ML, VR & Robots (and a bit of cloud)
I want to talk about a very boring project where robotics, Machine Learning (and together it is Robot Learning), virtual reality and a bit of cloud technology intersected. And all this actually makes sense. After all, it’s really convenient to move into a robot, show what to do, and then train weights on the ML server using the stored data.
Under the cut, we will tell how it works now, and some details about each of the aspects that had to be developed.

What for
For starters, it’s worth revealing a bit.
It seems that robots armed with Deep Learning are about to oust people from their jobs everywhere. In fact, everything is not so smooth. Where actions are strictly repeated, processes are already really well automated. If we are talking about “smart robots”, that is, applications where computer vision and algorithms are already enough. But there are also many extremely complicated stories. Robots can hardly cope with the variety of objects that have to deal with, and the diversity of the environment.
Key points
There are 3 key things in terms of implementation that are not yet found everywhere:
- Possibility of direct training from robot control (data-driven learning). Those. as the operator controls the robot, all data from cameras, sensors and control signals are stored. Then, this data is used for training.
- Removing a computational task (brain) from a mechanical body of a robot
- Following the principle of robot-human mutual assistance (Human-machine collaboration)
The second is also important because right now we will observe a change in the approaches to learning, algorithms, behind them, and computing tools. Perception and control algorithms will become more flexible. A robot upgrade costs money. And the calculator can be used more efficiently if it will serve several robots at once. This concept is called “cloud robotics”.
With the latter, everything is simple – AI is not sufficiently developed right now to provide 100% reliability and accuracy in all situations that are required by business. Therefore, the supervisor operator, who can sometimes help wards robots, will not interfere.
Scheme
To get started, about a software / network platform that provides all the described functionality: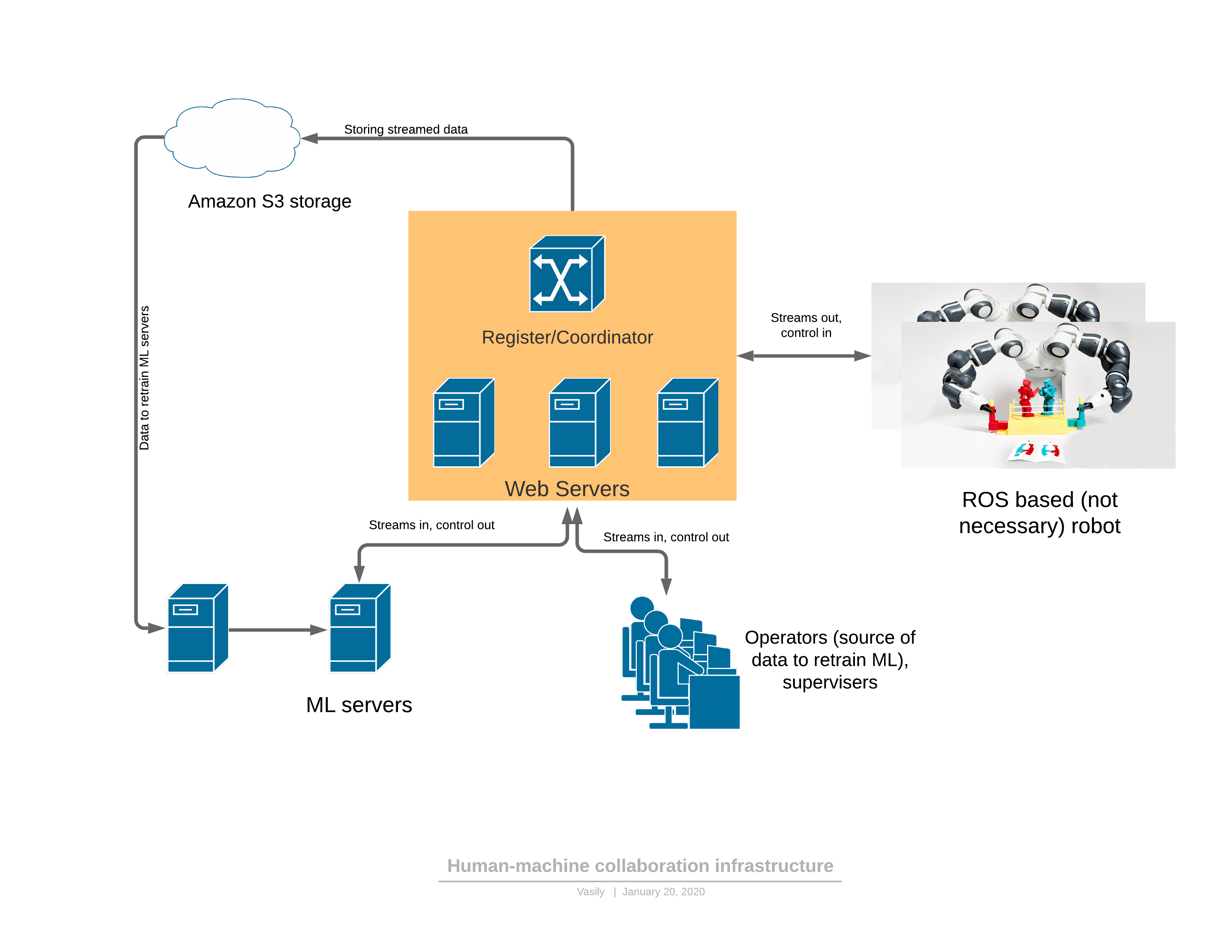
Components:
- The robot sends a 3D video stream to the server and receives control in response.
