QCon Conference. Mastering Chaos: Netflix’s Guide to Microservices. Part 3
QCon Conference. Mastering Chaos: Netflix’s Guide to Microservices. Part 1
QCon Conference. Mastering Chaos: Netflix’s Guide to Microservices. Part 2
Auto-scaling groups will help restore the network. I am sure that you are familiar with it, but I must emphasize its fundamental nature and extreme importance for launching microservices in a cloud environment.

You have a minimum and a maximum, there are metrics that you use when you grow your group. If you need a new instance, you simply pull and unwind any image from S3. There are a number of advantages to this. The first is the efficient use of computer capacities, as you change them on demand. Failed nodes are easily replaced by new ones. But the most important thing is that when traffic spikes, for example, during DDoS attacks or due to performance errors, auto-scaling allows you to keep the system operational while you deal with the causes and troubleshoot problems. I highly recommend using this scaling because it has repeatedly saved us from major glitches.
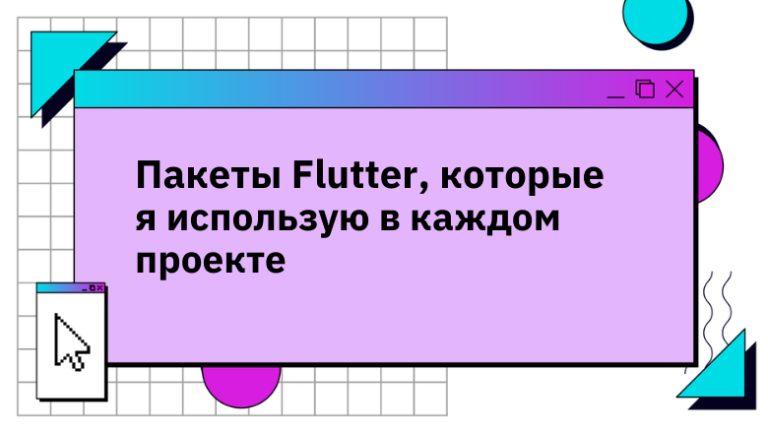
And of course, you want to make sure that it works continuously with Chaos. The Chaos Monkey Chaos Monkey is our tool that randomly destroys AWS instances or processes on servers that run Netflix. This tool confirms that if one of the nodes the node “dies”, then everything else continues to work without problems. After the implementation of Chaos Monkey, we were able to make sure that all nodes have excessive duplication around the clock, the fall of one node does not lead to any consequences, and each problem is documented so that a ready-made solution can be applied to fix it later.
Let’s look at what Stateful services are. These are databases, caches, and user applications that use internal caches with large amounts of data. When we implemented a multi-regional architecture and tried to use common data replication strategies, such applications created a big problem. Therefore, I strongly recommend that you avoid storing your business logic and states within the same application whenever possible. Stateful services are characterized in that the loss of one node is a significant event for the system. Replacing this node with a new one may take several hours.
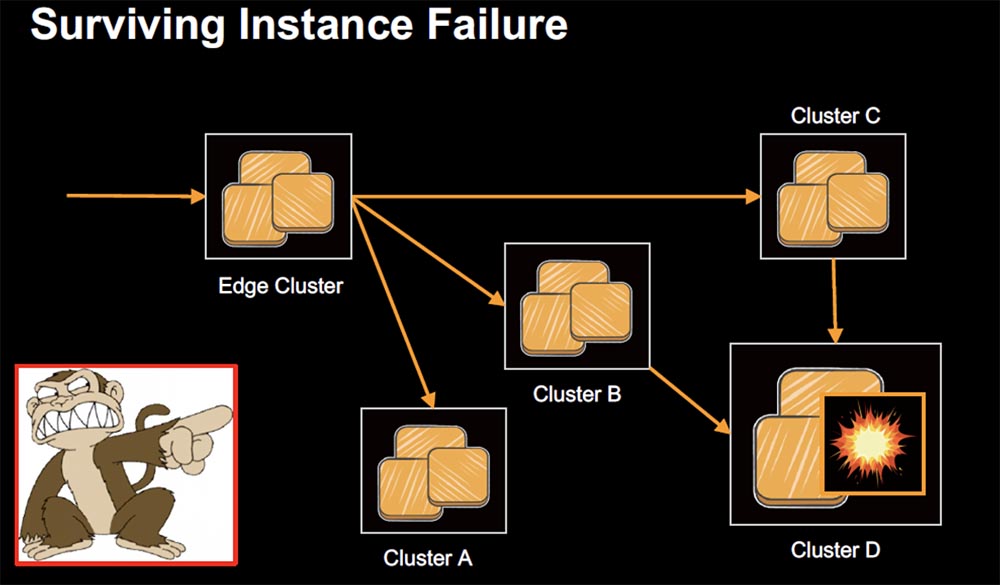
There are two different approaches to caching. As I already said, former Yahoo employees who had extensive experience working with ha-proxy caches joined our team. They used a template from dedicated servers for users. That is, the user always got to the same node where the cache was located with a single copy of the data. The problem was that when this node broke down, the user lost access to the entire service. In the early stages of the existence of the service, even before the implementation of HYSTRIX, there were situations when the failure of one node crashed the entire Netflix service. The troubleshooting took 3.5 hours, during which we waited for the cache to fill itself so that the request could be completed.
