How I dropped the product for an hour and a half, what does soft delete and partial index have to do with it

Hello! My name is Oleg and I work at Skyeng. My team and I are developing the core of the educational platform on which all online lessons are held, homework, exams and tests are solved.
Previously, at IT interviews, I was asked the same question:
— Tell us about the biggest failure in your career?
I'm not sure the answer reveals much about the candidate, but the purpose of my article is clear: to share my experience to prevent similar incidents in the future.
Why is the failure the biggest?
I attribute the crashed server to highload. Judge for yourself:
~500 RPS;
~0.5 billion records in one database table;
~3 TB for the entire database.
Skyeng conducts an average of 3000+ lessons per hour. For an hour and a half, the main segment of our business went offline and students were unable to access the platform. This cost the company dearly.
How it all started: analytics and soft delete
It’s no secret that modern software is loaded with analytics—every user action is anonymized and logged.
Typical events in the analyst log: the user opened a page, the user clicked a button, and so on. This helps you understand which buttons are clicked more often than others, and which ones should be thrown out as unnecessary. Business, in turn, can draw conclusions about which features in the application users like and which ones “didn’t take off.”
Analytical reports are based not only on the log of user actions. For example, product databases can be used as a source of information – for us it is PostgreSQL.
There is one nuance with the latter: if data from the database is used in analytical reports, then a banal deletion (SQL DELETE) of a row from the table can ruin this very report. Therefore, on the one hand, you need to be able to delete data from the database, but on the other hand, you cannot delete it, since the analytics will be spoiled. What should I do?
Soft delete is a pattern in which records are not deleted, but remain in the database forever with a deletion mark. That is, instead of SQL DELETE, SQL UPDATE with deleted_at = now is used.
As you may have guessed, my team needed to implement soft delete for analytics reports to work correctly.
Technical review
Technology stack on the target service: PHP 8.1, Symfony 5, PostgreSQL. There is no soft delete, that is, when deleting a record from the database, SQL DELETE works. We find a ready-made boxed solution for Symfony and its ORM Doctrine extension SoftDeleteable.
This allows you to enable soft delete with virtually no code changes. It is enough to add this package to the project via composer and enable soft deletion in the database entity configuration. Let's not forget to add a new column to each necessary table deleted_at using SQL ALTER TABLE.
Is this task completed? Not really.
There are billions of records in the database, and to speed up SQL queries we specifically use indexes. After implementing soft delete, existing unique indexes will interfere with the current logicand that's why.
Let there be a compound unique index for two columns: user_id And resource_id.
Consider the scenario:
Add an entry with
user_id = 100Andresource_id = 10.We delete this entry, remembering about soft delete: we write the current time in
deleted_at. The service no longer sees the deleted record, but it is in the database.
Our application logic allows for a record to be reinserted after it has been deleted. But after implementing soft delete, we will no longer be able to insert a record with the same pair (user_id And resource_id) due to a uniqueness violation – the database will throw an error.
The PostgreSQL feature comes to the rescue – partial index. This is an index that is not applied to all database records, but only to the part that matches the predicate. In our case, partial index is superimposed on records that have
deleted_at = NULL(this is the predicate). Thus, partial index ignores all entries marked deleted.
This looks like an ideal solution in the current situation. Once an entry is marked deleted via deleted_at, it is immediately automatically excluded from the partial unique index. That is, a record marked as deleted is now not visible to the service and the partial unique index. Therefore, reinserting a record with the same values will work without problems.
The next question is: what to do with the old, non-partial indexes already in the database?
Obviously, the old unique indexes need to be carefully deleted and new, similar partial unique indexes must be created.
Removing an index, even on a large database, is completed in seconds. But Creation index can take an hour per piece, and we have as many as 5 such indexes! If we first delete the old unique indexes and then start creating new ones, we will get a window of several hours when the service will work under normal load, but without indexes. This will automatically lead to the downfall of the service and, as a result, the entire Skyeng school. We foresee this and will not do so.
Therefore, first we create new indexes in the background, and only after that we delete the old ones. We immediately note that we will do SQL queries to delete old and create new indexes manually in the product database, since in CI/CD such hour-long operations will not work due to the time limit for deployment.
Our final release plan (don't do this!):
Add a column to a table
deleted_atWithdefault NULL(deploy migration).Create a new unique partial index (by hand, set 5 hours).
Delete the old unique index (by hand).
Enable soft delete in the code (install Doctrine extensions, enable soft delete in configs, fix the new database structure through migrations).
Release: day 1
The first two points look quite safe. They take the most time due to the many hours of creating new partial indexes, so we decided to split the release into two days.
As expected, the first stage went smoothly, except for an alert from Misha from the infrastructure team – file storage costs increased sharply:


