PostgreSQL Antipatterns: chained EXISTS
CREATE TABLE task AS
SELECT
id
, (random() * 100)::integer person -- всего 100 сотрудников
, least(trunc(-ln(random()) / ln(2)), 10)::integer priority -- каждый следующий приоритет в 2 раза менее вероятен
FROM
generate_series(1, 1e5) id; -- 100K задач
CREATE INDEX ON task(person, priority);
The word “is” in SQL becomes EXISTS – let’s start with the simplest option:
SELECT
*
FROM
generate_series(0, 99) pid
WHERE
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 10
);

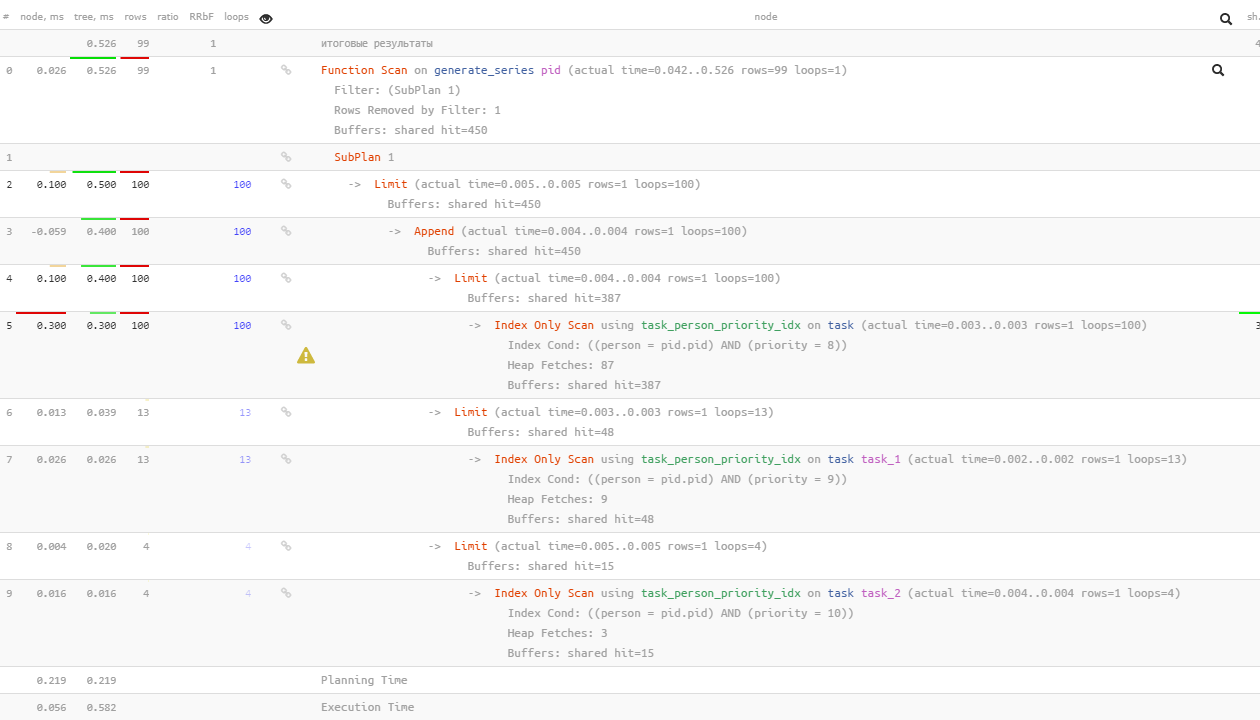
all plan pictures are clickable
So far, everything looks good, but …
EXISTS + IN
… then they came to us and asked to include not only priority = 10, but also 8 and 9:
SELECT
*
FROM
generate_series(0, 99) pid
WHERE
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority IN (10, 9, 8)
);
They read 1.5 times more, and it also affected the execution time.
OR + EXISTS
Let’s try to take advantage of our knowledge to meet a record with priority = 8 much more likely than 10:
SELECT
*
FROM
generate_series(0, 99) pid
WHERE
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 8
) OR
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 9
) OR
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 10
);

note that PostgreSQL 12 already smart enough to do the following after 100 searches for the value 8 EXISTS-subqueries only for those “not found” by the previous ones – only 13 by value 9, and only 4 by value 10.
CASE + EXISTS + …
On previous versions, a similar result can be achieved by “hiding under CASE” the following queries:
SELECT
*
FROM
generate_series(0, 99) pid
WHERE
CASE
WHEN
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 8
) THEN TRUE
ELSE
CASE
WHEN
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 9
) THEN TRUE
ELSE
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 10
)
END
END;
EXISTS + UNION ALL + LIMIT
The same, but you can get a little faster if you use the “hack” UNION ALL + LIMIT:
SELECT
*
FROM
generate_series(0, 99) pid
WHERE
EXISTS(
(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 8
LIMIT 1
)
UNION ALL
(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 9
LIMIT 1
)
UNION ALL
(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 10
LIMIT 1
)
LIMIT 1
);
Correct indexes are the key to the health of the database
Now let’s look at the problem from a completely different side. If we know for sure that those task-the records we want to find, several times less than the rest – so let’s make a suitable partial index. At the same time, we will immediately switch from the “dot” transfer 8, 9, 10 to >= 8:
CREATE INDEX ON task(person) WHERE priority >= 8;SELECT
*
FROM
generate_series(0, 99) pid
WHERE
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority >= 8
);
I had to read 2 times faster and 1.5 times less!
But after all, probably, subtract at once in general all suitable task right away – will it be even faster? ..
SELECT DISTINCT
person
FROM
task
WHERE
priority >= 8;
Far from always, and certainly not in this case – because instead of 100 reads of the first available records, we have to read more than 400!
And in order not to guess which of the query options will be more effective, and to know it confidently – use explain.tensor.ru…