- The cloud part includes: streaming transmit-receive server, service of the registrar of entities in the system (robots, operators, administrators, servers)
- The ML part (machine learning) is separately rendered, it includes servers for retraining models, as well as servers that control the robot. They function completely in the same way as operators – they receive a 3D stream at the input, they form control signals at the output.
- There is a client application for the operator, rendering a 3D stream from the robot to the virtual reality helmet, providing a sufficient UI for controlling the robot. The way out is management.
Automation Order
There are 2 modes of functioning of the robot: automatic and manual.
In manual mode, the robot works if the ML service is not yet trained. Then the robot goes from automatic to manual either at the request of the operator (I saw strange behaviors while watching the robot), or when ML services themselves detect an anomaly. About the detection of anomalies will be later – this is a very important part, without which it is impossible to apply the proposed approach.
The evolution of control is as follows:
- The task for the robot is formed in human-readable terms and performance indicators are described.
- The operator connects to the robot in VR and performs the task within the existing workflow for some time
- ML part is trained on the received data
- The robot starts to work autonomously under the supervision of the operator, in case of ML anomalies being detected by the management service or by the operator himself, the robot switches back to manual mode and retrains
- A weekly report is generated on the set performance indicators and the percentage of time to complete the work in automatic mode
Integration with the robot and a little about 3D compression
Very often, robots use the ROS (robot operating system) environment, which in fact is a framework for managing “nodes” (nodes), each of which provides part of the robot’s functionality. In general, this is a relatively convenient way of programming robots, which in some ways resembles the microservice architecture of web applications in their essence. The main advantage of ROS is the industry standard and there are already a huge number of modules needed to create a robot. Even industrial robotic arms can have a ROS interface module.
The simplest thing is to create a bridge model between our server part and ROS. For instance, such. Now in our project we use a more developed version of the ROS “node”, which logs in and polls the microservice of the register to which relay server a particular robot can connect. The source code is given only as an example of instructions for installing the ROS module. At first, when you master this framework (ROS), everything looks pretty unfriendly, but the documentation is pretty good, and after a couple of weeks, developers begin to use its functionality quite confidently.
From interesting – the problem of compression of the 3D data stream, which must be produced directly on the robot.
It’s not so easy to compress the depth map. Even with a small degree of compression of the RGB stream, a very serious local distortion of brightness from true is allowed in pixels at the borders or when moving objects. The eye almost does not notice this, but as soon as the same distortions are allowed in the depth map, when rendering 3D everything becomes very bad:

(of articles)
These defects at the edges greatly spoil the 3D scene, as there is just a lot of garbage in the air.
We began to use frame-by-frame compression – JPEG for RGB and PNG for a depth map with small hacks. This method compresses the 30FPS stream for a 3D scanner resolution of 640×480 at 25 Mbps. Better compression can also be provided if traffic is critical to the application. There are commercial 3D codecs for a stream that can also be used to compress this stream.
