ORC and Parquet formats based on HDFS
Every company continuously produces and stores tons of data, and this causes a lot of problems. Storage volumes are not infinite, and neither are hardware resources. But optimizing data processing and storage does not always bring the desired results. How can I configure everything so as to significantly reduce the space they occupy on disk?
We made it! We have reduced the amount of data on the disk by 3 times, while speeding up their processing. And now I’ll tell you how. My name is Alexander Markachev, I am a Data Engineer of the Voice Antifraud team at beeline. In the article we will touch on the topic of ORC and Parquet formats, how to use and store them correctly so that everyone has a good time.

Data and formats
In total, there are currently 97 zettabytes of data in the world and about 220 terabytes are generated daily. By 2025, current data is expected to double.

In this regard, Beeline is no exception. Our data is growing both due to new data and due to the processing and enrichment of old ones. One of the tasks of a data engineer is to effectively manage this data so that it takes up little space and at the same time is easily accessible. Therefore, it is important to be able to work with data formats.
There are a huge variety of formats: JSON, CSV, Aura and many others, but not all of them are suitable for storage and quick access. They either take up too much space or work with them is very slow. It happens both.
However, two formats stand out among them: ORC and Parquet. They are great for both storing and processing data, but they have their pros and cons. That’s why we’ve set several quality metrics to evaluate them by—based on how we typically use data, your metrics may be different. Here are the main ones:
Reading individual columns;
Column statistics;
Changing the order of columns;
Adding columns;
Data type support;
Access speed;
Compression.
Structure
To understand how formats work and how to use them correctly, you need to decide on the structure.
Parquet file structure
Parquet was created in March 2013 and initially supported many programming languages (not just JVM-like ones) and was itself supported by many systems. Currently it is used by such giants as Amazon, Cloudera, Netflix, Apple, Beeline.
Parquet file structure on the official site looks like that:

There is a header, groups of lines, sections of columns and pages. In order not to get confused in this terrible graph, let’s look at it in more detail:

The file starts with File Header. It contains the magic number PAR1, which allows you to read and determine that this is a Parquet file for further optimization.
Ends File Footer‘om which contains:
Metadata (schema definition, row group information, column metadata);
Additional data, such as the dictionary location for the column;
Column statistics.
Between File Header and File Footer there are groups of lines − Row-group. This is splitting one specific file into many small blocks so that, if necessary, you do not have to read the entire huge file. Let’s say you wrote 17 GB into it. In order not to read the entire file for the sake of 10 lines, we split it into groups and read only the first one.
But this is not enough. Parquet also has a column layout – Column Chunk. Each column can be read separately, which is important for wide tables.
Columns are divided into groups of pages – Page. This is already a physical representation of the data, a set of values for each column in the file. Page has its own data schema description, which indicates the data type, the size of the specific page, and the encoding method. Just like in Row-group, there are possible links to a dictionary in order to decode the data.
ORC File Structure
ORC was created a month earlier than Parquet, but had no luck. It only supported JVM languages and was designed specifically for Hive. In 2016, it was improved, it began to support C-like clients and itself began to be supported by many systems. Now it has been supported in Impala. Its range of applications and benefits has greatly expanded. Its creators are constantly improving it. It is used by such giants as Facebook, Twitter, Netflix, Amazon, Beeline. You may have noticed that some companies are repeating themselves. The fact is that different formats are used depending on the situation. There is no absolutely correct solution.
The ORC structure looks even worse than the Parquet structure:

There are also headers, stripes (aka stripes), sections of columns and pages, and also postscript.

