Why does Chat GPT speak Russian with a neural accent? The specifics of Cyrillic tokenization by a neural network from Open AI
Speaking simply and briefly, she receives a set of tokens as input, passes them through a certain “black box” and issues another set of tokens. The probability of choosing a particular token for a response depends on the set of incoming tokens and specific settings.
But what is a “token”? An interesting fact is that for the English language, the token is usually a combination of characters, often coinciding with short words or frequently occurring parts of words.
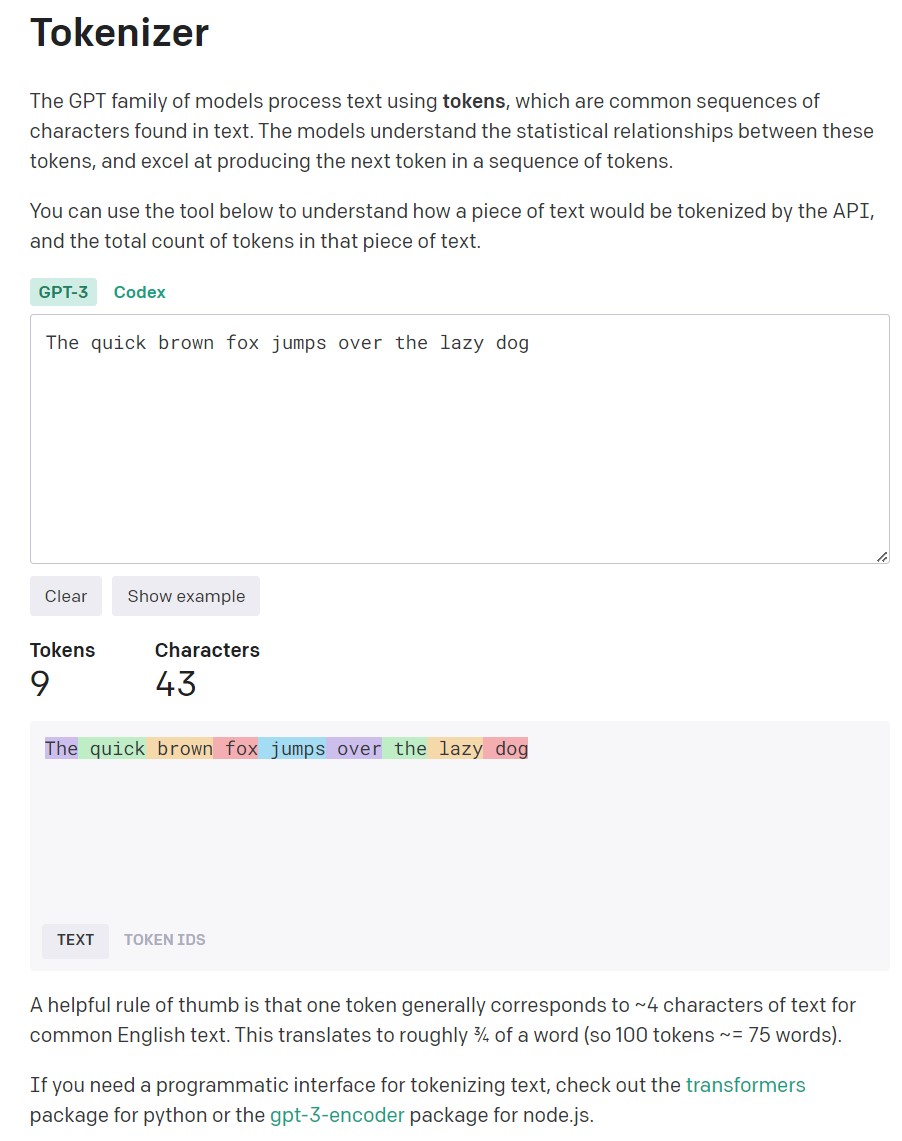
Take, for example, the English pangram:
“The quick brown fox jumps over the lazy dog”
Let me remind you that a pangram is a sentence of the minimum number of words, containing all the letters of the alphabet.
Official Open AI tokenizer
Indicates that this sentence has a total of 9 tokens containing 43 characters.
However, with the Russian language, the Open AI tokenizer works in a completely different way.
Popular pangram of the Russian alphabet:
“Eat some more of those soft French buns and have some tea”
It contains 53 characters, but the Open AI tokenizer needs 70 (Sic!) tokens to “pack” this phrase.

It turns out that Chat GPT answers questions in English by words, and it answers questions in Russian by letters.
In fact, it turns out that when communicating in Russian, the GPT chat somehow skips one additional layer of connectivity. All the more surprising is his ability to generate a meaningful answer in Russian, even spelling.
By the way, it is important to take into account the specifics of toning the Russian language when using the Open AI API and when working in its sandbox.