The next slide shows the Dedicated Shards highlighted segment diagram, which is a refusal to use a custom dedicated server template.
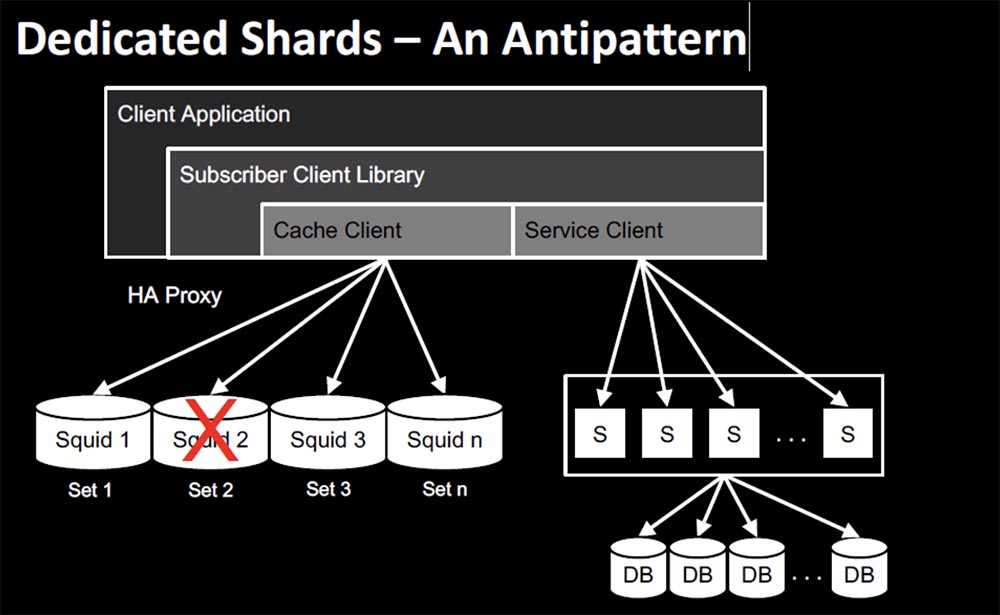
Returning to biology, we can say that redundancy is a fundamental factor. We have two kidneys, and if one fails, we can live off the other, we have two lungs, but we can exist with one. Netflix approached problem solving using the principle of human body architecture. We can’t increase the load, but we can live on one of the “organs”.
The main technology in this scenario is recording sharing in EVCache. Data is written not only to several nodes, but also to several availability zones. Reading from them occurs locally, but again, the application can read from several zones, if necessary.
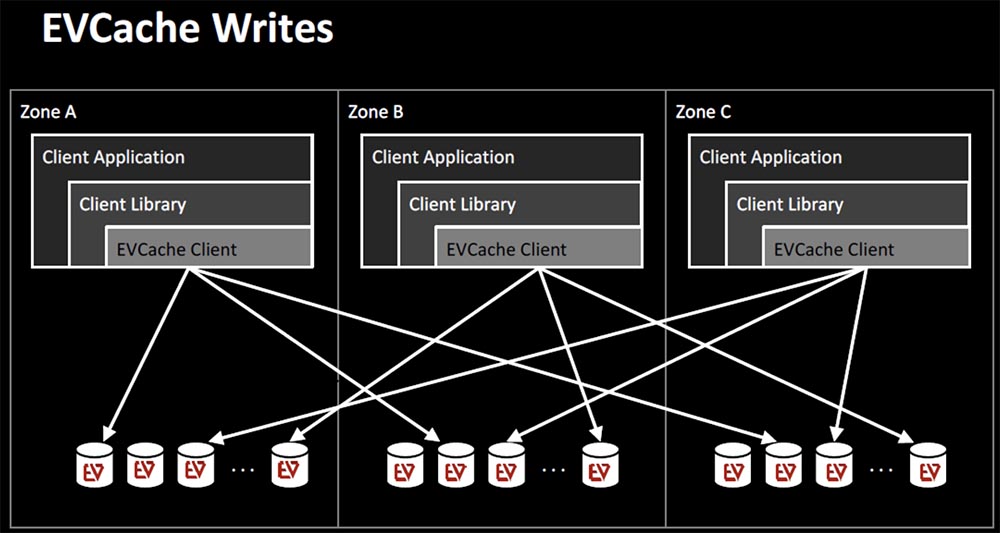
This is a very successful model that almost every Netflix virtual service uses.