Virtual reality control
After we calibrated the reference frame of the camera and the robot (and we already wrote an article about calibration), the robot arm can be controlled in virtual reality. The controller sets both the position in 3D XYZ and the orientation. For some roboruk, only 3 coordinates will be enough, but with a large number of degrees of freedom, the orientation of the tool specified by the controller must also be transmitted. In addition, there are enough controls on the controllers to execute robot commands such as turning the pump on / off, gripping control and others.
Initially, it was decided to use the JavaScript framework for virtual reality A-frame, based on the WebVR engine. And the first results (video demonstration at the end of the article for the 4-coordinate arm) were obtained on the A-frame.
In fact, it turned out that WebVR (or A-frame) was an unsuccessful solution for several reasons:
- compatibility mainly with Firefox, at the same time, it was in FireFox that the A-frame framework did not release texture resources (the rest of the browsers coped) until the memory consumption reached 16GB
- limited interaction with VR controllers and helmet. So, for example, it was not possible to add additional marks with which you can set the position, for example, of the operator’s elbows.
- The application required multithreading or several processes. In one thread / process, it was necessary to unpack the video frames, in another – draw. As a result, everything was organized through workers, but the unpacking time reached 30ms, and rendering in VR should be done at a frequency of 90FPS.
All these shortcomings resulted in the fact that the rendering of the frame did not have time in the allotted 10ms and there were very unpleasant twitches in VR. Probably, everything could be overcome, but the identity of each browser was a little annoying.
Now we decided to go to C #, OpenTK and C # port of the OpenVR library. There is still an alternative – Unity. They write that Unity is for beginners … but difficult.
The most important thing that needed to be found and known for gaining freedom:
VRTextureBounds_t bounds = new VRTextureBounds_t() { uMin = 0, vMin = 0, uMax = 1f, vMax = 1f };
OpenVR.Compositor.Submit(EVREye.Eye_Left, ref leftTexture, ref bounds, EVRSubmitFlags.Submit_Default);
OpenVR.Compositor.Submit(EVREye.Eye_Right, ref rightTexture, ref bounds, EVRSubmitFlags.Submit_Default);
(this is the code for sending two textures to the left and right eyes of the helmet)
Those. draw in OpenGL in the texture what different eyes see, and send it to glasses. Joy knew no bounds when it turned out to fill the left eye with red, and the right with blue. Just a couple of days and now the depth and RGB map coming via webSocket was transferred to the polygonal model in 10ms instead of 30 on JS. And then just interrogate the coordinates and buttons of the controllers, enter the event system for the buttons, process user clicks, enter the State Machine for the UI and now you can grab a glass from the espresso:
Now the quality of the Realsense D435 is somewhat depressing, but it will pass as soon as we deliver at least here is such an interesting 3D scanner from Microsoftwhose point cloud is much more accurate.
Server side
Relay Server
The main functional element is a server in the middle, which receives a video stream from the robot with 3D images and sensor readings and the state of the robot and distributes it among consumers. Input data – packed frames and sensor readings coming over TCP / IP. Distribution to consumers is carried out by web-sockets (a very convenient mechanism for streaming to several consumers, including a browser).
In addition, the staging server stores the data stream in S3 cloud storage so that it can later be used for training.
Each relay server supports the http API, which allows you to find out its current state, which is convenient for monitoring current connections.
The relay task is quite difficult, both in terms of computing and in terms of traffic. Therefore, here we followed the logic that relay servers are deployed on a variety of cloud servers. And, therefore, you need to keep track of who is connecting where (especially if robots and operators in different regions)
Register
The most reliable now will be hard to set for each robot which servers it can connect to (redundancy will not hurt). ML management service is associated with the robot, it polls the relay server to determine which one the robot is connected to and connects to the corresponding one, if, of course, it has enough rights for this. The operator’s application works in a similar way.
