How, by changing the architecture, we optimized traffic costs in AdTech
A lot of money was spent on traffic, it was necessary to optimize costs
The client had an SSP deployed on AWS to serve ads on the site.

Monthly infrastructure costs averaged $25,000 per month ($750 to $900 daily usage). Approximately $10,000 of these monthly expenses were in the cost of network traffic. That is why we decided to prioritize cost optimization for it.
The idea was to purchase dedicated servers with an unlimited rate for outgoing traffic in any third-party data center (DPC) and transfer the most traffic-consuming component of the system to these servers. Important note: the specified component was stateless, that is, it did not store any persistent data. Next, it was planned to set up a load balancer to distribute traffic between the data center and AWS. It was planned to send the base part (that is, the maximum daily peak + 20% headroom) of available traffic to the data center, and send bursts of traffic to AWS, since autoscaling is configured there.
Hybrid architecture is the way out
We have analyzed two possible hybrid infrastructure implementation strategies:
Loosely coupled infrastructure (the infrastructure in the data center will be self-sufficient, that is, it will not depend on the infrastructure in AWS) – as part of this strategy, we considered deploying separate Kubernetes clusters in AWS and the data center (with lower traffic costs), capable of operating almost independently (in our case, this means having your own Aerospike cluster, a separate NATS cluster);
A tightly coupled infrastructure (the infrastructure in the data center will depend on the components in AWS) – deploy a part of the SSP that generates a lot of traffic on dedicated servers in the data center and organize for it the ability to use services in AWS. Such as NATS, Aerospike, Prometheus, AWS S3, AWS Kinesis Firehose, AWS OpenSearch.
After spending some time analyzing and researching the above strategies, we got a general idea of the pros and cons of each, and most importantly, an understanding of the necessary resources for their implementation. Both strategies required a VPN link between AWS and the data center. It was the approaches to the implementation of this channel that seemed to us less reliable and more complicated in the implementation of a loosely coupled infrastructure. Therefore, we decided that implementing a tightly coupled infrastructure is the preferred option.
Developed two plans for the transition to a new architecture
As mentioned above, the primary requirement for implementing a hybrid infrastructure is to provide a reliable and secure communication channel between AWS and the data center so that AWS services are available to the data center. To implement this communication layer, we tested:
Solutions for connecting Kubernetes to Kubernetes based on Submariner/Liqo;
Classic solutions for connecting VPN between data centers.
We decided to move sequentially and try both options in order to choose the most suitable one. That is, we decided to prepare two sequential plans depending on the test results:
“Plan A” – test Kubernetes to Kubernetes connectivity solutions – if they fit our needs and perform well during tests, we will use this option;
Plan B – Otherwise, we will switch to a VPN-based connectivity solution.

As part of Plan A, we deployed and tested two well-known Kubernetes-to-Kubernetes connectivity solutions, Submariner and Liqo. Unfortunately, they have problems that block their use in our project.
For example:
Submariner does not work with the CNI Cloud Network Plugin and requires one of the other CNI Plugins to be used. This results in a lot of customization in Kubernetes cloud worker nodes, and most of these customizations require additional steps to automate. On the other hand, Submariner provides full-featured cross-cluster service discovery (ServiceDiscovery), which would be quite useful for our implementation;
Liqo works with CNI cloud plugins by default and the overall installation process is much easier, but it does not have ServiceDiscovery. As mentioned, Liqo works great with the default cloud CNI plugin, but has a lot of issues when using other CNI plugins.
As a result of our initial research into Kubernetes to Kubernetes connectivity solutions, we decided to move on to “Plan B” – there are several VPN/Connectivity solutions we could implement in this case:
Cloud-provided VPN Site to Site – This worked well in our tests (~2ms latency, ~850Mbps throughput);
A custom Site-to-Site VPN solution (such as Wireguard or standalone IPsec services).
We chose to use Site-to-Site Cloud VPN as we have a lot of experience with this approach in several other projects.