Be especially careful when using the “Frequency penalty” (FP) parameter, which adjusts the probability of repeating tokens that have already been used.
As conceived by the creators of “Frequency penalty” – reduces the likelihood of reusing the word in the response of the neural network.
However, what works with English text does not work with Russian, as simply repeating the use of letters begins to be penalized. And the neural network has to go to tricks, replacing Russian letters with Latin letters, and then with the entire ASCII set.
For example, the seed “Once in a cold winter time” in combination with the temperature set to 0, naturally gives the expected Nekrasov quatrain, and only then small fantasies begin.
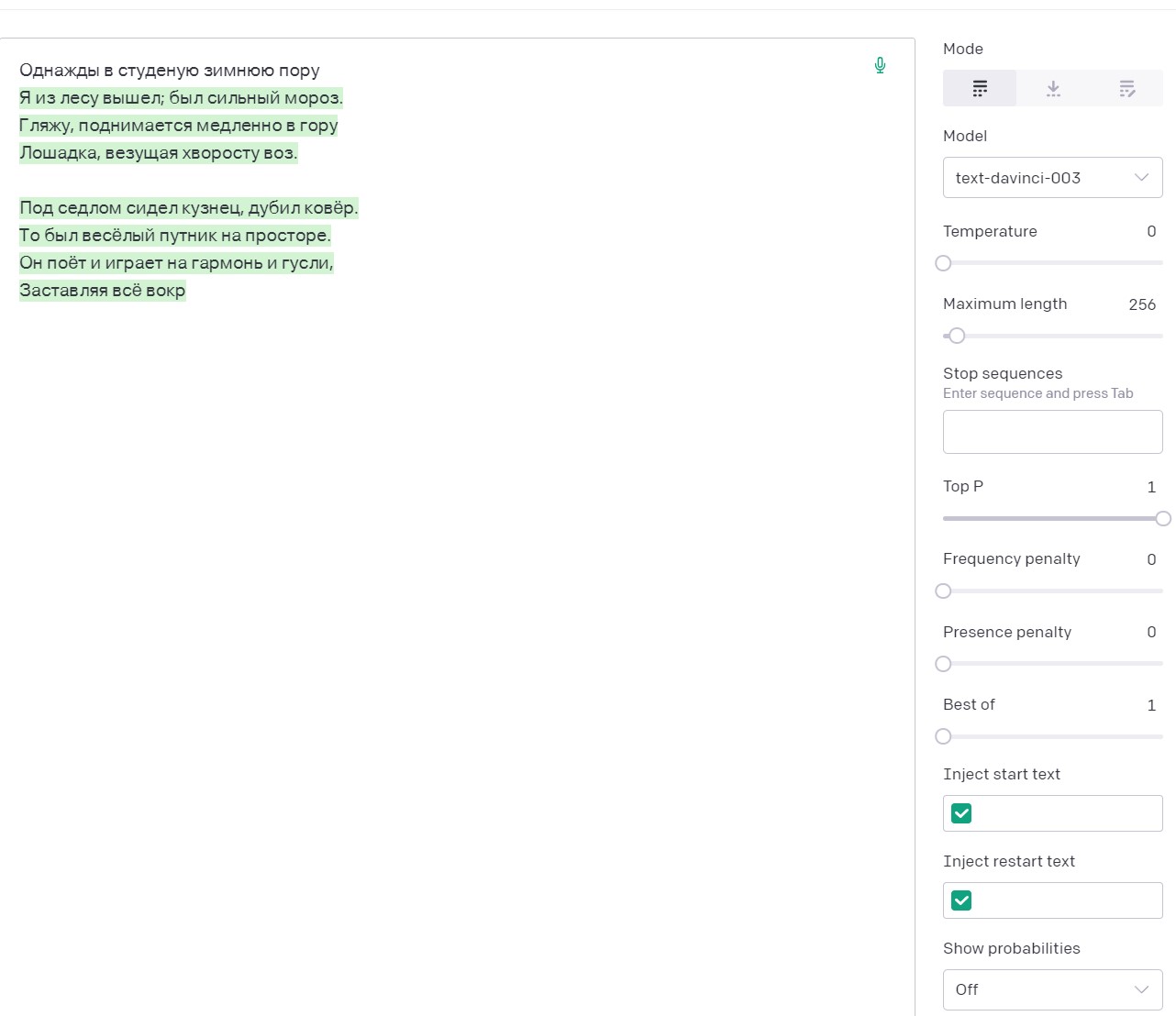
The same seed with FP=2, at first also recalls Nekrasov, but then quickly switches to Latin.