The most pleasant! Due to the fact that the training of robots is a service, the service is visible only to us inside. So, its front-end can be as convenient as possible for us! Those. this is the console in the browser (there is a library that is beautiful in its simplicity Terminaljs, which is very easy to modify if you want additional functions, such as auto-completion by pressing the TAB key or playing back call history) and looks like this:
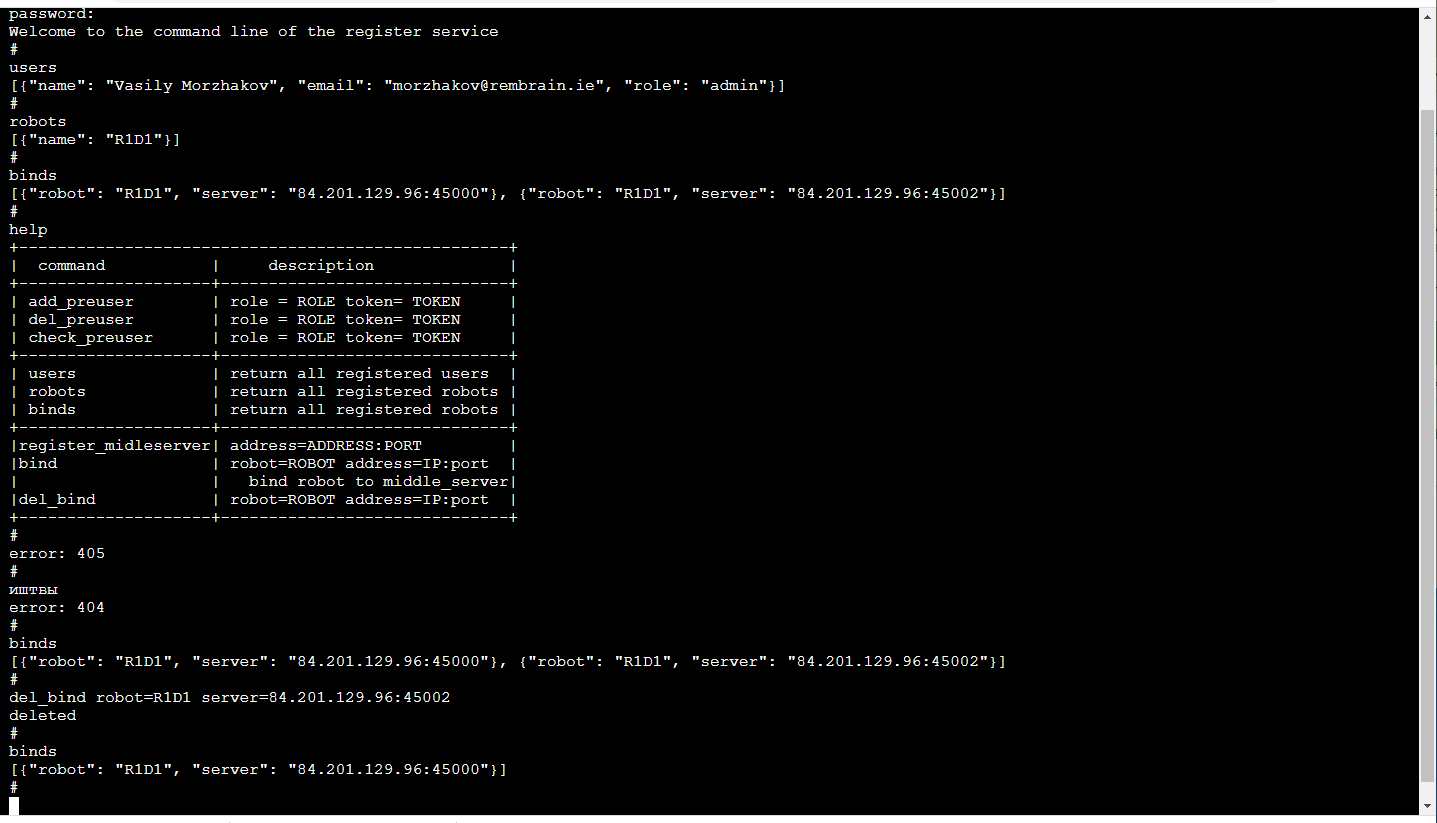
This, of course, is a separate topic for discussion, why is the command line so convenient. By the way, it is especially convenient to do unit testing of such a frontend.
In addition to the http API, this service implements a mechanism for registering users with temporary tokens, login / logout operators, administrators and robots, session support, session encryption keys for traffic encryption between the relay server and the robot.
All this is done in Python with Flask – a very close stack for ML developers (i.e. us). Yes, in addition, the existing CI / CD infrastructure for microservices is on friendly terms with Flask.
