parameters and tuning for incident management

Hello, my name is Ivan, I am an incident manager at Sravni. Let's discuss how to add systematicity to problem monitoring in production – let's talk about incident management.
Something broke in production – this is the harsh reality, it happens to the best of us, unfortunately. What usually happens in such cases? We catch alerts, run to look at graphs and logs, call the developer who worked on this functionality from vacation, roll out a fix, tearing out our beard, we conduct a post-mortem. This is a common sense reaction, a classic.
But when it comes to money not earned due to an incident, upset users – any improvement, even small, by a fraction of a percent, can bring tangible results.
Let's talk about how to approach the issue of monitoring methodologically – using incident management tools. We'll discuss how to assess the criticality of services and what systems can be useful for tracking issues.
The article is aimed primarily at those who are currently engaged in monitoring at the level of general engineering literacy, but have not yet explicitly used incident management as an approach.
Something is broken – what exactly are we talking about?
“There are problems in production” – this is a phrase you can hear from colleagues about completely different things.
Here in the article for the terms “incident” and “incident management” we use the definitions adopted in ITIL and ITSM (here’s a good one introductory article from Atlassian).
Within this approach, the following categories of incidents are distinguished:
performance degradation;
partial unavailability;
complete inaccessibility;
violation of data storage security.
Everything is more or less clear at a glance, but as soon as you go to negotiate the processes, someone starts owing something to someone, and questions like “Is it really necessary?” may arise.
In order to agree among ourselves in the development team and provide arguments to the business, here is a list of typical problems that we want to fix using incident management:
Negative attitude of clients – with the right alerts, we will learn earlier about problems that upset users and understand more about their nature.
Unearned money – if a service is unavailable, people tend to stop paying us for it; we want to avoid this.
Support workload – if support colleagues are drowning in user requests, they may return to clients too late or miss important requests; this in turn can lead to the previous two problems.
Non-optimal allocation of the development team's time – if engineers have to “put out fires” over and over again, this costs a lot in man-hours and can lead to demotivation and emotional burnout, which leads to decreased productivity and leaving the company, and can increase the difficulty of hiring.
Overexpenditure of resources – here we are talking about the configuration and cost of the infrastructure, the number of people in the team; “throwing money at the problem” is not always the most successful approach.
Ok, let’s imagine that everyone has agreed with everyone, and we have the green light for incident management – let’s talk about the first steps.
Incident management: where to start
In our case, the first steps looked like this:
find
extremeresponsible;tell everyone exactly what will happen;
bypass all commands.
If there is no explicit agreement on who exactly should respond to incidents, a situation may arise when everyone thinks that someone else should deal with the problem (this happens even in cases where there is an agreement – we discussed this in our article about problems with duty).
Ideally, there should be a dedicated person for incident management to provide sufficient focus and context. If there is no individual person, this is not a blocker. The logic here is the same as for piloting any new activities – let’s try, let a person who will combine new tasks with other responsibilities do it first, and if we see the benefits and have the opportunity, then we will create a separate role. In our case, incident management was piloted by the second line support lead.
Tell everyone exactly what will happen – the format and quantity of communications depends on your organizational structure and established channels for disseminating information. It is important to convey the concept to management (so that there are no fundamental objections on their part) and then tell the whole team in general (and here the previously informed management will be able to support the “local initiative”).
Key part of the announcement: agree on monitoring parameters.
We have chosen the following:
criticality of the service for business;
are there any people on duty?
how it depends on internal services;
What are the dependencies on external services?
For criticality, we have identified three levels:
The service does not affect the client journey – problems are repaired taking into account the team’s workload and fall into the general queue of development tasks for the corresponding team.
The service makes it difficult to navigate the customer journey, but customers can generally use the product – the relevant tasks are sent to the backlog, corrections occur as usual, during the team’s working hours. Typical tasks: fixing the service, adding additional logging, reconfiguring alerts.
Customers cannot use the service – the fix must be immediate, even if it needs to be done at night or on weekends.
Staying on duty is a useful practice, but there is not always a need for it. If there are no people on duty in the team yet, but there is a need, then we negotiate with the developers on the team or escalate the expansion of staff (hiring), or reconsider the criticality of the service.
Dependency on internal services – we prescribe it so that in the event of an incident, you can quickly check whether everything is in order in neighboring teams, speed up the search for the causes.
Dependency on external services – we register and double-check that we definitely have contacts on the other side, with an explicit SLA for the response time to our requests.