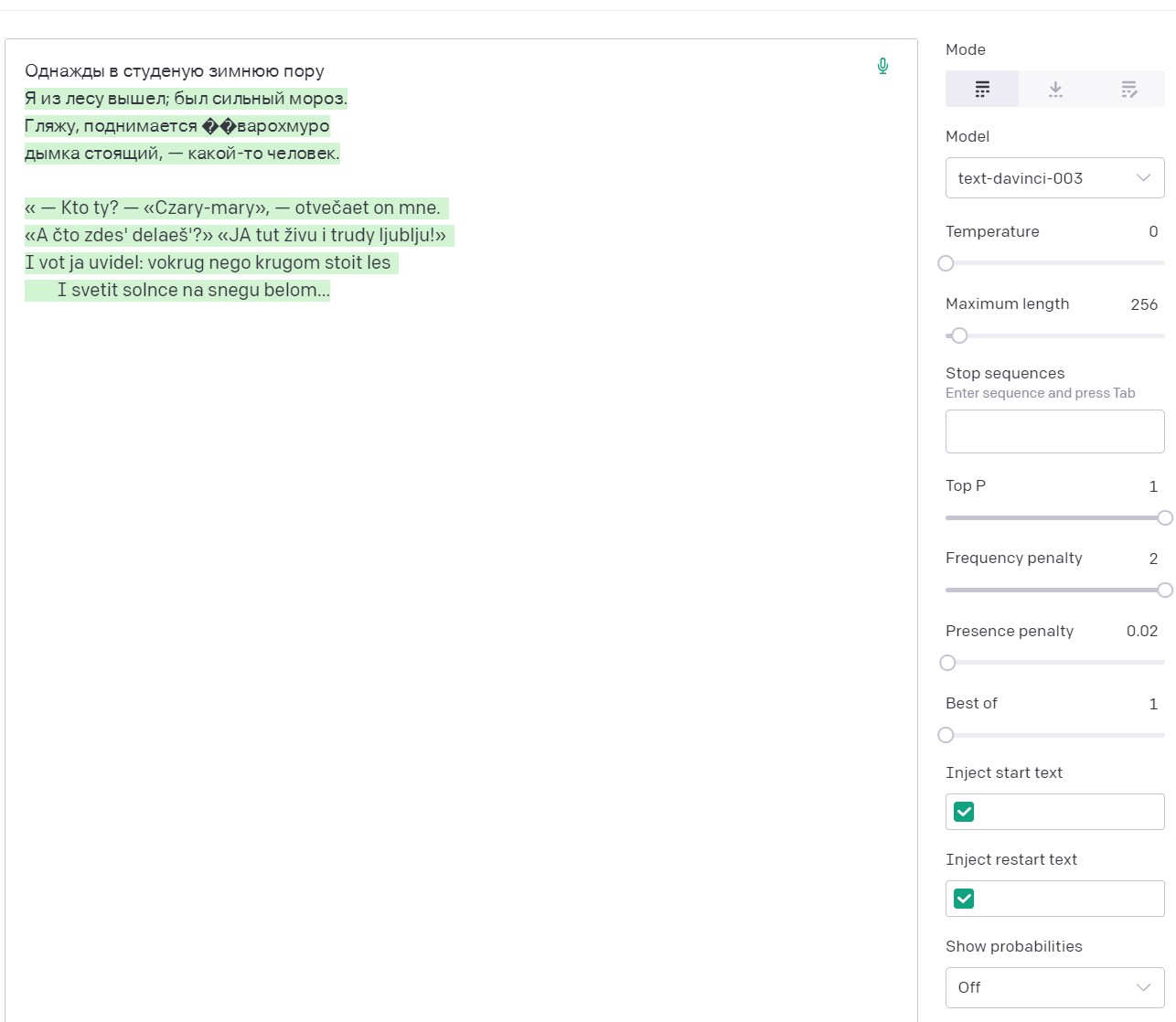
In general, this situation helps us understand the specifics of how a neural network understands questions and generates answers.
And, of course, it becomes clear why the neural network from Open AI has a neural accent. Words in Russian have declensions, conjugations and agreements in gender, number, tense, etc., which are formed primarily due to endings. And often in a borderline situation, the probability of a particular letter in the ending for a neural network fluctuates approximately at the same level. And she makes forgivable mistakes for a foreigner.
By the way, for a better understanding of the specifics of selecting the next Open AI token, you can enable the option to show the probabilities of answers Show probabilities -> Full spectrum in the sandbox, which will show the five most probable options for the next token with its specific probability.