Let’s talk about hybrid services, which are a combination of stateless and stateful services. In this case, it is very easy to use EVCache as the most suitable fault tolerance technology.
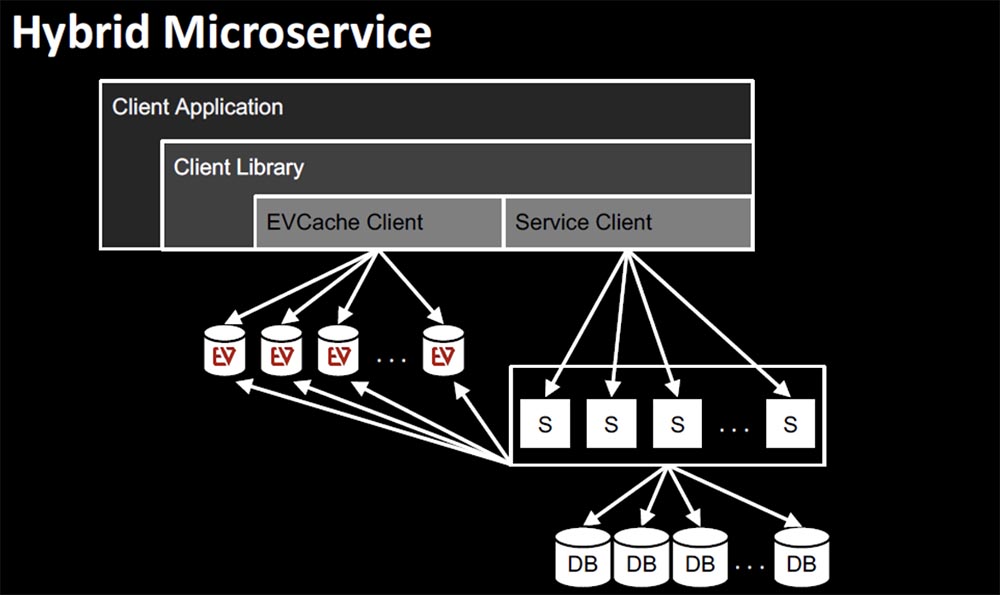
It allows you to process 30 million requests per second, which is 2 trillion requests per day. Hundreds of billions of objects and tens of thousands of memcashed instances can be stored in EVCache. A huge advantage of this architecture is linear scalability, so queries are returned within a few milliseconds regardless of load. Of course, you need to create enough nodes, but the scaling process itself is extremely simple.