Delay problem
If we want to control the manipulators in real time, then the minimum delay is extremely useful. If the delay becomes too large (more than 300ms), it is very difficult to control the manipulators based on the image in the virtual helmet. In our solution, due to frame-by-frame compression (i.e., there is no buffering) and not using standard tools like GStreamer, the delay even taking into account the intermediate server is about 150-200ms. The transmission time over the network of them is about 80ms. The rest of the delay is caused by the Realsense D435 camera and the limited capture frequency.
Of course, this is a problem in full growth arises in the “tracking” mode, when the manipulator in its reality constantly follows the controller of the operator in virtual reality. In the mode of moving to a given point XYZ, the delay does not cause any problems for the operator.
ML part
There are 2 types of services: management and training.
The training service collects the data stored in the S3 storage and starts the re-training of the model weights. At the end of the training, weights are sent to the management service.
The management service is no different in terms of input and output data from the operator’s application. Likewise, the input RGBD (RGB + Depth) stream, sensor readings and robot status, the output – control commands. Due to this identity, it appears possible to train in the framework of the concept of “data-driven training”.
The state of the robot (and sensor readings) is a key story for ML. It defines the context. For example, a robot will have a state machine characteristic of its operation, which largely determines what kind of control is necessary. These 2 values are transmitted along with each frame: the operating mode and the state vector of the robot.
And a little about training:
In the demonstration, at the end of the article was the task of finding an object (a children’s cube) on a 3D scene. This is a basic task for pick & place applications.
The training was based on a pair of “before and after” frames and target designation obtained with manual control:

Due to the presence of two depth maps, it was easy to calculate the mask of the object moved in the frame:
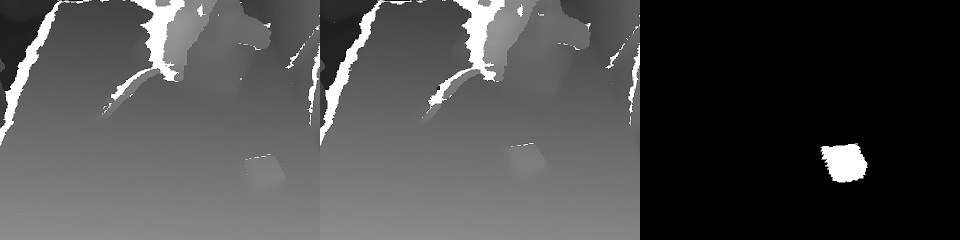
In addition, xyz are projected onto the plane of the camera and you can select the neighborhood of the captured object:
Actually with this neighborhood and will work.
We get XY primarily by training Unet a convolutional network for segmenting a cube.
