Pentest applications with GraphQL
Recently GraphQL is gaining more and more popularity, and with it the interest of information security specialists is growing. Technology is used by companies such as: Facebook, Twitter, PayPal, Github, and others, which means it's time to figure out how to test this API. In this article we will talk about the principles of this query language and directions for testing penetration of applications with GraphQL.
Why do you need to know GraphQL? This query language is actively developing and more and more companies find it a practical application. As part of the Bug Bounty programs, the popularity of this language is also growing, interesting examples can be found here, here and here.
Training
Test site where you will find most of the examples given in the article.
A list with applications that you can also use to study.
To interact with various APIs, it is better to use IDE for GraphQL:
- Graphql-playground
- Altair
- Insomnia
We recommend the latest IDE: Insomnia has a convenient and simple interface, there are many settings and autocompletion of the query fields.
Before going directly to the general methods of analyzing security applications with GraphQL, let us recall the basic concepts.
What is GraphQL?
GraphQL is a query language for APIs designed to provide a more efficient, powerful, and flexible REST alternative. It is based on declarative data sampling, that is, the client can specify exactly what data he needs from the API. Instead of multiple API endpoints (REST), GraphQL represents a single endpoint that provides the client with the requested data.
The main differences between REST and GraphQL
Usually in the REST API you need to get information from different endpoints. In GraphQL, in order to get the same data, you need to make one query indicating the data you want to receive.
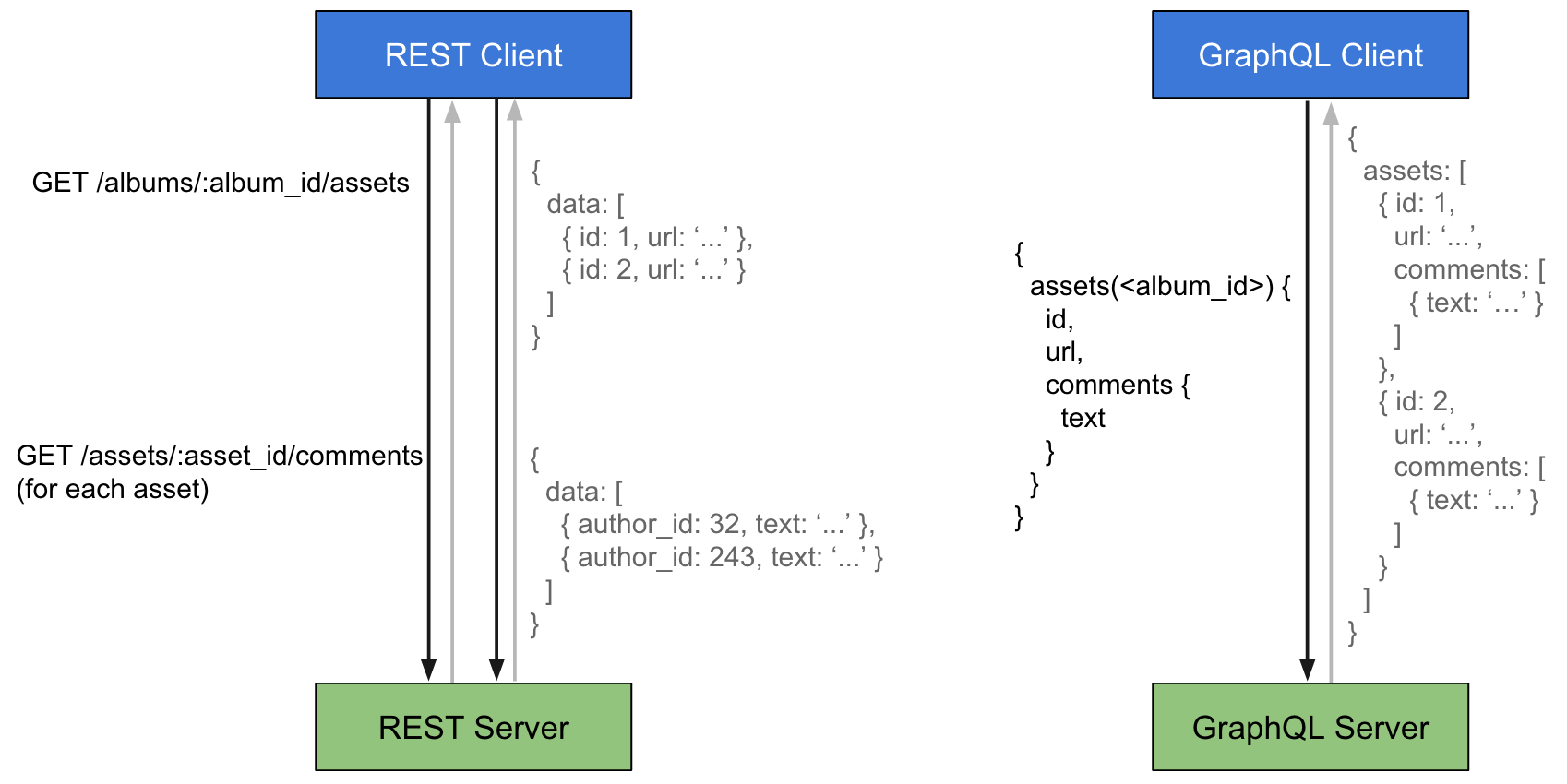
REST API provides the information that the developer provides in the API, that is, if you need to get more or less information than the API suggests, then additional actions will be needed. Again, GraphQL provides exactly the requested information.
