How to set up ETL with jsons in Apache NiFi
Description of the task
We have an external service where recruiters work with selection. The service can provide data through its API, and we can download this data and store it in storage. After loading, we have the opportunity to give the data to other teams or work with it ourselves. So, the task has come – we need to load our data via the API. They gave us the documentation to download and off we went. Let's go to NiFi, create a pipeline for requests to the API, transform them and put them into Hive. The pipeline starts to crash, you have to sit and read the documentation. Something is missing, JSONs are not correct, complications arise that need to be sorted out and solved.
Responses come in JSON format. There is enough documentation to start downloading, but not enough to fully understand the structure and content of the response.
We decided to simply download everything – we’ll figure out on the spot what we need and how we’ll load it, then we’ll go to sources with specific questions. Since each API method returns its own data class in the form of JSON, which contains an array of objects of this class, you need to build many such pipelines processing different types of JSONs. Another difficulty is that objects within the same class may differ in the set of fields and their contents. This depends on how, for example, the selection staff fills out information about the vacancy on this service. This API works without versions, so if we add new fields, we will only receive information about them either from the data or during the communication process.
What tools did we use?
To solve this problem, we took Apache NiFi and HDFS/Hive, adding Jolt and Avro in the process. Apache NiFi is an opensource, multi-system ETL tool that runs in a JVM on the host operating system.
Architecturally, it has the following components:
Web Serverwhich hosts the HTTP-based NiFi management and control API;
Flow Controller — the brains of NiFi, manages its resources;
Extensions — various NiFi extensions that also run in the JVM. For example, Registry. We can store our pipelines in it;
FlowFile Repository stores all information about flow files;
Content Repository — contents of all flow files;
Provenance Repository — a repository of stories about each flowfile.
Here are the elements that make up the pipeline in NiFi:
processor — a function that performs an operation on the incoming flow file and transmits it to the outputs specified by the logic;
flowfile — an entity consisting of a set of bytes (content) and metadata for it (attributes);
connection — connection between processors, queue between flow files;
process group – a set of processors and connections between them, from which more complex pipelines can be created. Process group can be saved as a template, stored in the Registry or XML file, and passed on to colleagues for work.
NiFi comes out of the box with a lot of processors that can perform different logic. Processors can be divided into the following types:
Data Ingestion are engaged in generating or loading data from other systems into NiFi. For example, GetFile;
Data Transformation work with the contents of flow files. For example, ReplaceText;
Routing and Mediation — direction, filtering, validation of flow files. For example, RouteOnAttribute;
Splitting and Aggregation – dividing one flowfile into many and vice versa. For example, SplitText;
Attribute Extraction — working with attributes. For example, you need to write some logic for processing attributes via regexp;
Data Egress/Sending Data — sending data from NiFi to other systems. For example, PutFile.
I will demonstrate everything that has been said with an example. The idea of the pipeline is that we generate some kind of json and send it to the process group, where the logic is built in that will distribute it to different outputs depending on the type of json. (slide 12.28)

I have a process GenerateFlowFile. I added custom text in it, this is json. There is one field inside Data, which contains two fields – type and id. Let's try to process them. I started the processor, the flow file fell into the queue, let's take a look at it. (slide 13.10)

