Cost-effective configuration of Apache Spark executors
Hello, Habr! On the eve of the start of the course “Ecosystem Hadoop, Spark, Hive” prepared a translation of a useful article for you. We also offer to watch a free recording of a demo lesson on the topic: “Spark 3.0: What’s New?”…
We are looking for the most optimal configuration of executors for your site
Number of CPUs per node
The first stage in determining the optimal configuration of performers (executor) is to figure out how many actual CPUs (i.e. non-vCPUs) are available on the nodes (node) in your cluster. To do this, you need to find out what type of EC2 instance your cluster is using. In this article, we will be using r5.4xlarge which, according to AWS EC2 Instance Pricing, has 16 processors.
When we run our tasks (job), we need to reserve one processor for operating system and cluster management systems (Cluster Manager)… Therefore, we would not like to use all 16 CPUs for the task at once. That way, when Spark computes, we only have 15 CPUs available for allocation at each node.
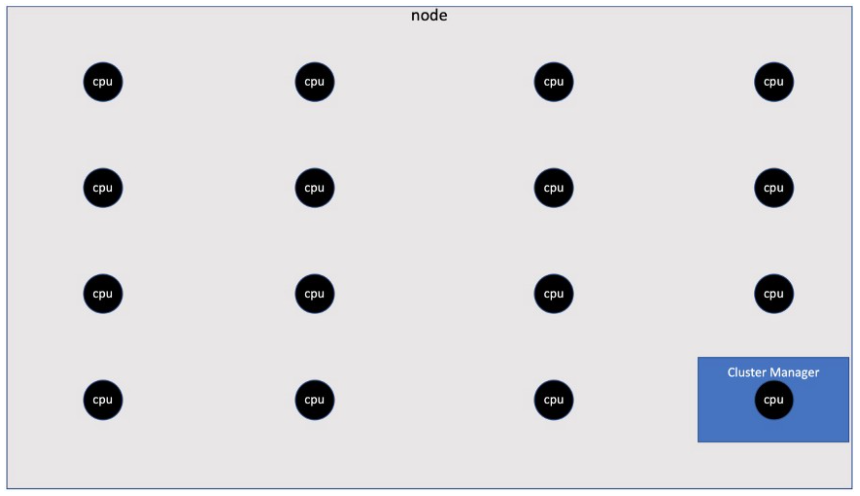
Number of CPUs per performer
Now that we know how much CPU is available for use on each node, we need to determine how many cores (core) Spark we want to assign to each performer. Using basic math (X * Y = 15), we can calculate that there are four different combinations of cores and executors that might work for our case with 15 Spark cores per node:

Let’s explore the feasibility of each of these configurations.
One performer with fifteen cores
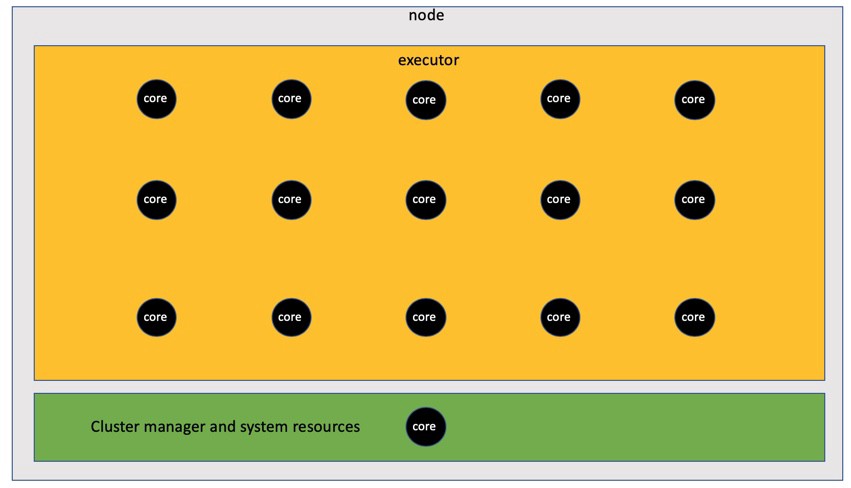
The most obvious solution that comes to mind is to create one performer with 15 cores. The problem with big fat runners like this is that a runner supporting that many cores will usually have such a large memory pool (64GB +) that garbage collection delays will unnecessarily slow you down. Therefore, we immediately exclude this configuration.
Fifteen single core executors