Just like Parquet, ORC starts with File Header. Only this File Header already contains the ORC magic number, which allows us to read it as an ORC file. But unlike Parquet ORC ends postscript, because it does not contain all the metadata, but only information to interpret the reading of the entire file. Including metadata length, footer length, compression type, and version type.
After postscript comes File Footer, which contains all the metadata that Parquet does, but in compressed form to save a bit of disk space through compression. At the same time, this allows ORC to quickly filter out unnecessary files. File Footer stores column names, titles, number of lines of each stripe, statistics, information about each stripe, as well as dictionaries and much more.
Between File Header and File Footer contains stripe‘s. This is an analogue of Row-group in Parquet, that is, simply splitting one large file into many small ones inside, invisible to the eyes of a common person.
In turn, stripes are divided into blocks. They contain indexes, the data itself, and Stripe Footer is an analogue of File Footer. It contains all the metadata for a particular stripe and allows you to read it very quickly. Unlike Parquet, if other stripes have been corrupted, you can read them independently. This way you will not lose all the data of one file, but only part of it, if this has already happened.
Block Index Data in turn, contains meta-information of a specific column and a specific stripe, that is, the following data: minimum, maximum, sum and number of rows in a specific column.
Between Index Data and Stripe Footer the data itself is contained – Row Datatheir physical division into columns, which allows you to read one small block of a particular stripe.
Columns, unlike Parquet, are divided into index blocks and data blocks. Each index block contains meta information for reading a specific small block. This small block is equal to 10,000 elements by default, which allows you to avoid loading the hard drive and processor once again in order to deserialize the data.
Access volume and speed
Let’s imagine a table with 80+ columns with 500 million records. She will occupy:
in CSV – 204.1 GB
in Parquet (without additional compression) – 47 GB
in ORC we compress it even more, and we get only 35 GB
In addition to built-in compression, these formats have algorithms. For example, SNAPPY and ZSTD are supported by both formats, but only Parquet has the ability to compress to GZIP, LZO, LZ4. ORC only compresses in ZLIB.
Here is an example of a benchmark of compression algorithms without reference to the format:
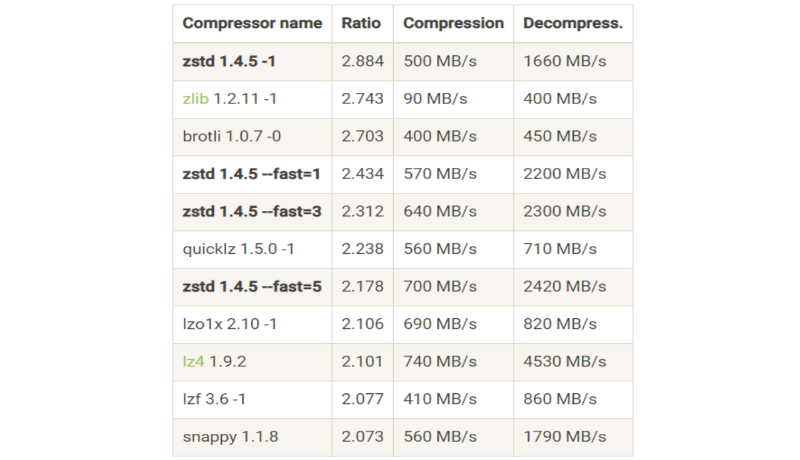
Let’s look at some of them in more detail:
SNAPPY Quite an old algorithm for formats. It has been supported for many years and is still one of the best compression formats. This is a stable average.
LZ4 It compresses much weaker than SNAPPY or other algorithms presented here, but it does it extremely quickly, which allows us not only to quickly compress, but also to read quickly.
ZSTD one of the newest algorithms, it was recently added to ORC and Parquet. It has 23 compression settings/levels. In the presented benchmark, 4 of them are visible. You may notice that the more the ZSTD compresses, the slower it does so. At the same time, weak compression allows you to read the file faster.
ZLIB took the best from GZIP, LZ4 and from itself, thanks to which it can quickly read, write without losing compression quality. Since ZLIB took metrics from different formats, it does not reach the speed of LZ4, but, nevertheless, remains an excellent choice for ORC.
Setting up ORC
My team and I have done a ton of testing to see which is best for long-term storage and analytics, and have found that in most cases, ORC has more advantages than Parquet.
Here, for example, is the same table with 500 million records and 80 columns with metrics:

Parquet in SNAPPY shows 33 GB compressed at worst and 21.1 GB at best, while ZLIB compressed ORC shows 10.8. However, this is only true for the optimized ORC. Let’s see what this means on other tables.
In the examples, I refer to the number of records in a table or partition, and not to their actual volume, because the configuration of indexes depends on this. If you have too many indexes, you will greatly increase the load on the cluster because you will need to read these indexes.
Small table
, < 100000 elements")
No matter how you optimize a small table, everything will be the same. The difference is literally tens of kilobytes. Therefore, optimizing small tables (100-200 thousand elements) does not make any sense. But if you really want to, if you really count in milliseconds, then you can disable indexes and sort the data.

