Process Mining with bupaR

Currently, the Process Mining topic continues to gain popularity, and is increasingly being used in the search for new ways to improve the efficiency of business processes, in the operational analysis of pilot projects, and, of course, in audit tasks. When choosing a tool for development within the framework of this task, the most important criteria are accessibility, performance, and the presence of a community.
In this article, we will look at bupaR – open source package for business process analysis in language R. Used as an IDE RStudio.
Let’s say we already have a file (csv) of the log (log) of user activity events in the online store. Let’s use the package reader to load the event log from this file and the method activities_to_eventlog from bupaR to convert:
library(readr)
library(bupaR)
df <- readr::read_csv('./gift4iaia_log_file.csv',locale=locale(encoding = 'cp1251'))
events <- bupaR::activities_to_eventlog(
df,
case_id = 'UserID',
activity_id = 'Activity',
resource_id = 'User_name',
timestamps = c('StartTime', 'CompleteTime')
)Now let’s output a mapping between event IDs and log data fields.
mapping(events)
Case identifier: UserID
Activity identifier: Activity
Resource identifier: User_name
Activity instance identifier: activity_instance_id
Timestamp: timestamp
Lifecycle transition: lifecycle_id Let’s display the number of actions from the event log.
n_activities(events)
[1] 4Let’s look at the summary data (method summary):
events %>%
summary
Number of events: 26
Number of cases: 4
Number of traces: 3
Number of distinct activities: 4
Average trace length: 6.5
Start eventlog: 2021-12-01 19:52:01
End eventlog: 2021-12-03 20:48:51
UserID Activity User_name
Length:26 Авторизация :8 Виннипух:8
Class :character Оплата товара :4 Кролик :4
Mode :character Оформление заказа :6 Пятачок :6
Поиск товаров в каталоге:8 Сова :8
activity_instance_id lifecycle_id timestamp .order
Length:26 CompleteTime:13 Min. :2021-12-01 19:52:01 Min. : 1.00
Class :character StartTime :13 1st Qu.:2021-12-01 20:34:53 1st Qu.: 7.25
Mode :character Median :2021-12-01 21:16:51 Median :13.50
Mean :2021-12-02 09:53:00 Mean :13.50
3rd Qu.:2021-12-02 21:51:53 3rd Qu.:19.75
Max. :2021-12-03 20:48:51 Max. :26.00 Let’s build a diagram of the frequency of actions based on the event log. To do this, we use the function activity_frequency with parameter “activity”which forms a summation for each activity (number/frequency) and, based on this summation, we generate the diagram itself (method plot()).
library(ggplot2)
events %>%
activity_frequency(level = "activity") %>%
plot() 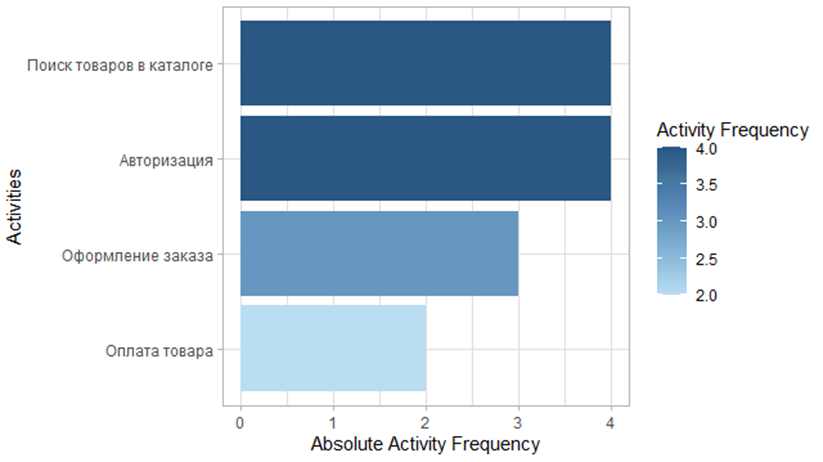
Now let’s build a process map. For this we need a method process_map. In this example, the type value is the function frequency with parameter “relative_case” to display the frequency as a percentage (by default, without setting parameters for process_map absolute values will be displayed)
events %>%
process_map(type = frequency("relative_case")) According to the graph obtained, we see that 75% of the search for goods in the catalog ended with placing an order and 50% – with payment for the goods.
Let’s build a process map in terms of performance. Here we use in process_map function performancedefined by two arguments, is a statistical function applied to the processing time (average – meanmedian – median etc.), as well as a unit of time (days – “days”clock –“hours” minutes –“mins” etc.).
events %>%
process_map(performance(mean, "mins"))
In this case, we can evaluate the stages of the process by duration. For example, the stage of searching for products takes an average of 22.82 minutes, and checkout 18.48 minutes.
Now let’s use the filter function filter_trimwhich cuts the event log for analysis, so that the sequence of actions begins with the activity (activities) start_activities and ends with activity(s) end_activities. Let’s build a process map for sequences of actions starting with the search for goods in the catalog and ending with the payment for the goods.
events %>%
filter_trim(start_activities = "Поиск товаров в каталоге", end_activities="Оплата товара")%>%
process_map(performance(mean, "mins"))
From the resulting graph, we see that for buyers who have completed the stage of payment for goods, the average time to search for goods in the catalog is significantly higher than for all users.
Also, in building a process map, it is possible to combine the above approaches. For this, in the function process_map it is necessary to set the parameters of the types of nodes and edges of the process graph (type_nodes, type_edges).
events %>%
process_map(type_nodes=performance(mean, "mins"), type_edges = frequency("relative_case"))BupaR makes it possible to consider the business process from a variety of angles. In combination with ease of development, customization (in particular, in building a process map), a wide range of useful functions, and, of course, the huge possibilities of the language Rfocused on data analysis and work with statistics, the use of this package seems to be an excellent solution in a business process analysis project.