The next obvious solution that comes to mind is to create 15 performers, each with only one core. The problem here is that single-core executors are inefficient because they don’t take advantage of the parallelism that multiple cores provide within a single executor. Also, finding the optimal memory size for single-core executors can be difficult. Let’s talk a little about memory overhead.
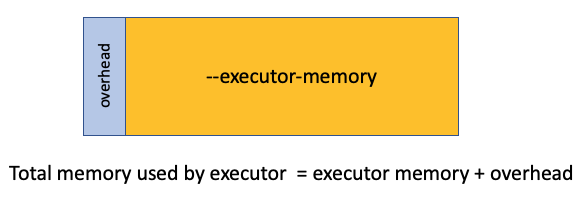
The default executor memory overhead is 10% of the memory allocated to your executor, or 384 MB, whichever is greater. However, on some big data platforms such as Qubole, the overhead is fixed at a certain default value, regardless of the size of your artist. You can check your overhead metric by going to the Environments tab in the Spark log and searching for the parameter spark.executor.memoryOverhead…
The default memory overhead in Spark will be very small, which will result in problems with your tasks. On the other hand, a fixed amount of overhead for all performers will result in too much overhead and, therefore, leave less room for the performers themselves. It is difficult to find the ideal memory size, so this is another reason why a single-core executor is not suitable for us.
Five performers with three cores or three performers with five cores
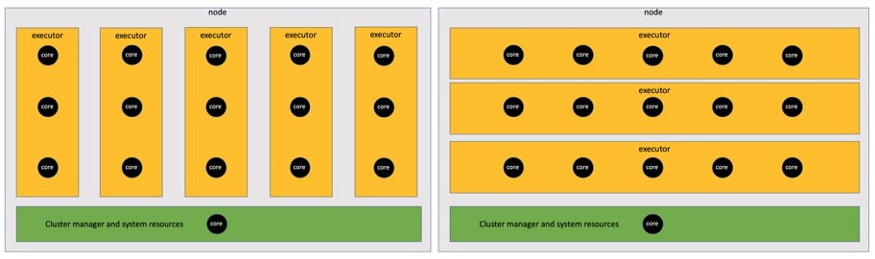
So we are left with two options. Most Spark tuning guides agree that 5 cores per worker is the optimal number of cores in terms of parallel processing. And I also came to the conclusion that this is true, including on the basis of my own research in optimization. Another advantage of using five-core executors over tri-core ones is that fewer executors per node require less overhead. Therefore, we will focus on five-core executors to minimize memory overhead on the node and maximize parallelism within each executor.
--executor-cores 5Memory per node
Our next step is to determine how much memory to assign to each performer. Before we can do this, we must determine how much physical memory on our node is available to us at all. This is important because physical memory is a hard limit for your performers. If you know which EC2 instance you are using, then you also know the total amount of memory available on the node. About our instance r5.4xlarge AWS reports that it has 128GB of available storage.
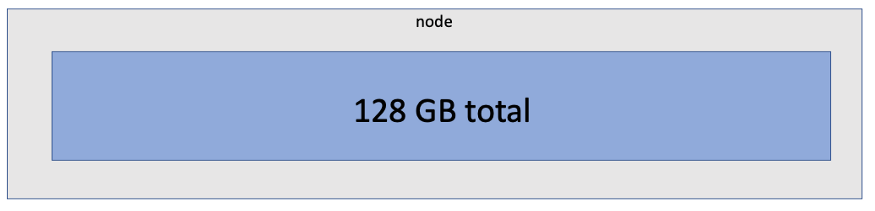
However, not all 128 GB will be available for use by your performers, since memory will also need to be allocated for your cluster management systems… The figure below shows where in YARN to look for how much memory is available for use after memory has been allocated to the cluster management system.
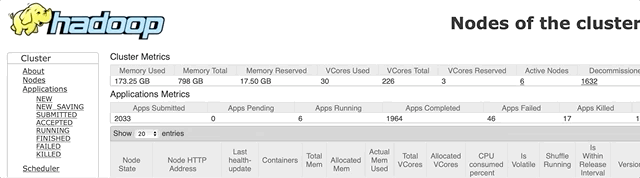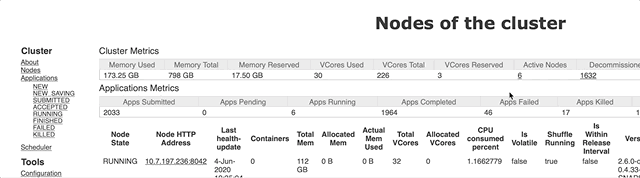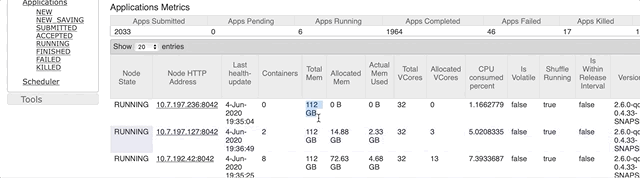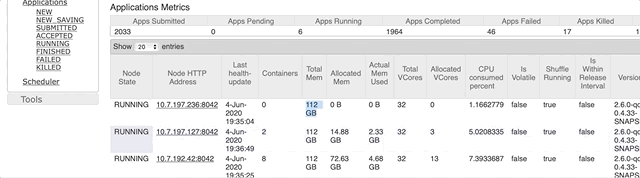
We see that 112 GB is available to the performers on the nodes of this cluster.