Release: Day 2. How the incident developed
So, day X comes. The release continues during the next deployment window.
At 12:10 I run SQL commands to delete old unique indexes in the food database as planned. There are no signs of problems with deleting old indexes, because the new partial indexes already exist and are ready to work!
At 12:17 all old indexes are deleted. Judging by the database size graph, things have improved:
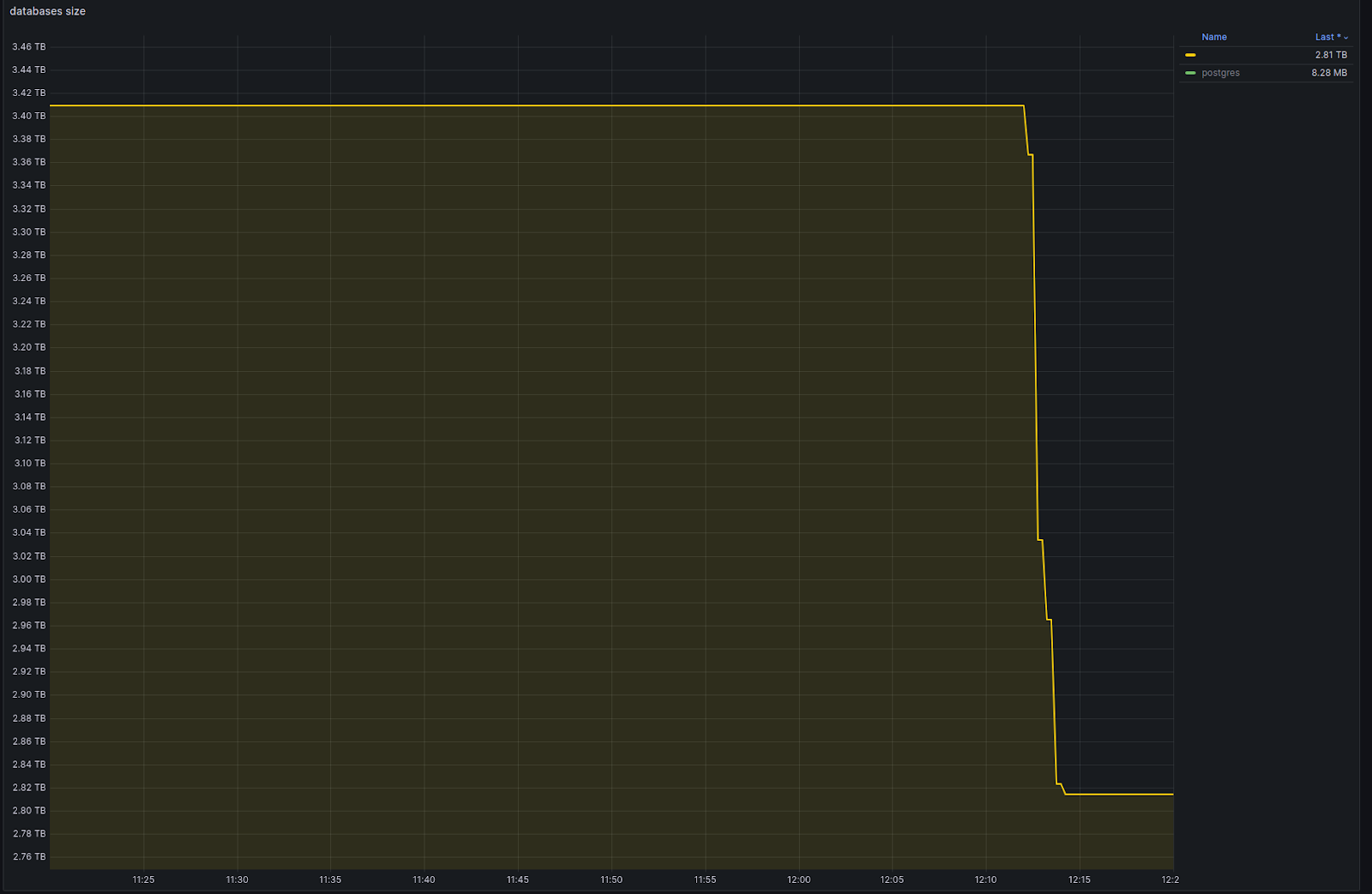
However, already at 12:20, complaints from customers began to arrive en masse. I looked at the service monitoring and realized that the product had dropped.
Monitoring HTTP responses from the service shows a sharp jump – 500 errors. Connections to the database are clogged, judging by the CPU and RAM load, something is going wrong.
The usual practice in such cases is hotfix or rollback. The second is simpler, but in this situation it will not be possible to quickly return everything as it was – there is nothing to roll back. We deleted the old indexes manually, and to get them back, you need to manually run the SQL command and wait 5 hours – this is clearly not an option.
You can’t roll back, you can’t fix (the comma is placed correctly)
Fortunately, Sasha, my team leader, promptly intervened in the incident. He quickly and soberly assessed that there are new indexes, but they do not work. How can this be?