Another important entity in the context of incident management, which is worth telling everyone about and agreeing on the rules – error budget. This is the maximum time during which the system can degrade or be unavailable without consequences specified in the agreement.
At Comparison, we have a rule: the company average uptime for a service should be 95%. But different teams have their own nuances, we asked everyone to discuss it with the business once again so that everyone is satisfied with everything.
Incident management tools
Agreements with colleagues and external contractors are a difficult part of the matter, but not the only aspect of the issue where something can go wrong. For incident management, it is important to carefully configure the appropriate tooling, and here, as usual, there are some nuances.
Our main monitoring tools: Apdex, Sloth, Grafana OnCall. Let's tell you a little more about them.
Apdex
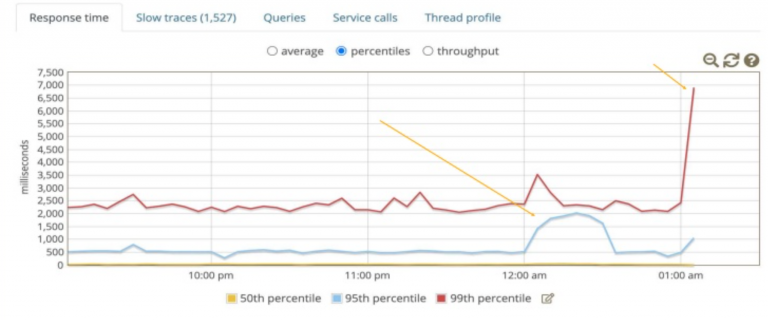
The Application Performance Index (Apdex) is a standardized metric that provides a simple, easy-to-understand assessment of an application's performance from a user's perspective.
For us, this is a tool that shows the performance of our services on a scale from 0 to 1, where 0 is “the service is very bad,” 0.5-0.75 is “the service is generally ok, but it could be better,” 1 is “the service feels great.” ” Errors are detected, as well as the speed of response to requests and service response time.

One of the nuances: you can only attach Apdex to handles that have >1 RPS. For <1 RPS, instead of Apdex we look at their Error Rate (the ratio of the number of normal responses to the number of errors).
Sloth
Service Level Objectives (SLO) – a service level goal that defines the expected quality and performance of the service. Sloth is a Prometheus-based tool that simplifies and standardizes SLO creation, making the process faster, simpler, and more reliable.
With its help, we can see how the service feels in retrospect. In addition, the tool includes support for creating dashboards for Grafana, which makes monitoring and analyzing SLOs more convenient and accessible.
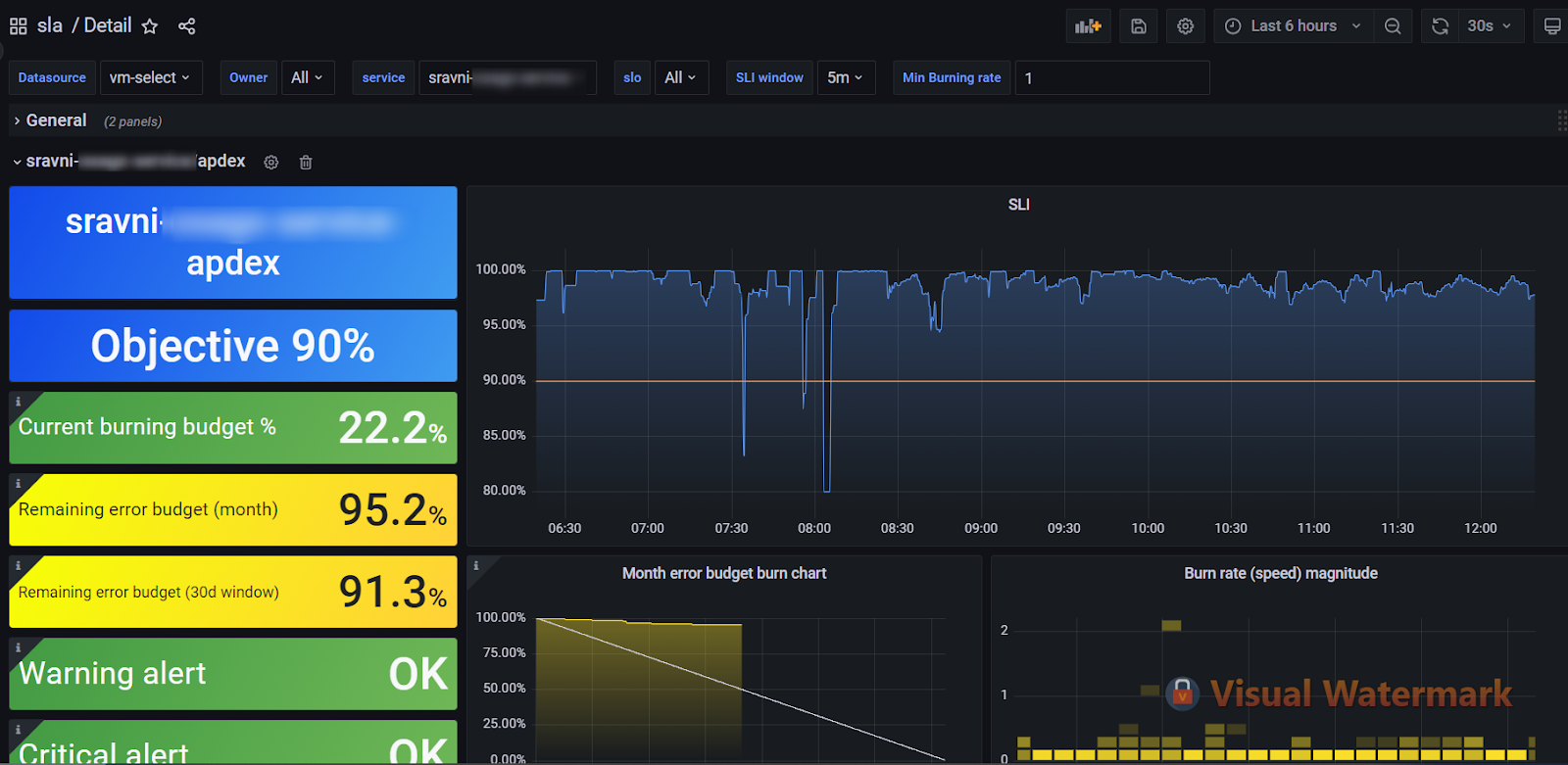
The yellow line indicates the threshold below which the error budget begins to burn out.
Here, too, there were some nuances. If you have already connected Apdex, then it will not be difficult for you to connect Sloth. If you are not configured to work with Apdex, you will have to write custom queries in a special language for Grafana.