Then we fall inside process grouprun in it input and we see that the flowfile has entered our process group. We send it to the SplitJson processor. (slide 13.22)
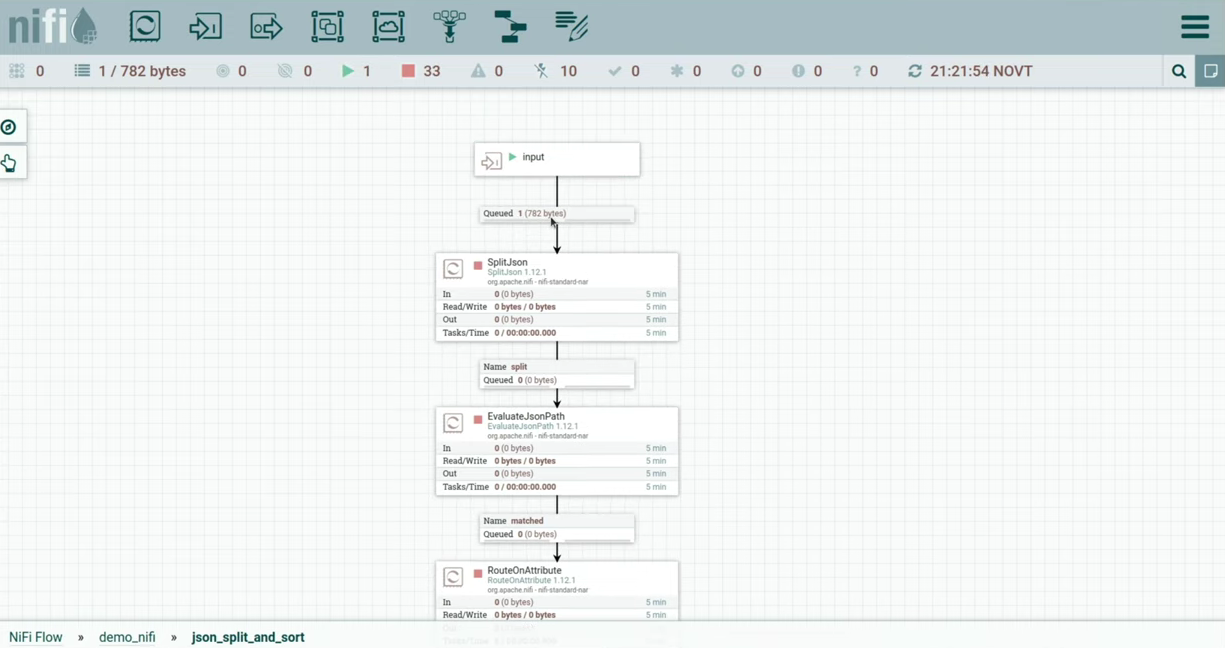
In the processor settings we specified JsonPath Expression — the field that he will look at when splitting json into separate flow files. This will be the field data, which contains the array. When we launch, we have ten flow files, they will look like this (slide 13.50)

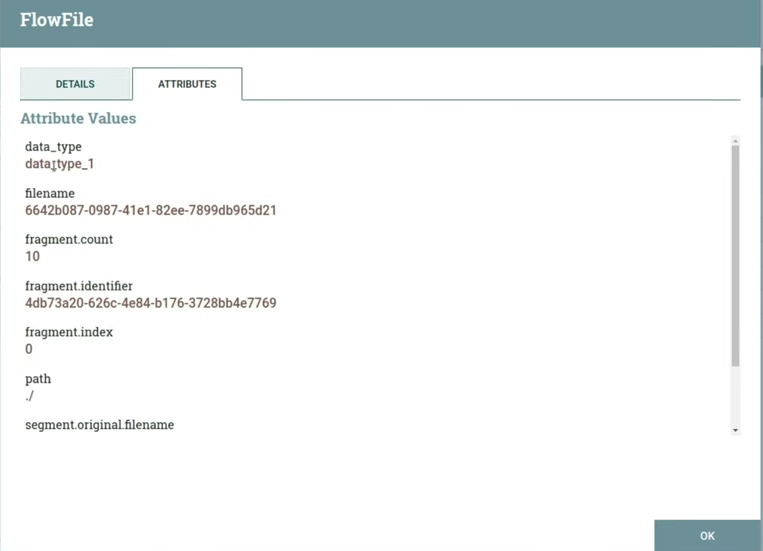
Next we need to extract our type from json into the attributes. We indicate in property flowfile-attribute the field from which you need to extract data, and the attribute into which it needs to be pushed – in our case this is data_type. When launched, ten flow files also appear, the content has not changed, but the attribute has been added data_type with content data_type_1. It corresponds to the value that was in the field data_type json. (slide 14.20)
Now we can send it all to the processor RouteOnAttribute. In it I created three properties, the name of each of which corresponds to the type from json. Using NiFi Expression Language I wrote something like ifWhere data_type is the name of the attribute on which the operation needs to be performed, and the method equals compares the contents of an attribute with a given string ‘data_type_1’. (slide 14.58)

