About one test task
Recently Youtube (*a site that violates the law of the Russian Federation) recommended me a video that was curious from various angles. It dealt with a task that, according to the author, was given to an acquaintance of his at an interview for a job at Apple. His friend could not solve this problem.
The task itself is this. We have a data structure that is a singly linked list. Each node of the list contains its unique number (not necessarily in the order of list connectivity) and a pointer to the next node. It is necessary to determine whether there is a cycle in this list (obviously, there can be at most one cycle in a singly linked list) and if so, print the number of the first node of this cycle in the order of traversal of the list.
This was illustrated by the following picture:
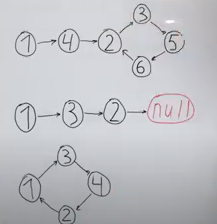
Obviously, in these three options, the answers will be, respectively, “2”, “no” and “1”.
Here, readers are invited to come up with their own algorithm, while looking at the picture to attract attention.

The next step was a hint to the viewers in the video: if someone came up with the idea of storing the passed nodes in some kind of data structure and checking each new node for the presence in this structure, then such a solution is bad, since the algorithm should not require O (n) additional memory.

The following turned out to be a real shock for me: more than half of the commentators who noted under the video not only could not find a solution with the indicated restriction, but generally considered such a task to have unbearable complexity and devoid of practical meaning. According to these people, this task far exceeds in its complexity anything that a programmer could ever need in life.
This was the first thing I would like to share with readers. I just can’t keep that kind of knowledge to myself. My ideas about the typical level of people who are professionally engaged in programming have changed a lot. Of course, not everyone watches such videos, but not everyone, for sure, found the courage to write that they do not understand anything.
Now let’s move on to the solution of the problem proposed by the author of the video (and, apparently, reported to Apple by an unsuccessful applicant).
It is proposed to have two pointers according to the “tortoise and rabbit” scheme, the first of which advances from the beginning of the list at a rate of 1 knot per step, and the second at a rate of 2 knots per step. If the list is linear, then the second pointer will sooner or later reach its end, and if it is cyclic, then the pointers will meet sooner or later. Further, by more subtle reasoning, it can be shown that after the meeting, if two pointers are advanced 1 node per step, starting from the beginning of the list and from the meeting point, respectively, then these pointers will meet at the beginning of the cycle.
This is a very ingenious algorithm, but is it justified? Here, in the comments, disputes unfolded between that part of the thinking minority, which independently came to the same algorithm, and another part of the thinking minority, which proposes to mark the nodes.
Indeed, a simpler solution in the proposed formulation of the problem would be this. Use one pointer, and in each passed node change, for example, the value of the number to negative. As soon as we met a negative number, this is the first node of the cycle. If for some reason we do not want to sacrifice the sign bit of the node number, then we can use, for example, the low or high bit of the pointer to the next node.
If we need to save the list in its original form (which, note, nothing is said in the problem statement), then we can make an additional pass to restore our bits.
Of course, there is some internal resistance to modifying the list passed as an input parameter. But note that classics like Knuth and Dijkstra often taught programming in this way, giving algorithms with temporary reversal of the direction of connections and similar tricks.
Let’s compare the performance of the turtle-bunny algorithm and the labeled algorithm.
The rabbit-turtle algorithm does not guarantee that the pointers will meet on the first turn of the loop, a fast pointer may first jump over a slow one. Therefore, we may have an extra pass through the cycle. Since we need to pass two pointers through the list, the number of memory access and check operations on average is somewhere around 2 * N + 2 * L, where N is the length of the list, and L is the length of the cycle. All these will be read operations.
The labeled algorithm requires only one pointer and is guaranteed to find the start of the loop right away, so the number of memory accesses and checks will be N if we don’t restore the list, and 2*N if we do. But access in this case consists of reading and writing.
Let’s test our ideas in practice. Let’s program algorithms in C language. In the algorithm of the rabbit and the turtle, let’s make life a little easier for ourselves and start moving the pointers immediately from the second step, so as not to burden the check in the loop with the initial equality of the pointers. For simplicity, the negative answer is denoted by the vertex number 0.
Rabbit and turtle algorithm:
#include <stdio.h>
#include <time.h>
int main () {
#define SIZE 100000000
struct Node {
long num;
struct Node *next;
};
static struct Node array [SIZE];
long i, time1, time2, loopnode;
struct Node *ptr1, *ptr2;
for (i=0; i<SIZE-1; i++) {
array [i].num = i+1;
array [i].next = &array[i+1];
}
array [SIZE-1].num = SIZE-1;
array [SIZE-1].next = &array[1];
time1 = clock();
ptr1 = &array[1];
ptr2 = &array[2];
while ((ptr2 != NULL) &&
(ptr2->next != NULL) &&
(ptr1 != ptr2)) {
ptr1 = ptr1->next;
ptr2 = ptr2->next->next;
}
if (ptr1 != ptr2)
loopnode = 0;
else {
ptr1 = &array[0];
while (ptr1 != ptr2) {
ptr1 = ptr1->next;
ptr2 = ptr2->next;
}
loopnode = ptr1->num;
}
time2 = clock();
printf ("Loopnode is %ld, time is %ld\n",
loopnode, time2-time1);
return 0;
}Algorithm with labeling:
#include <stdio.h>
#include <time.h>
int main () {
#define SIZE 100000000
#define RESTORE Y
struct Node {
long num;
struct Node *next;
};
static struct Node array [SIZE];
long i, time1, time2, loopnode;
struct Node *ptr1, *ptr2;
for (i=0; i<SIZE-1; i++) {
array [i].num = i+1;
array [i].next = &array[i+1];
}
array [SIZE-1].num = SIZE-1;
array [SIZE-1].next = &array[1];
time1 = clock();
ptr1 = &array[0];
while ((ptr1->num > 0) && (ptr1->next != NULL)) {
ptr1->num = -ptr1->num;
ptr1 = ptr1->next;
}
if (ptr1->next == NULL)
loopnode = 0;
else
loopnode = -ptr1->num;
#ifdef RESTORE
ptr1 = &array [0];
while ((ptr1->num < 0) && (ptr1->next != NULL)) {
ptr1->num = -ptr1->num;
ptr1 = ptr1->next;
}
#endif
time2 = clock();
printf ("Loopnode is %ld, time is %ld\n",
loopnode, time2-time1);
return 0;
}Let’s compile them using Apple clang 14.0.3 and calculate the execution time on a Mac mini with an Intel Core i3 3.6 GHz processor.
optimization -O0 | -O3 optimization | |
Rabbit and turtle | 522082 | 347758 |
Recovery Marking | 726725 | 340528 |
Marking without recovery | 363929 | 171820 |
Thus, a simpler labeling algorithm with recovery is not only not significantly inferior to the rabbit and tortoise in terms of performance, but also surpasses it in some cases. And marking without restoration is twice better than a rabbit and a turtle (since one turtle has to pay a salary).
What thoughts do readers have on this matter?