A useful addition would be that GraphQL has a schema that describes how and what data a client can receive.
Types of requests
There are 3 main types of queries in GraphQL:
- Query
- Mutation
- Description
Query
Query queries are used to get / read data in the schema.
An example of such a request:
query {
allPersons {
name
}
}In the request we indicate that we want to get the names of all users. In addition to the name, we can specify other fields: age, id, posts etc. To find out which fields we can get, you need to press Ctrl + Space. In this example, we pass the parameter with which the application returns the first two entries:
query {
allPersons (first: 2) {
name
}
}Mutation
If the query type is needed for reading data, then the mutation type is needed for writing, deleting and modifying data in GraphQL.
An example of such a request:
mutation {
createPerson (name: "Bob", age: 37) {
id
name
age
}
}In this request, we create a user with the name Bob and age 37 (these parameters are passed as arguments), in the attachment (curly brackets) we indicate what data we want to get from the server after creating the user. This is necessary in order to understand that the request was executed successfully, as well as to obtain data that the server generates independently, such as id.
Subscription
Another type of query in GraphQL is subscription. It is needed to notify users of any changes in the system. It works like this: the client subscribes to an event, after which a connection is established with the server (usually via WebSocket), and when this event occurs, the server sends a notification to the client via the established connection.
Example:
subscription {
newPerson {
name
age
id
}
}When a new Person is created, the server will send information to the client. The presence of subscription queries in schemas is less common than query and mutation.
It is worth noting that all the possibilities for query, mutation and subscription are created and configured by the developer of a specific API.
Optional
In practice, developers often use alias and OperationName in queries for clarity.
Alias
GraphQL for queries provides the possibility of alias, which can facilitate the understanding of what exactly the client requests.
Suppose we have a query of the form:
{
Person (id: 123) {
age
}
}which will display the username with id 123. Let the name of this user be Vasya. In order not to wrestle with the next time, which will lead this request, you can do this:
{
Vasya: Person (id: 123) {
age
}
}OperationName
In addition to alias, GraphN uses OperationName:
query gettingAllPersons {
allPersons {
name
age
}
}OperationName is needed to clarify what the query is doing.
Pentest
After we have dealt with the basics, go directly to Pentest. How to understand that the application uses GraphQL? Here is an example query in which there is a GraphQL query:
POST / simple / v1 / cjp70ml3o9tpa0184rtqs8tmu / HTTP / 1.1
Host: api.graph.cool
User-Agent: Mozilla / 5.0 (X11; Ubuntu; Linux x86_64; rv: 65.0) Gecko / 20100101 Firefox / 65.0
Accept: * / *
Accept-Language: ru-RU, ru; q = 0.8, en-US; q = 0.5, en; q = 0.3
Accept-Encoding: gzip, deflate
Referer: https://api.graph.cool/simple/v1/cjp70ml3o9tpa0184rtqs8tmu/
content-type: application / json
Origin: https://api.graph.cool
Content-Length: 139
Connection: close
{"operationName": null, "variables": {}, "query": "{ n __schema { n mutationType { n fields { n name n} n} n} n} n" }Some parameters by which you can understand that GraphQL is in front of you, and not something else:
- There are words in the request body: __schema, fields, operationName, mutation, etc .;
- In the request body there are many characters " n". As practice shows, they can be removed to make it easier to read the request;
- often the way to send a request to the server is: ⁄graphql
Great, found and identified. But where to insert a quote How to find out what we need to work with? Introspection will come to the rescue.
