Large hierarchy in SQL query + PostgreSQL
This is a continuation
articles part 1 and part 2, which propose a solution to the problem of visualizing a hierarchical structure or part of it using SQL queries using the example of MySQL and SQLite
Adding PostgreSQL support
First, I adapt the query to work in PostgreSQL.
Trying to run queries from the previous parts in PostgreSQL 15.6 causes an error:
ERROR: in the recursive query “levels”, column 4 is of type
character(2000)in the non-recursive part, but the resulting typebpchar
LINE 23:cast(parent_node_id as char(2000)) as parents,
^
HINT: Cast the result of the non-recursive part to the correct type.
This is somewhat unexpected (at least for me) – "bpchar" This "blank-padded char"in theory the same as char(с указанием длины). I won't argue, I'll just replace it everywhere char() on varchar:
The same long request from part 2
with recursive
Mapping as (
select
id as node_id,
parent_directory_id as parent_node_id,
name as node_name
from Files
),
RootNodes as (
select node_id as root_node_id
from Mapping
where -- Exactly one line below should be uncommented
-- parent_node_id is null -- Uncomment to build from root(s)
node_id in (3, 10, 17) -- Uncomment to add node_id(s) into the brackets
),
Levels as (
select
node_id,
parent_node_id,
node_name,
cast(parent_node_id as varchar) as parents,
cast(node_name as varchar) as full_path,
0 as node_level
from
Mapping
inner join RootNodes on node_id = root_node_id
union
select
Mapping.node_id,
Mapping.parent_node_id,
Mapping.node_name,
concat(coalesce(concat(prev.parents, '-'), ''), cast(Mapping.parent_node_id as varchar)),
concat_ws(' ', prev.full_path, Mapping.node_name),
prev.node_level + 1
from
Levels as prev
inner join Mapping on Mapping.parent_node_id = prev.node_id
),
Branches as (
select
node_id,
parent_node_id,
node_name,
parents,
full_path,
node_level,
case
when root_node_id is null then
case
when node_id = last_value(node_id) over WindowByParents then '└── '
else '├── '
end
else ''
end as node_branch,
case
when root_node_id is null then
case
when node_id = last_value(node_id) over WindowByParents then ' '
else '│ '
end
else ''
end as branch_through
from
Levels
left join RootNodes on node_id = root_node_id
window WindowByParents as (
partition by parents
order by node_name
rows between current row and unbounded following
)
order by full_path
),
Tree as (
select
node_id,
parent_node_id,
node_name,
parents,
full_path,
node_level,
node_branch,
cast(branch_through as varchar) as all_through
from
Branches
inner join RootNodes on node_id = root_node_id
union
select
Branches.node_id,
Branches.parent_node_id,
Branches.node_name,
Branches.parents,
Branches.full_path,
Branches.node_level,
Branches.node_branch,
concat(prev.all_through, Branches.branch_through)
from
Tree as prev
inner join Branches on Branches.parent_node_id = prev.node_id
),
FineTree as (
select
tr.node_id,
tr.parent_node_id,
tr.node_name,
tr.parents,
tr.full_path,
tr.node_level,
concat(coalesce(parent.all_through, ''), tr.node_branch, tr.node_name) as fine_tree
from
Tree as tr
left join Tree as parent on
parent.node_id = tr.parent_node_id
order by tr.full_path
)
select fine_tree, node_id from FineTree
;This was enough for the request to work as expected:
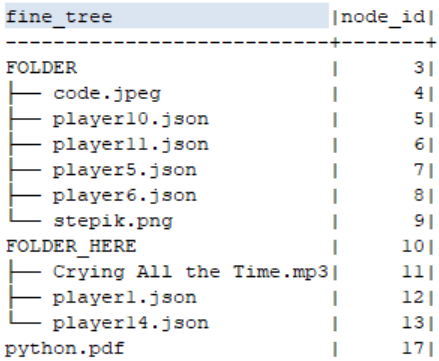
Possibly use varchar without specifying the length carries limitations that cannot be encountered in such a compact hierarchy – as usual, I “suspect” the field full_path
To check the restrictions, a relatively large hierarchy is needed, all that remains is to get it.
Large hierarchy (80,000+ elements)
I will not discuss the topic “why is it necessary to visualize such a voluminous hierarchy.”
This is done to check the operation of the script and identify its possible limitations.
A convenient way to obtain large hierarchies is to use a zip archive structure. As a test subject, you can take a large project with Git – for example, OpenJDK (83499 folders and files for the version 22 I used).