Memory capacity per artist
If we want three performers to use 112 GB of available memory, then we need to determine the optimal memory size for each performer. To calculate the amount of memory available to the executor, we simply divide the available memory by 3. Then we subtract the memory overhead and round to the nearest integer.
If you have a fixed memory (as is the case with Qubole), you will use this formula. (112/3) = 37-2.3 = 34.7 = 34.
If you are using Spark’s default method to calculate memory overhead, you will use this formula. (112/3) = 37 / 1.1 = 33.6 = 33.
For the rest of this article, we will use a fixed amount of memory overhead for Qubole.
--executor-memory 34GTo really start saving, seasoned Spark tuners need the next paradigm shift. I recommend that you use a fixed memory size and number of cores in your executors for all tasks.… I understand that using a fixed executor configuration for most Spark tasks seems contrary to good Spark tuning practice. Even if you are skeptical, I ask you to try this strategy out to make sure it works. Figure out how to calculate the cost of completing your task, as described in Part 2, and then put it to the test. I believe that if you do this, you will find that the only way to achieve effective cloud economy is to use fixed memory sizes for your performers. which make optimal use of the CPU.
With that said, if you’re running out of memory when using effective memory for your performers, consider moving your process to a different EC2 instance type that has less memory on the host CPU. This instance will cost you less and therefore help reduce the cost of completing your task.
Finally, there will be times when this economical configuration won’t provide enough bandwidth for your data in your performer. In the examples given in second part, there were several tasks in which I had to move away from using the optimal memory size, because the memory load was maximum during the entire task execution.
In this guide, I still recommend that you start with the optimal memory size when migrating your tasks. If you run into memory errors with an optimal executor configuration, I will share configurations that avoid these errors later in Part 5…
Number of performers per task
Now that we have decided on the worker configuration, we are ready to set up the number of workers we want to use for our task. Remember, our goal is to make sure all 15 available CPUs per node are being used, which means that we want to have three workers assigned to each node. If we set the number of our performers to a multiple of 3, we will achieve our goal.

However, there is one problem with this configuration. We also need to assign a driver to handle all the artists in the node. If we use a multiple of 3 executors, then our single-core driver will be hosted in its own 16-core node, which means that as many as 14 cores on this last node will not be used during the entire task execution. It’s not a good practice to use the cloud!

The point I want to convey here is that the ideal number of performers should be a multiple of 3 minus one performer to make room for our driver.

--num-executors (3x - 1)IN Part 4 I will give you guidance on how many workers you should use when migrating an existing task to a lean worker configuration.
Memory per driver
It is common practice for data engineers to allocate a relatively small amount of memory for the driver compared to executors. but AWS actually recommends that you set your driver memory size the same as your executors… I found it to be very helpful in cost optimization as well.
--driver-memory 34GIn rare cases, situations may arise when you need a driver whose memory is larger than that of the executor. In such cases, set the driver memory size to 2 times the executor memory, and then use the formula (3x – 2) to determine the number of executors for your task.
Number of cores per driver
By default, the number of cores per driver is one. However, I have found that tasks using more than 500 Spark cores can improve performance if the number of cores per driver is set to match the number of cores per executor. However, do not immediately change the default number of cores in the driver. Just test it out on your biggest tasks to see if you see the performance gains.
--driver-cores 5Is the configuration universal?
Thus, the executor configuration I recommend for a node with 16 processors and 128 GB of memory would look like this.
--driver-memory 34G --executor-memory 34G --num-executors (3x - 1) --executor-cores 5But remember:
There are no universal configurations – just keep experimenting and sooner or later you will find a configuration that is perfect for your needs.

As I mentioned above, this configuration may not seem appropriate for your specific needs. I recommend that you use this configuration as a starting point in your cost optimization process. If you are having memory problems with this configuration, in the next installments of this series I will recommend configurations that will solve most of the memory problems encountered when switching to economy configurations.
Since the node configuration used in this article is fairly common in the Expedia Group ™, I will refer to it throughout the rest of the series. If your nodes are of a different size, you should use the method I have outlined here to determine the ideal configuration.
Now that you have an optimal economical performer configuration, you can try migrating your current tasks to it. But what tasks should you shift first? And how many executors should you run with this new configuration? But what happens if a cost-optimized task takes longer to complete than an unoptimized task? And is excess CPU usage ever appropriate? I will answer these questions in Part 4: How to Migrate Existing Apache Spark Tasks to Lean Runner Configurations…
You can learn more about the course “Ecosystem Hadoop, Spark, Hive” here… You can also watch a recording of an open lesson “Spark 3.0: What’s New?”
Read more:
How to debug requests using only Spark UI






One Comment