Introspection
GraphQL provides an introspection scheme, i.e. schema with a description of the data that we can get. Thanks to this, we can find out what requests exist, what arguments can / should be passed to them and much more. Note that in some cases, developers intentionally do not allow the possibility of introspection of their application. Nevertheless, the main majority still leaves such an opportunity.
Consider the basic query examples.
Example 1. Getting all kinds of requests
query {
__schema {
types {
name
fields {
name
}
}
}
}We form query query, we specify that we want to receive data on __schema, and in it types, their names and fields. In GraphQL there are utility variable names: __schema, __typename, __type
In the answer we will receive all types of requests, their names and fields that exist in the schema.
Example 2. Getting fields for a specific type of query (query, mutation, description)
query {
__schema {
queryType {
fields {
name
args {
name
}
}
}
}
}The answer to this query will be all possible queries that we can execute to the schema to get data (query type), and possible / necessary arguments for them. For some queries, the argument (s) is required. If you execute such a request without specifying a required argument, the server should display a message with an error that you need to specify it. Instead of queryType, we can substitute mutationType and subscriptionType to get all possible queries on mutations and subscriptions, respectively.
Example 3. Getting information about a specific type of request
query {
__type (name: "Person") {
fields {
name
}
}
}Thanks to this request, we get all the fields for the Person type. As an argument, instead of Person, we can pass any other request names.
Now that we can deal with the general structure of the application under test, let's determine what we are looking for.
Information disclosure
Most often, an application using GraphQL consists of many fields and types of queries, and, as many know, the harder and larger the application, the harder it is to configure and monitor its security. That is why with careful introspection you can find something interesting, for example: the user's full name, their phone numbers and other critical data. Therefore, if you want to find something similar, we recommend checking all possible fields and arguments of the application. So within the framework of pentest, user data was found in one of the applications: name, phone number, date of birth, some map data, etc.
Example:
query {
User (id: 1) {
name
birth
phone
email
password
}
}
Going through the id values, we will be able to get information about other users (or maybe not, if everything is configured correctly).
Injections
Needless to say that almost everywhere where there is a work with a large amount of data, there are also databases? And where there is a database – there may be SQL-injections, NoSQL-injections and other types of injections.
Example:
mutation {
createPerson (name: "Vasya '- +") {
name
}
}Here is an elementary SQL injection in the query argument.
Authorization bypass
Suppose we can create users:
mutation {
createPerson (username: "Vasya", password: "Qwerty1") {
}
}Assuming that there is a certain isAdmin parameter in the handler on the server, we can send a request of the form:
mutation {
createPerson (username: "Vasya", password: "Qwerty1", isAdmin: True) {
}
}And make the user Vasya administrator.
DoS
In addition to the stated convenience, GraphQL has its own security flaws. Consider an example:
query {
Person {
posts {
author {
posts {
author {
posts {
author ...
}
}
}
}
}
}
}As you can see, we have created a looped subquery. With a large number of such investments, for example, 50 thousand, we can send a request that will be processed by the server for a very long time or will “drop” it altogether. Instead of processing valid requests, the server will be busy unpacking the giant nesting of the request-dummy.
In addition to large nesting, requests themselves can be "heavy" – this is when a single request has a lot of fields and internal investments. Such a request may also cause difficulties in processing on the server.
Conclusion
So, we have reviewed the basic principles of penetration testing applications with GraphQL. We hope you have learned something new and useful for yourself. If you are interested in this topic, and you want to study it more deeply, then we recommend the following resources:
www.howtographql.com is the main resource for learning from scratch. In addition to theory, it contains practice.
www.graphql.com is also a good site to learn this technology.
www.howtographql.com/advanced/4-security – GraphQL security.
AppSecCali 2019 – An Attacker's View of Serverless and GraphQL Apps is a good video with concrete examples.
And don't forget: practice makes perfect. Good luck!