The old indexes no longer exist. There are new partial indexes, but the code on the server is old → the old code does not use the new indexes for search queries → SQL queries take a very long time to execute. The database connections and request queue were clogged → the service crashed under load.
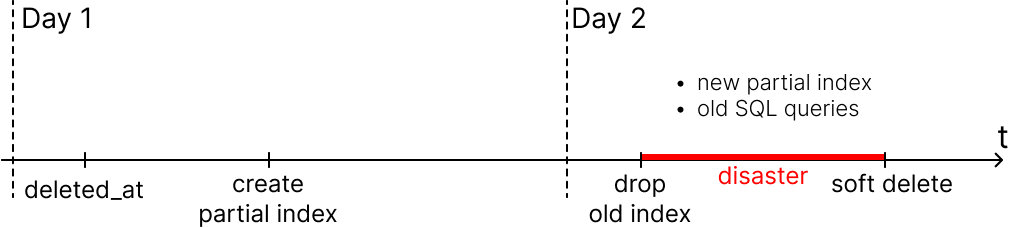
Initially, I did not take into account a key detail: partial index only works when the SQL query in the code contains a predicate similar to the partial index predicate (the predicate here is what comes after WHERE).
Simply put:
This query does not use partial index:
SELECT * FROM exercise WHERE user_id = <user_id> AND resource_id = <resource_id>
The correct request is to use partial index:
SELECT * FROM exercise WHERE user_id = <user_id> AND resource_id = <resource_id> AND deleted_at IS NULL
It is clear that at the end point of the deployment everything was fine. But in the window between the 3rd and 4th points we received a disaster.
Unfortunately, the deployment was completed only at 13:30. There was a queue of builds in GitLab workers, and my deployment was waiting until the worker was free. Plus, the canary deployment gave its delay.
In this case, it was possible to roll with the canary turned off. When the deployment was completed, it was necessary to restart memcached – after that the situation began to return to normal.
The incident ended at 1:52 p.m.
A plan that excludes a drop in sales
Add a column to a table
deleted_atWithdefault NULL(deploy migration).Create a new unique partial index manually. We set it at 5 hours.
Enable soft delete in the code: install Doctrine extensions, enable soft delete in configs, fix the new database structure through migrations.
Delete the old unique index.

This release option will prevent a drop in sales, but there is one interesting point.
The fact is that until the release is completed (point 4), the old unique index lives in the database. Therefore, in the window between the 3rd and 4th points, we are potentially faced with 5xx errors if someone deletes using soft delete and then tries to add a new record with the same data. The old unique index will not allow this to be done until it is deleted. With RPS close to 1000, even in a minute you will catch several errors.
But there is a more correct option, which we came to together with a developer from a neighboring team – she also recently made a mistake on such a case.
Seamless release plan
When new code with soft delete is in production, the old unique index needs to be deleted. Otherwise, it will not allow you to add new records similar to those deleted using soft delete. On the other hand, you cannot delete the old unique index while the old code is running.
We came up with an idea: together with the new partial index, create a temporary search index – similar to the old one, but without the uniqueness constraint.
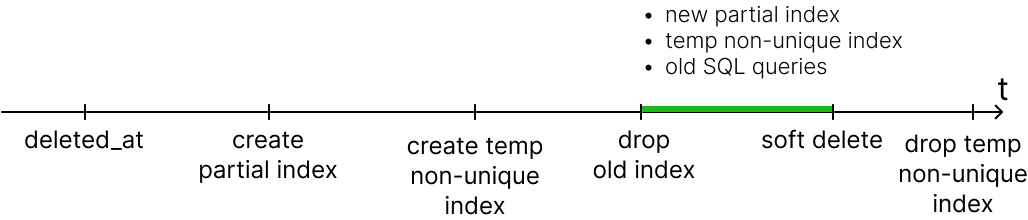
Add a column to a table
deleted_atWithdefault NULL— migration deployment.Create a new unique partial index by hand, set aside 5 hours for this.
Create a temporary index identical to the old one, but without the uniqueness constraint. We also do it by hand, setting it for 5 hours.
Delete the old unique index.
Enable soft delete in the code: install the Doctrine extension, enable soft delete in the configs, fix the new database structure through migrations.
Delete a temporary non-unique index.
In this case, at any time during the release, search queries will work quickly, and we will not have problems with inserting new records.
Disadvantages of this option:
Release time is doubled due to the creation of an additional temporary non-unique index.
Temporarily doubles the size of the database storage.
Results
It’s bad that such a case happened. It's good that we identified the reasons, fixed everything and were able to share the results. This will help prevent similar incidents not only in Skyeng, but, I hope, in everyone who read the article to the end!
By the way, my colleagues reacted with understanding to what happened. After all, almost every developer has a similar story in stock. Ask a friend a friend during a break!
And, of course, don’t blame yourself for mistakes. As the sages say:

Thank you for your attention. I look forward to your questions in the comments, have a nice day!