What have we done to launch
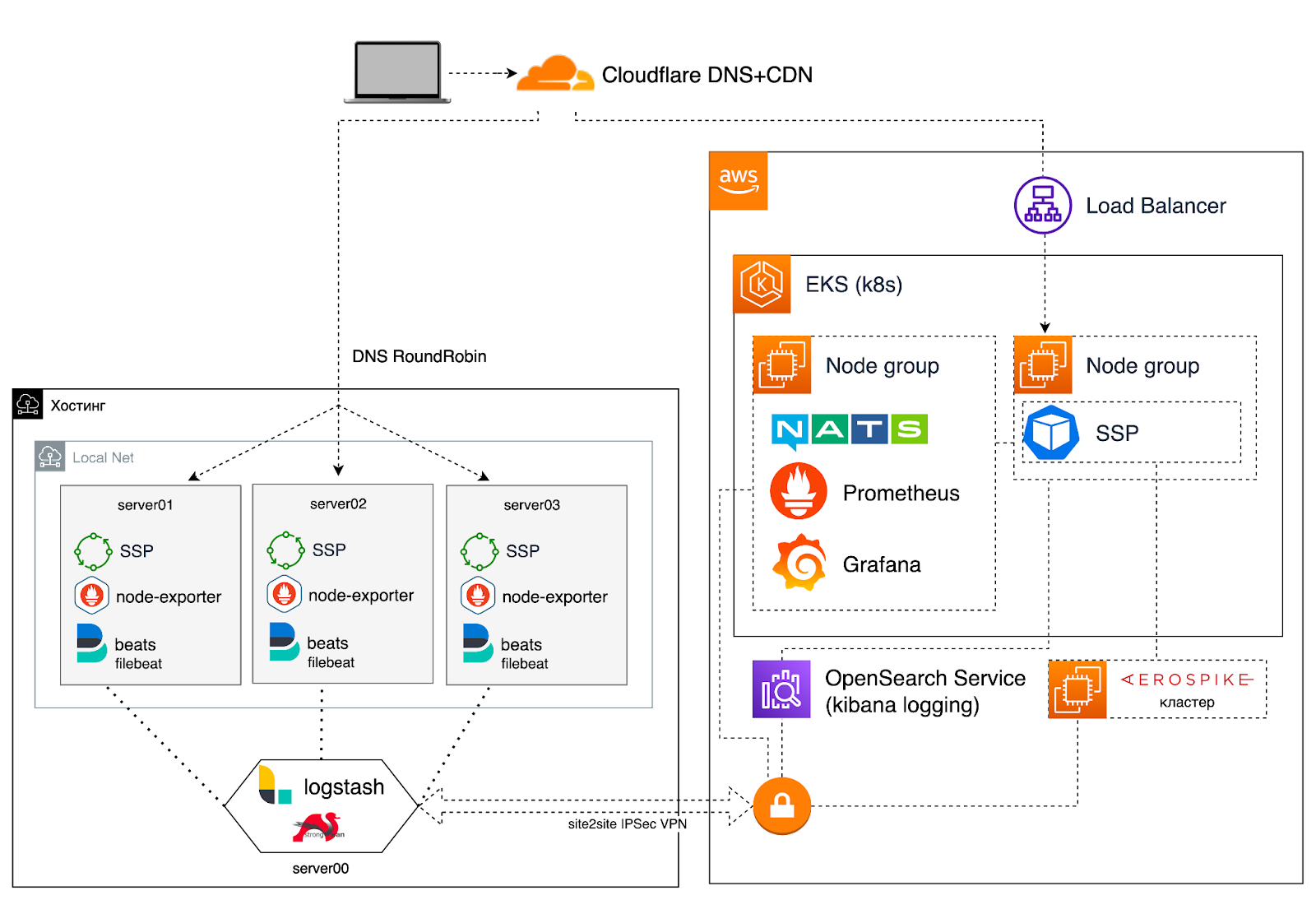
The system already used CloudFlare DNS + CDN as DNS hosting, included an additional feature for traffic balancing to distribute traffic between the data center and AWS. Traffic shares are distributed as a percentage, settings can be changed via API;
Described and automated the process of adding a new server on the hosting side;
Raised a server with VPN Site-to-Site to interact with services in a cloud provider (Aerospike, Prometheus metrics, logging, Kinesis Firehose, NATS);
Since scaling resources in the data center is a rather long process, and the number of available servers will not be able to stably process bursts of traffic, we need to be able to transfer the share of traffic to resources in AWS;
We added a dynamic change in the API of distribution of the share of traffic between the data center and AWS depending on incoming traffic (QPS) or the use of hardware resources based on metrics (CPU and Memory) in Prometheus. The Prometheus hook runs a Lambda function and, based on the metrics, the function updates the traffic share distribution settings in CloudFlare. We also added an anomaly detection algorithm to track unexpected rapid changes in indicators;
Updated dashboards in Grafana with hybrid architecture in mind. Added the ability to view metrics for the data center and / or AWS;
We updated the deployment system taking into account the hybrid architecture (we implemented a simple analogue of blue green deployment: we update one environment, then switch to it, then we update another environment);
As a result of 2 months of operating the hybrid architecture in production, rough calculations show that we saved 50 to 60% of the monthly infrastructure budget.
I invite you to discuss the case in the comments and share your experience with architecture.