Another aspect – false alerts. An “alarm” may be triggered not because the service has become unwell, but, for example, because of problems with metrics. Here you need to be mentally prepared that you will have to experiment with the settings, make several iterations of tuning parameters based on observations of the real level of degradation of services. It is unlikely that it will be possible to turn everything on “out of the box” so that each incident alert always signals a real problem – there will most likely be false alerts at first.
Grafana OnCall
Here's a setup checklist:
Create a team of people to handle incidents.
Add team members – everyone we want to involve in interacting with incidents.
Create a duty schedule.
Set escalation rules – in which cases it is enough to send a notification to the duty officer in a conditional Telegram, and when you need to call the service station on the phone.
Enable integrations – in our case, all alerts arrive in a common channel in the working messenger.
Link alerts to escalation rules.
Alerts arriving in our working messenger look like this:

Integration of Grafana OnCall with Jira
Integration with the task tracker is configured in the Grafana OnCall interface using a webhook (here instructions).
Be careful with the transition from testing the integration to its full use – at one time, at the start of using this option, I accidentally created 1000+ alerts, the same number of tickets were simultaneously opened in Jira – the developers were, ahem, surprised.
Lifehack for finding answers to integration questions: in addition to checking documentation and Googling, you can join open channel Grafana in Slack, where the developers can promptly and kindly provide guidance on the information you are interested in.
Incident management: necessary and sufficient conditions
But there are companies that live without incident management and nothing, somehow manage?
This is true. The questions “do we really need it?” and “if so, when should I start?” – largely lie in the plane of the top-level principles of the IT team.
In our country, the teams that develop them are responsible for the performance of products – this is an ideological and organizational point. The number of teams is growing, new dependencies with external partners and between products appear. In this situation, living without a standard that is understandable to everyone and at the same time fulfilling the promise of service availability for clients is almost impossible.
So for us, incident management was not the result of curiosity or a fashion trend, but a necessity.
How it will be in your case – double-check in the culture of the IT team. Whatever your attitude towards incident management, I would like to wish everyone about the incidents themselves to happen less often!
Tell us in the comments how your process for working with incidents is organized – are there dedicated people for such tasks, what tools do you use, how do you assess the criticality of services?