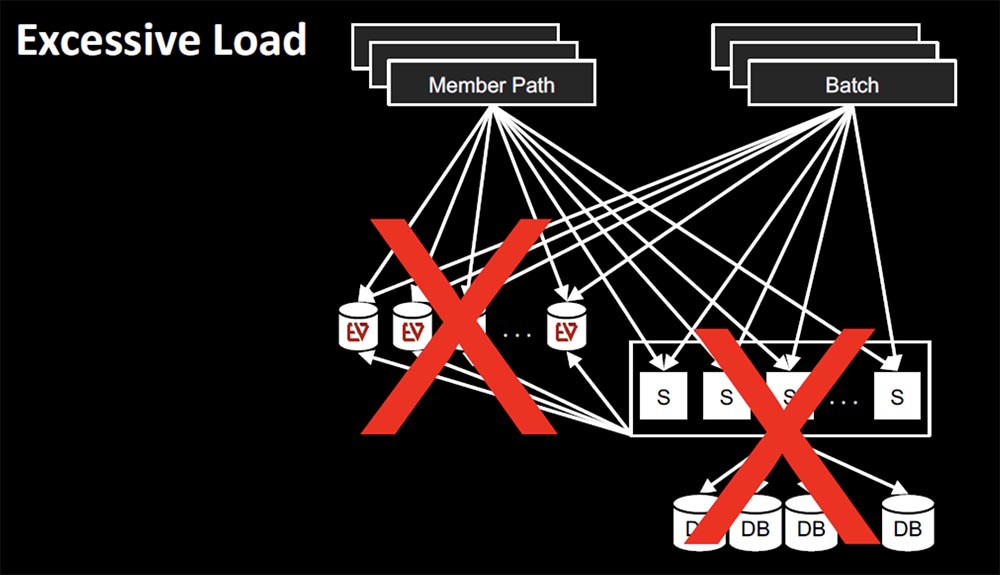
A few years ago, we used a scenario where our Subscribers service relied on EVCache to a somewhat greater extent than was necessary, that is, there was an antipattern that we already spoke about. Almost all other services accessed Subscribers. I mean, everyone wanted to know about him, everyone needed a client ID, how to get access to accounts and other information. All offline and online calls came in the same cluster.
In many cases, there were multiple calls to the same application, it turned out that you could call EVCache as often as you wanted, and at the peak of activity we observed from 800 thousand to a million requests per second. Fallback would be logical if you think about it in a momentary aspect: if the cache failed, give me the opportunity to call the service. However, there was a problem with Fallback: when the entire EVCache level crashed, then all requests came to the service and the database and an antipattern occurred – the database service could not cope with the load that EVCache took upon itself. It turned out that the seemingly correct approach also led to failure – the failure of EVCache caused the failure of the entire Subscribers service.
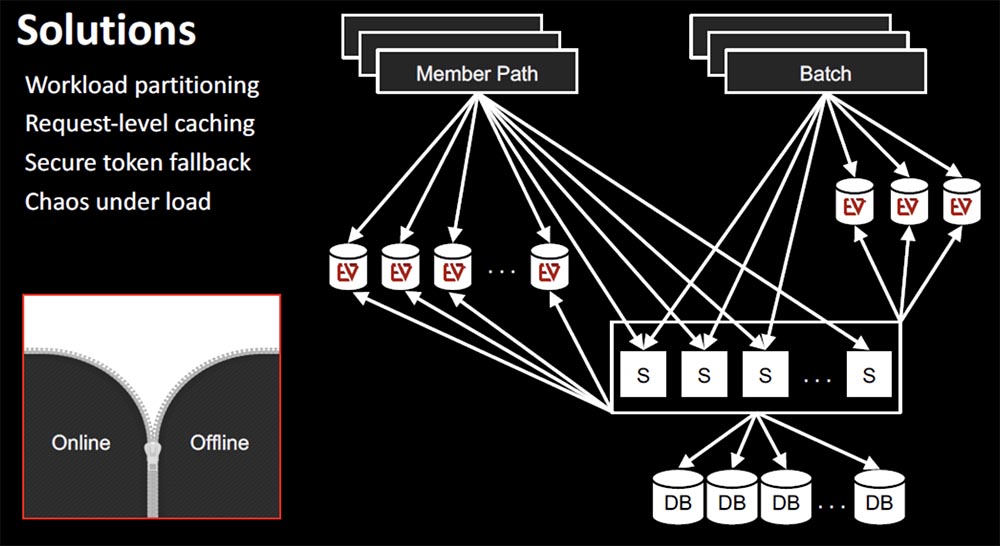
The solution to this problem is complex:
- stop “swotting” of the same cluster of the system with offline requests and calls in real time, dividing the workload into online and offline segments;
- organize Request-level cashing, that is, always bind the write life cycle to the current request area, so that it becomes impossible to call the same service again and again;
- Embedding Fallback security tokens on users’ devices.
The latter is what we do not have yet and what will be implemented in the near future. If the client accesses the Subscribers service when it is unavailable, Fallback will be carried out to the data stored in this encrypted token. The token contains enough information to identify the user and provide him with the opportunity to perform basic operations to use our service.
Consider the variations – various options for the architecture of the service. The more of these options, the more you can solve the problems that arise when the system is scaled up, Operational drift operational deviations, in which operational indicators differ from the basic indicators of the service, or when introducing new languages or containers.