Indexes are disabled using the ‘orc.create.index’=false option, but not in all versions and not always. Why this happens, unfortunately, is unknown. But even after enabling this index, you can see the following list in the file:
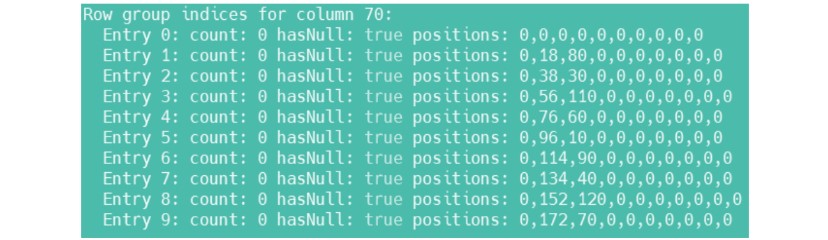
It means that you still have 10 index blocks, that is, the same 10,000 elements by default. Then we can make this index block very large so that it is larger than the table. If the index block size is larger than the number of elements in the table, only 1 index block will be created. So actually and physically we will disable this indexing.
Middle table
, < 100 million elements")
If we talk about the load on the cluster, then simply sorting a table allows you to reduce the load by 3 times if you make a selection by a sorted field. The picture shows that the load on the cluster without sorting is 18000ms, and with sorting it is 6000ms, but there is unaccounted data. This is the load on RAM, on disks and, ultimately, on the network, which is present during the entire cluster operation.
Also, instead of reading all index blocks, it is enough to select only one specific small block, due to which the load on the CPU will be tripled. An important, but small bonus is that the disk space taken up will also be reduced.
It turns out that:
● Indexes allow you to read less data from a table, so for medium tables you should not delete them;
● Sorting significantly speeds up the query.

The fact is that if we take all the data to read, then we read the entire metadata block. Then we look at stripes with potentially necessary values and only then filter and take what we are looking for. But it doesn’t really make much sense. If we sort at the very beginning, then we will read exactly one stripe, which contains the necessary information. Of course, if you have not one element, but 100,000 or a million, and they are located in different stripes, you will read each of them. But it will still be faster than reading the entire table.
Large table

The ‘orc.row.index.stride’=’60000’ parameter is a change to the index block for the stripe. Also another important parameter is ‘orc.bloom.filter.columns’.


→ Sometimes it’s worth using the Bloom filter.
The Bloom filter is a special probabilistic search algorithm that is used to determine whether an element belongs to a set. It is capable of producing a false positive, but not a false negative result, which makes it possible to guarantee the selection of the desired values. At the same time, he can select those values that are not needed. However, this allows you to reduce the amount of data read and the load on the cluster.
Here’s an example:

The difference is significant.
→ ACID support.
This is not the support that is available in relational systems, although it is very similar. In the case of ORC, when we want to replace some data in a table, it creates an additional file that tells us what the new value is for a certain row. To avoid overwriting them each time, if you need to change 100-200-300 values, you can add new values iteratively. If there are so many files that they slow down the system, then you can overwrite them.
Parquet vs. ORC: results

→ Structure.
Both formats are columnar, have statistics, and columns can be added to each.
When testing in Parquet, you can swap columns, but in ORC you cannot. This is especially important during development, when the data schema changes frequently. The inability to add a column somewhere in the middle can be very critical. It is clear that you can add it to the end and then simply change it in select, but this is not always convenient. Therefore, it is very convenient to use Parquet during the development period.
→ Compression
ORC itself compresses better, while Parquet supports weaker compression algorithms.
→ Data type support
ORC has great data type support because it was originally designed specifically for Hive and all its formats.
→ Access speed.
If you configure the table for ORC, the access speed will be higher than that of Parquet.
→ Other.
There are small nice bonuses. Parquet supports special characters in names. Let’s say you want to name the column @chair. In Parquet you can do this, in ORC you cannot. But ORC has support for Bloom filters and ACID.
ORC also has several parameters that we did not touch on in this conversation:
orc.bloom.filter tells how often the bloom filter will make mistakes. The lower the value, the less often he will make mistakes, but the more time it will take;
transactional – ACID support;
orc.mask and orc.encrypt. Allows you to set a mask and encoding for a specific column. Only those people who have access to the key will be able to find out what data is stored there.
Final word
Returning to the initial table, with ORC we reduced the disk space occupied by 3 times. We also accelerated Hive processing by 30 times in the case of selecting single elements. In the case of grouping, 3 times. In the case of Spark, the increase is twofold.

and 80+ speakers
Parquet in LZ4 is not far behind ORC in terms of parameters. However, to achieve approximately the same performance as a configured ORC, Parquet has to spend 2 times more cluster resources. That is, if you take a million milliseconds for ORC, Parquet in LZ4 will require 2 million milliseconds. In principle, the physical time is the same, but the load on the cluster is 2 times greater.
To sum it up:
Sort your data, it doesn’t matter if you use Parquet or ORC;
For large volumes, you need to adjust the block size;
Indexes are not always good. If there are too many of them, they have a huge impact on processing speed;
The Bloom filter brings tangible benefits;
Customized ORC is probably better than Parquet.