Then, we need to determine the depth and understand if the image is abnormal in front of us. This is done using an auto encoder in RGB and a conditional auto encoder in depth.
Model Architecture for Auto Encoder Training:
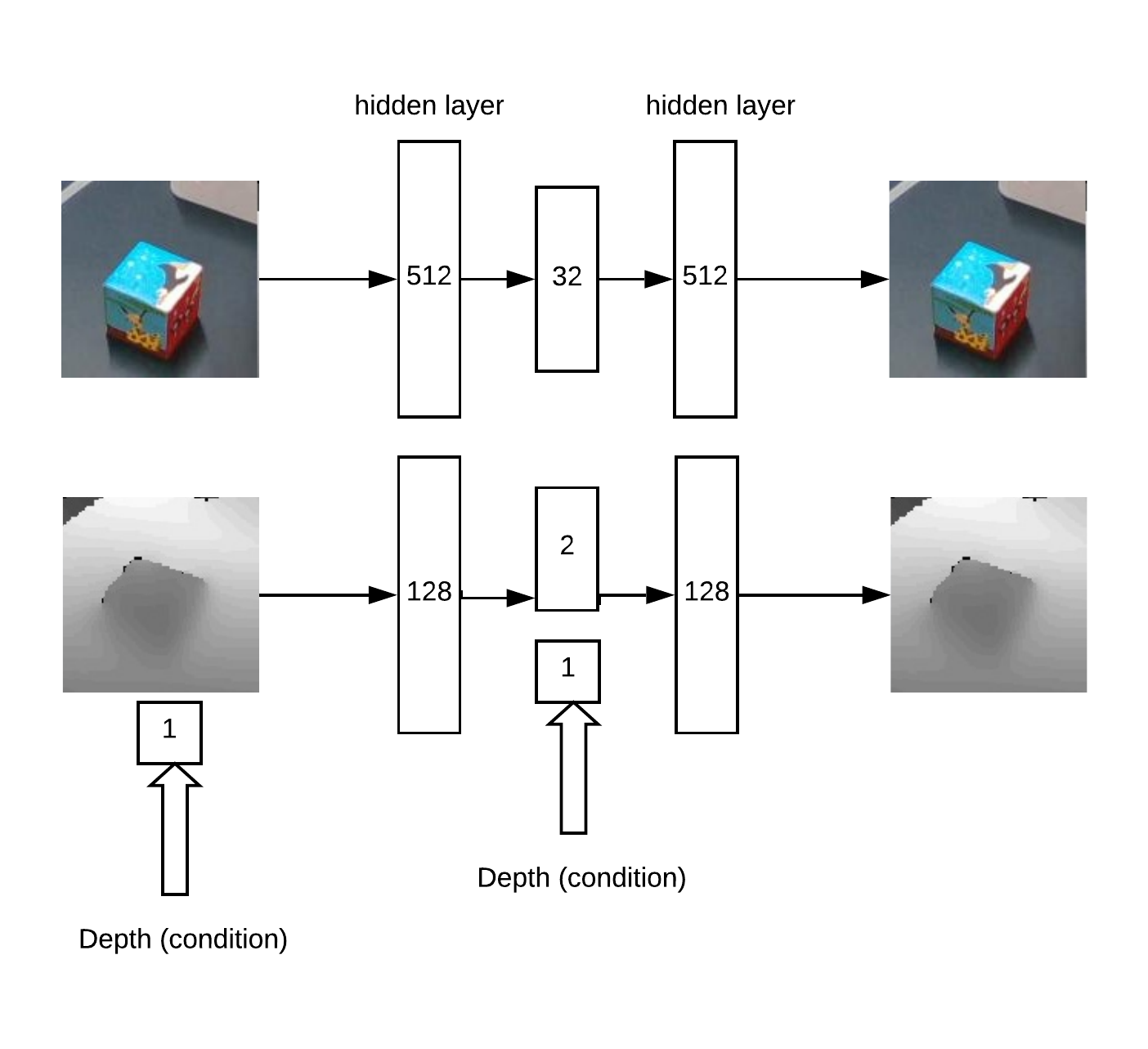
As a result, the logic of work:
- search for a maximum on the “heat map” (determine the angular u = x / z v = y / z coordinates of the object) that exceeds the threshold
- then the auto encoder reconstructs the neighborhood of the found point for all hypotheses in depth (with a given step from min_depth to max_depth) and selects the depth at which the discrepancy between reconstruction and input is minimal
- Having the angular coordinates u, v and depth, you can get the coordinates x, y, z
Example of auto-encoder reconstruction of a map of cube depths at a correctly defined depth:
In part, the idea of a depth search method is built on article about auto encoder sets.
This approach works well for objects of various shapes.
But, in general, there are many different approaches for finding an XYZ object from an RGBD image. Of course, it is necessary in practice and on a large amount of data to choose the most accurate method.
There was also the task of detecting anomalies, for this we need a segmentation convolutional network to learn from the available masks. Then, according to this mask, you can evaluate the accuracy of the reconstruction of the auto-encoder in the depth map and RGB. For this discrepancy, you can decide on the presence of an anomaly.
Due to this method, it is possible to detect the appearance of previously unseen objects in the frame, which are nevertheless detected by the primary search algorithm.
Demonstration
Checking and debugging of the entire created software platform was carried out at the stand:
- 3D camera Realsense D435
- 4-axis Robot Arm Dobot Magician
- VR helmet HTC Vive
- Servers on Yandex Cloud (reduces latency compared to AWS cloud)
In the video, we teach how to find a cube in a 3D scene by performing a task in VR pick & place. About 50 examples were enough for training on a cube. Then the object changes and about 30 more examples are shown. After retraining, the robot can find a new object.
The entire process took about 15 minutes, of which about half – training model weights.
And in this video, YuMi controls in VR. To learn how to manipulate objects, you need to evaluate the orientation and location of the tool. Mathematics is built on a similar principle, but is now at the testing and development stage.