After starting the processor, you can notice that the flow files are divided into different queues. data_type_4 was not registered in propertyso he fell into the exit unmatched. (slide 15.23)
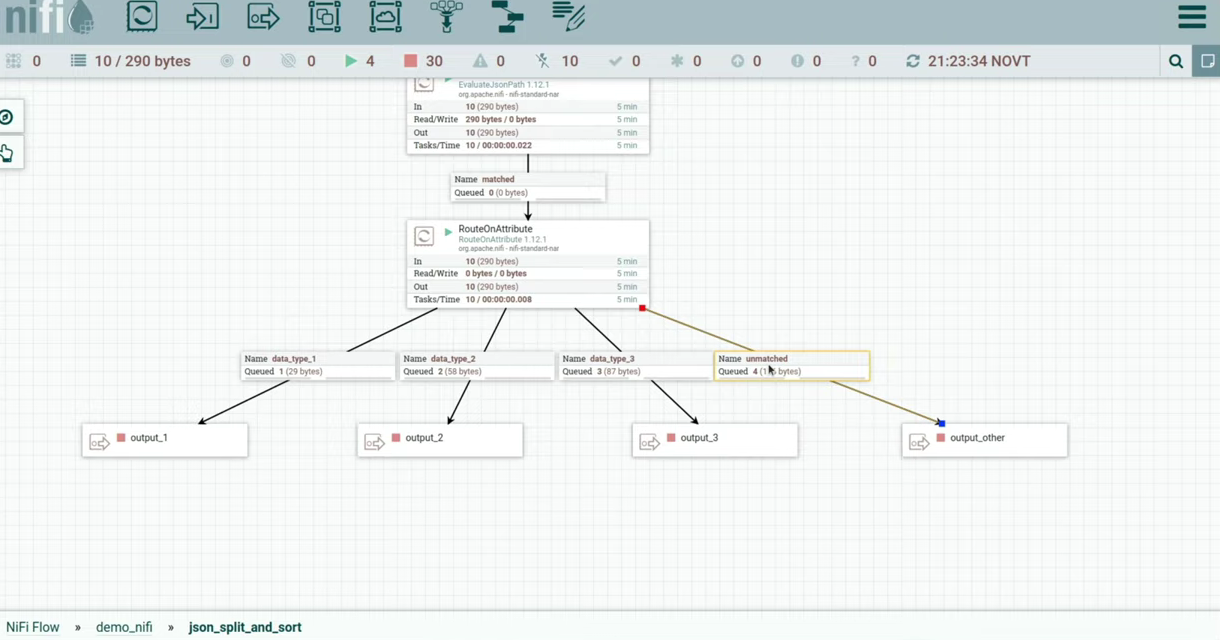
Let's open our exits. We see that flow files fell on different processors, which can scatter them across different systems, depending on the type from json. I also hardened the process group, in which you can draw logic resolve For unmatched flowfiles.
Avro
Avro is a data serialization system. An Avro file consists of binary data with an accompanying Avro schema that describes this data in json form. Avro also supports dynamic typing, that is, the ability to deserialize our data without describing the data in code, for example, due to the schema attached to the file.
The system also supports schema evolution – if you follow the compatibility rules, you can deserialize a file with a schema different from the one with which the file was serialized, and vice versa. There is support for high write speeds, this is suitable for streaming ETL tasks, for example, Kafka. There are often cases when NiFi works with some files, writes them to Avro, and then uploads them to Kafka. The storage type here is lowercase, so you need to be careful when analyzing large volumes of such files; it is better to convert them to other formats. It is possible to automatically generate an avro-scheme, which is useful when working with jsons.
In our task, we can use the ability to create a hive table based on an avro schema. You can upload json to Avro, an Avro schema will be automatically generated, on the basis of which a hive table will be created. It is also possible to change the Avro schema at the heart of the hive table without having to change the saved data.
Jolt
Sometimes problems arise due to the fact that json contains different types or the structure is not suitable for recording in Avro. This is where Jolt comes in handy – a java library for transforming json2json, using “specifications” in the form of json as instructions for conversion. It is mainly used to transform the structure of a JSON document, but new features have the ability to work with specific values. For example, in NiFi you can put timestamp inside json from an attribute. In addition, Jolt provides us with the opportunity to perform a chain of transformations, for example, first change the structure, then change the types, and then cardinality.
In our task, using Jolt, we can turn nested json into a prefix soup, making the json structure as flat as possible. And also – bring certain fields to a specific type, that is, if different types come in the same field in different json, then convert them to one type. You can also change the cardinality of some field, for example, the field in which it can come string or array<string>lead to array<string> – Jolt will make all incoming jsons in this field array<string>. Among other things, we can enrich the data by inserting values from the flowfile attributes into json.
I will demonstrate what a template for such a pipeline might look like. I froze input, let's say we take json of the following type from some source. (slide 21.27)

