FROM FullIndex t1 INNER JOIN FullIndex t2 ON t1.ref = t2.ref INNER JOIN FullIndex t3 ON t1.ref = t3.ref WHERE t1.id = SUBSTRING(@P11, 2, 6) AND t2.id = SUBSTRING(@P11, LEN(@P11) - 6, 6) AND t3.id = SUBSTRING(@P11, IIF(LEN(@P11) > 11,5,2), 6) ) ) AND ((T1._Fld2507 = @P10)) AND ((T1._Fld23035 LIKE @P11))', N'@P1 varbinary(16),@P2 varbinary(16),@P3 varbinary(16),@P4 numeric(10), @P5 numeric(10),@P6 numeric(10),@P7 numeric(10),@P8 numeric(10), @P9 numeric(10),@P10 numeric(10),@P11 nvarchar(4000)',0x8FE88206F16BC0A94F138691C51DBB25, 0x8FE88206F16BC0A94F138691C51DBB25, 0x8FE88206F16BC0A94F138691C51DBB25, 10,9,8,2,1,0,0,N'%Иванов Иван%'
Results
1) Search speed
Based on the implementation results, a separate automatic testing of the search mechanism was carried out and compared with the old one. 18,000 “document numbers” were selected and searched among documents for 6 years. The search time was fixed.
The results are presented in the figure below.
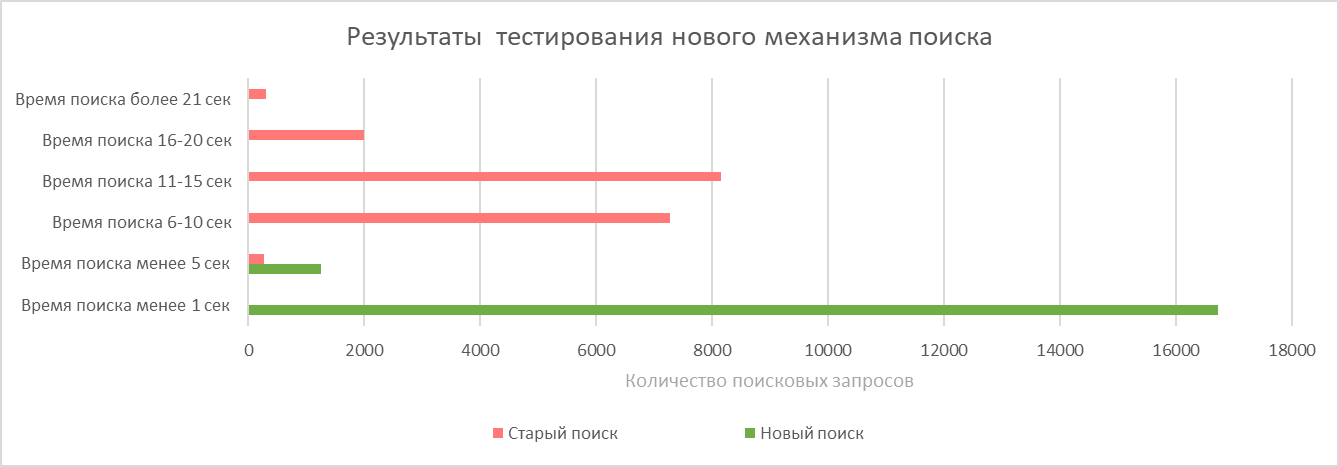
Comments, I think, are superfluous. Search in 1C has accelerated hundreds of times and in 90% of cases began to take less than 1 second.
2) Index table maintenance and size [FullIndex]
After the initial filling in the table turned out to be 2 billion rows, the size of the table was 345 GB. The initial filling time is a little more than a day. Of course, this time will be different for everyone and depends on the number of rows in the source table (25 million rows), the number of characters in the comment field (160 characters on average) and on hardware resources.
With a total database size of ~12 TB, the increase in its size was ~3%.
Update table entries [FullIndex] happens automatically – or by a trigger to change the table [_Document272], or by task with any specified frequency. We stopped at the task in order to exclude unnecessary blocking from users.
In addition, we set up a separate task for recalculating statistics for the table [FullIndex] once a day, so that they are guaranteed to be recalculated, regardless of the recalculation of statistics for all other tables.
Links to all parts of Optimizer’s Notes1C:
Notes optimizer 1C (part 1). Strange behavior of MS SQL Server 2019: long running TRUNCATE operations
Notes optimizer 1C (part 2). Full text index or how to quickly search by substring