To download the archive, you need to select from the drop-down menu Download ZIP (archive volume 181 MB)
gen_table()
To generate an SQL script for creating a table and inserting rows with the archive structure into it, I wrote the gen_table() function in Python
#
# Generate SQL-script for creation of hierarchical table by zip-archive structure
#
from zipfile import ZipFile
from itertools import count
def file_size_b(file_size):
""" Returns file size string in XBytes """
for b in ["B", "KB", "MB", "GB", "TB"]:
if file_size < 1024:
break
file_size /= 1024
return f"{round(file_size)} {b}"
def gen_table(zip_file, table_name="ZipArchive", chunk_size=10000, out_extension='sql'):
"""
by iqu 2024-04-28
params:
zip_file - zip archive full path
table_name - table to be created
chunk_size - limit values() for each insert into part
out extension - replaces zip archive file extension
-> None, creates file with SQL script.
Create table columns:
id, name, parent_id, file_size - obvious,
bytes - string with file size generated by file_size_b()
"""
def gen_create_table(file):
print(f"drop table if exists {table_name};", file=file)
print(f"create table {table_name} (id int, name varchar(255), parent_id int, file_size int, bytes varchar(16))"
, file=file)
def gen_insert(file):
print(f";\ninsert into {table_name} (id, name, parent_id, file_size, bytes) values", file=file)
out_file = ".".join(zip_file.split(".")[:-1] + [out_extension])
cnt = count()
parents = ['NULL']
with open(out_file, mode="w") as of:
gen_create_table(of)
with ZipFile(zip_file) as zf:
for zi in zf.infolist():
zi_id = cnt.__next__()
if zi_id % chunk_size == 0:
gen_insert(of)
delimiter=""
else:
delimiter=","
level = zi.filename.count("/") - zi.is_dir()
name = zi.filename.split("/")[level]
file_size = -1 if zi.is_dir() else zi.file_size
file_size_s="DIR" if zi.is_dir() else file_size_b(zi.file_size)
if zi.is_dir():
if len(parents) < level + 2:
parents.append(f"{zi_id}")
else:
parents[level + 1] = f"{zi_id}"
print(f"{delimiter}({zi_id}, '{name}', {parents[level]}, {file_size}, '{file_size_s}')", file=of)
print(';', file=of)
gen_table(r"C:\TEMP\jdk-master.zip") # Sample archive https://github.com/openjdk/jdk/archive/refs/heads/master.zip
I won’t explain the code in detail, this is completely off topic of the article. It is important that the script is divided into parts of maximum length chunk_size (10,000 by default) in each block values()
In addition to ID, name and parent reference, each record contains a field file_size with length in bytes (-1 for folders) and field bytes with the length converted to a string in bytes, kilobytes, etc. ('DIR' for folders)
By passing the path to the archive downloaded above as a parameter to the function, I received an SQL script for creating a hierarchy. I won’t attach it, its archive “weighs” almost 1MB, the method for obtaining it is described in detail
The script for adding records consists of 9 parts. It ran successfully in all three “experimental” DBMSs. No indexes were created.
Validation in MySQL, SQLite and PostgreSQL
To check MySQL and SQLite I will use the script from the second part of the article, for PostgreSQL – attached at the beginning of this article
I will give the execution time of the scripts on my home PC running Windows 10. All DBMSs are installed in the C:\ partition located on the SSD, and the database files are located on it. All settings when installing the DBMS are by default.
All scripts are executed from DBeaver 24.0.2, the time is rounded – the task is not to compare the DBMS with each other, but to check the performance of the scripts in their environments.
For variety, the string file size in parentheses will be added to the node name, and the node level in the hierarchy will also be extracted from the final CTE:
with recursive
Mapping as (
select
id as node_id,
parent_id as parent_node_id,
concat(name, ' (', bytes, ')') as node_name
from ZipArchive
),
...
select fine_tree, node_id, node_level from FineTree
;Script | MySQL 8.2 | SQLite 3 | PostgreSQL 15.6 |
| 1800ms | 200ms | 500ms |
Hierarchy | 2s | 1 s | 3s |
When creating and filling the table, I was guided by the statistics displayed after executing the script

Example for SQLite
The largest nesting of the hierarchy is 16
The order in which the hierarchy is displayed differs slightly between DBMSs – for SQLite it is case sensitive, and MySQL and PostgreSQL sort some characters differently:


Within one DBMS the output is stable
Share in the comments which of the most extensive hierarchies you were able to visualize, and whether you were able to achieve anomalies when running the scripts.
This concludes the series of articles, thank you everyone for your interest – this came as a surprise to me, since there is no practical component in the articles)))