We are interested in objects that are in the field objects. Inside the field other_fields_string can come either intor string; inside the field fields_array – either stringor array<string>also in dynamic_fields It might even be empty.
We need to bring everything to a single form in order to write everything down in a table.
We received the flow file, we can deliver UpdateAttribute, which will indicate the timestamp of our download or the path where you need to save any information you need. Since we are transforming json here, I would recommend keeping the original data as it was loaded. For this I locked process group, inside of which you can implement the logic for saving raw json in storage. (slide 22.34)

Having made sure that our data is saved and can be accessed if something happens, we begin working with json. We throw it into SplitJson, in which we indicated that we need to split it into separate objects and look at the objects field, which contains the array. After this, four json are obtained. If this is json with a thousand fields, I wouldn’t want to go through each json and look at the types. It would be better to see what kind of avro-scheme you get if you generate it for all json. For this purpose there is process group, the result of which is given below. (slide 23.57)

The Avro diagram will look like this. We will have a set of fields in the form of names and types of these fields. Because id always comes like intthen we see here either nullor long. Null Avro always puts it in case there is no value. You can see the field here dynamic_fieldsinside which lies a structure of other_fields_stringaccepting either stringor longor nullAnd other_fields_arrayreceiving string, array<string> or null. It looks a little complicated, and it’s also unclear how it will be read in the table. Let's try to bring this to a more readable form, for which we use JoltTransformJSON.
Let's write a specification for it consisting of three actions:
Biasin which we indicate that actions should be performed only with fields
dynamic_fields. All fields insidedynamic_fieldsneeds to be moved to a higher level with the addition of a prefixdynamic_fields(fromarrayVdynamic_fields_array). They will lie at the same level asid.After the offset we can apply the command to the new fields toString and convert them to string only.
After this we can indicate plurality. We need it in the field
fields_arraythere was always an array, so we specify MANY.
I will demonstrate the json changes before and after processing. (slides 26.51 and 26.54)