Operational drift is the inevitable aging of various factors of maintaining a complex system, which happens unintentionally. Deviations are expressed in the periodic occurrence of threshold loads, timeouts, delays, and a drop in performance when adding new functionality. However, manual labor to fix problems in this area is not particularly effective and often requires the repetition of the same manipulations with slight differences in the source data. We can say that this process is based on the sheer enthusiasm of the development team.
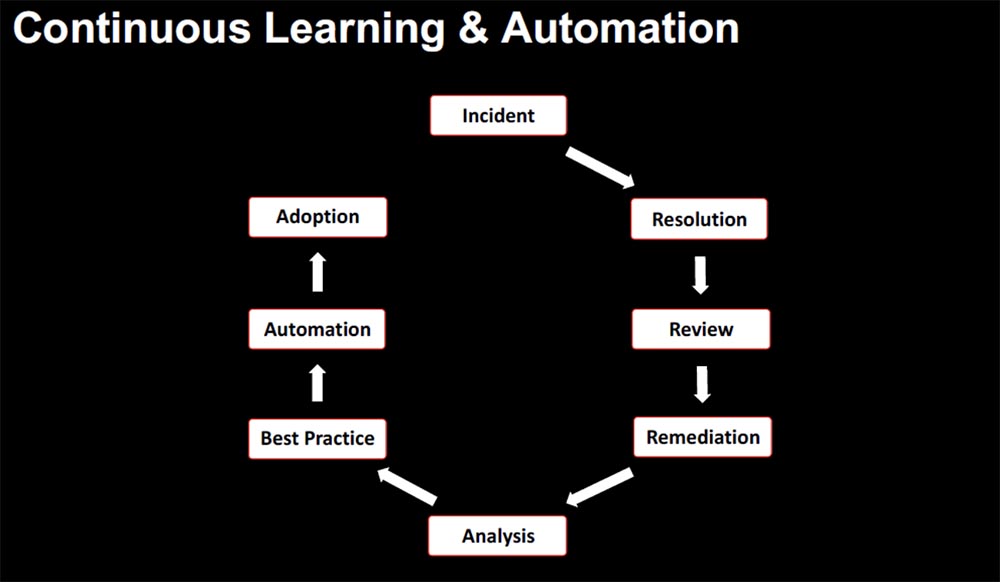
If we return to biology, we can draw an analogy with the human nervous system. It is autonomous and automated, so you don’t think about vital activities like digestion or respiration. Therefore, we wanted to create an environment in which we can automatically implement the best practices without thinking about how to do it. At Netflix, we accomplished this by continuously training staff and quickly learning from incidents as they occur, and automating the implementation of advanced problem-solving techniques into the infrastructure.
Continuous training and automation is a chain of sequential actions: an incident – fixing an event – a comprehensive review of the causes of an incident – restoration of performance – analysis – finding the best solution – automation – implementation. Thus, “knowledge becomes code,” which integrates directly into the microservice architecture.
Over the course of several years, we have accumulated best practices and formulated general principles, which are called “Production Ready”, or “Ready Product”. This is a checklist or Netflix action plan. Each of the principles is based on automation and continuous improvement of the model of interaction with the service:
- Alerts Alerts
- Apache & tomcat
- Automatic canary analysis
- Auto scaling
- Chaos model
- Consistent, consistent names
- ELB config
- Healthchek Health Check
- Immutable Machine Images
- Squeeze – testing. It consists of running certain tests or benchmarks in order to see changes in performance and calculate the critical point of the application. It then checks to see if this latest change was ineffective, or whether it determines the recommended options for automatic scaling before deployment.
- Red / Black deployments include a release that reduces downtime and risks by launching two identical production environments, Red and Black. At any given time, only one of the environments is live, and it serves all traffic.
- Timeouts, retries, fallback.
To be continued very soon …
Some advertising
Thank you for staying with us. Do you like our articles? Want to see more interesting materials? Support us by placing an order or recommending to your friends, cloud VPS for developers from $ 4.99, A unique analogue of entry-level servers that was invented by us for you: The whole truth about VPS (KVM) E5-2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps from $ 19 or how to divide the server correctly? (options are available with RAID1 and RAID10, up to 24 cores and up to 40GB DDR4).
Dell R730xd 2 times cheaper at the Equinix Tier IV data center in Amsterdam? Only here 2 x Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV from $ 199 in the Netherlands! Dell R420 – 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB – from $ 99! Read about How to Build Infrastructure Bldg. class using Dell R730xd E5-2650 v4 servers costing 9,000 euros per penny?