It can be seen that with a seed:
“AI is good”
The probability that the letter “sh” is followed by the token “o” is almost 42%
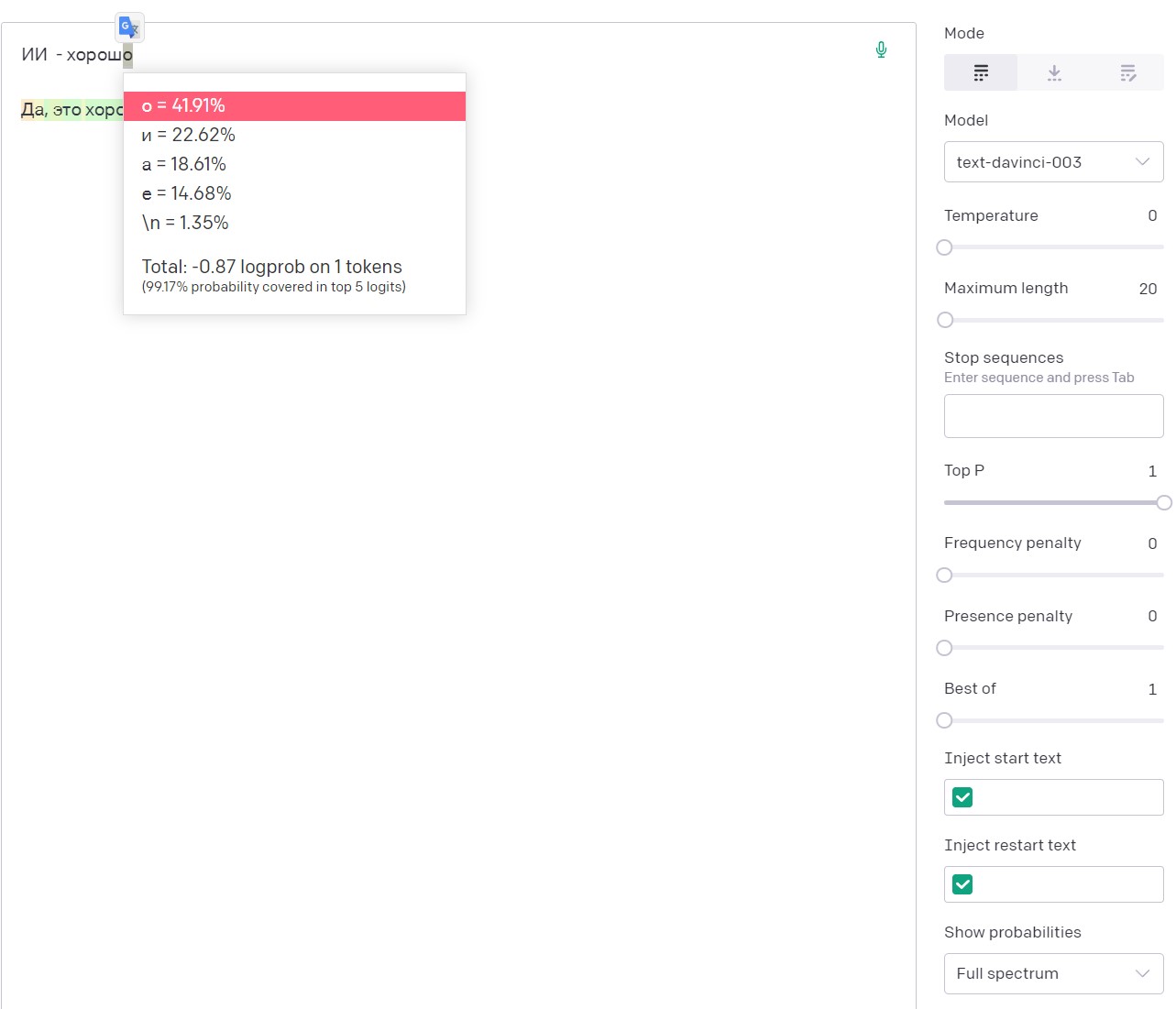
So, we can sum up. The specificity of answers in Russian generated by the GPT-3.5 neural network from Open AI is primarily due not to the sample size, but to the approach to tokenization of the Cyrillic text. When working with the network, and in particular with its API, you need to take into account that when tokenizing the Russian language, one character <= 1 token. This leads to a rapid depletion of the token limit and makes some settings (in particular FP) extremely sensitive.
The most pressing question remains: To what extent do the features of Russian language tokenization affect the work with the meaning of the text?
Namely:
At what level does a neural network have a meaningful response? (Of course, not in the sense that she understands it, but in the fact that a semantic construction adequate to the question arises within the network)
That is, does the neural network first form the meaning of the answer, and only then translate it into the answer language (English or Russian)?
Or does meaning appear directly in the process of answering?
Obviously, in the first case, the depth and meaningfulness of the answers in different languages will not differ. And in the second case, we can expect a change in the quality of the semantic content of the answer, depending on the language in which the model responds.
So far, I haven’t come to a definite conclusion. It is only clear that in English the chat responds faster and more correctly in terms of grammar. But this is fully explained by the specifics of tokenization in Open AI.
I would be grateful for your opinions on this matter.