Let's now try to perform the same operation and generate a common avro-scheme for all jsons. It can be seen that now there are only three fields, no structures inside the fields. Fields can accept types null And long, null And stringand null And array<string>. (slide 27.28)
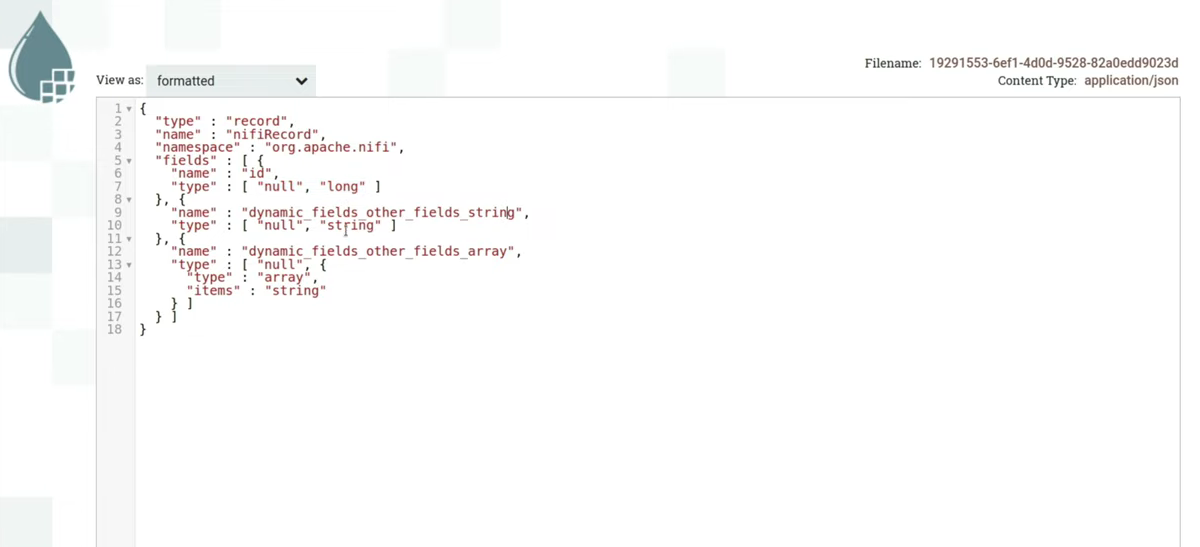
Once we have generated this diagram, we can fit it into ConvertRecord – a processor that converts from one format to another. In this case, JsonTreeReader is used, it specifies the avro-scheme from which we want to read json. If everything matches the schema, ConvertRecord will read these jsons with the required schema and serialize them into Avro. Inside Content Our avro file will already be there. Since NiFi can deserialize avro, you can format the content and see what json is inside in a beautiful form. (slide 29.02)
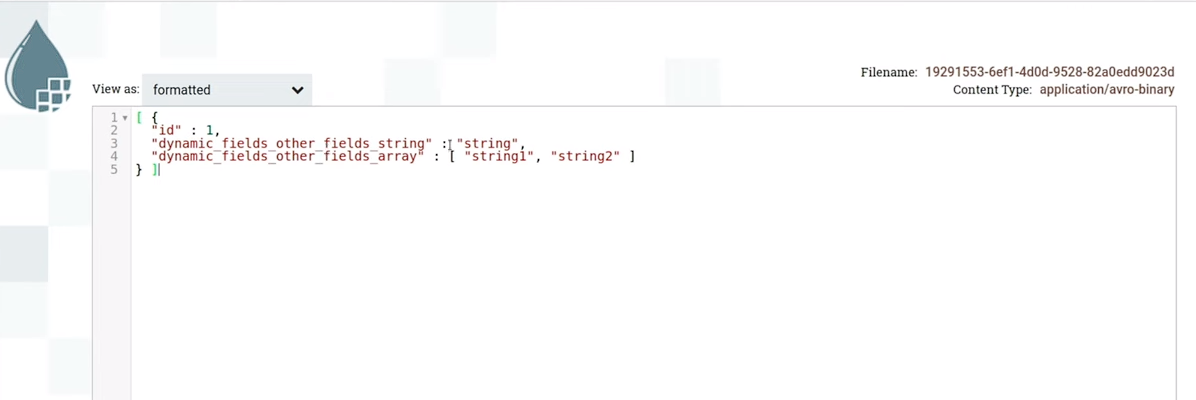
For example, if you remember, dynamic_fields It was empty before. In the case of this diagram we will see fields with null. That is, avro created something like json, specified the fields from the schema and wrote them null. When we read this as a table, these fields will be null inside because there were no values for them in the file. (slide 29.35)

Then we send it out to some of our storage facilities. Note that each processor has several outputs, these can be success, failure and others. If something was wrong, we will see these flow files in their original form and will be able to carry out some additional transformations and resend them, for example. Jolt Transform Demo also has an Advanced button where you can experiment with different specifications.
Total
When creating a new pipeline, there are a lot of handicaps: we have to look at the resulting json, write a specification for processing, generate or manually edit an avro-scheme. In the current implementation, you need to add monitoring for the appearance of new fields in json. In the example I showed, if something comes with other types, it won’t break the circuit – it just won’t read it. But if the source does not want to report new fields and you have to track them yourself, then monitoring is needed.
It is worth noting that this solution is suitable for the data landing layer, but requires subsequent cleaning and saving in formats that are better suited for analytics. In this regard, column types are more useful. NiFi also supports custom processors. A developer can write his own processor, assemble it into a NAR file, put it under our NiFi instance and use it in his pipelines.