How to do pruning so you don't cry later

Pruning neural networks or, if you delve into the terms, pruning is what helps reduce the size of our model without losing its effectiveness. Yes, this is far from a new thing – they talked about it in Stanford lectures back in 2017!
The idea is simple: we simply remove from the model everything that we do not need. Like in a store when you decide to save money: if there are extra items in the basket, why not remove them? It’s the same here – we remove redundant neurons and connections that only take up space but do not bring much benefit.
The principle of pruning can be applied in different situations. For example, if we have a model that is trained to recognize one hundred object classes, but we actually only need ten, then why not remove those ninety extra ones? This will allow us to make a smaller model, but no less effective. And if we are creating a model from scratch, then trimming can help us immediately make it more compact and efficient.
In short, pruning is for those who want to make their models lighter and faster without losing quality.
Why cut neural networks at all?
To understand this, you can imagine that the neural network is a rocket. Each element in this rocket has its own important role: from engines to navigation systems. And, as with any complex system, neural networks can become redundant, containing unnecessary elements that can slow them down or even lead to undesirable consequences.
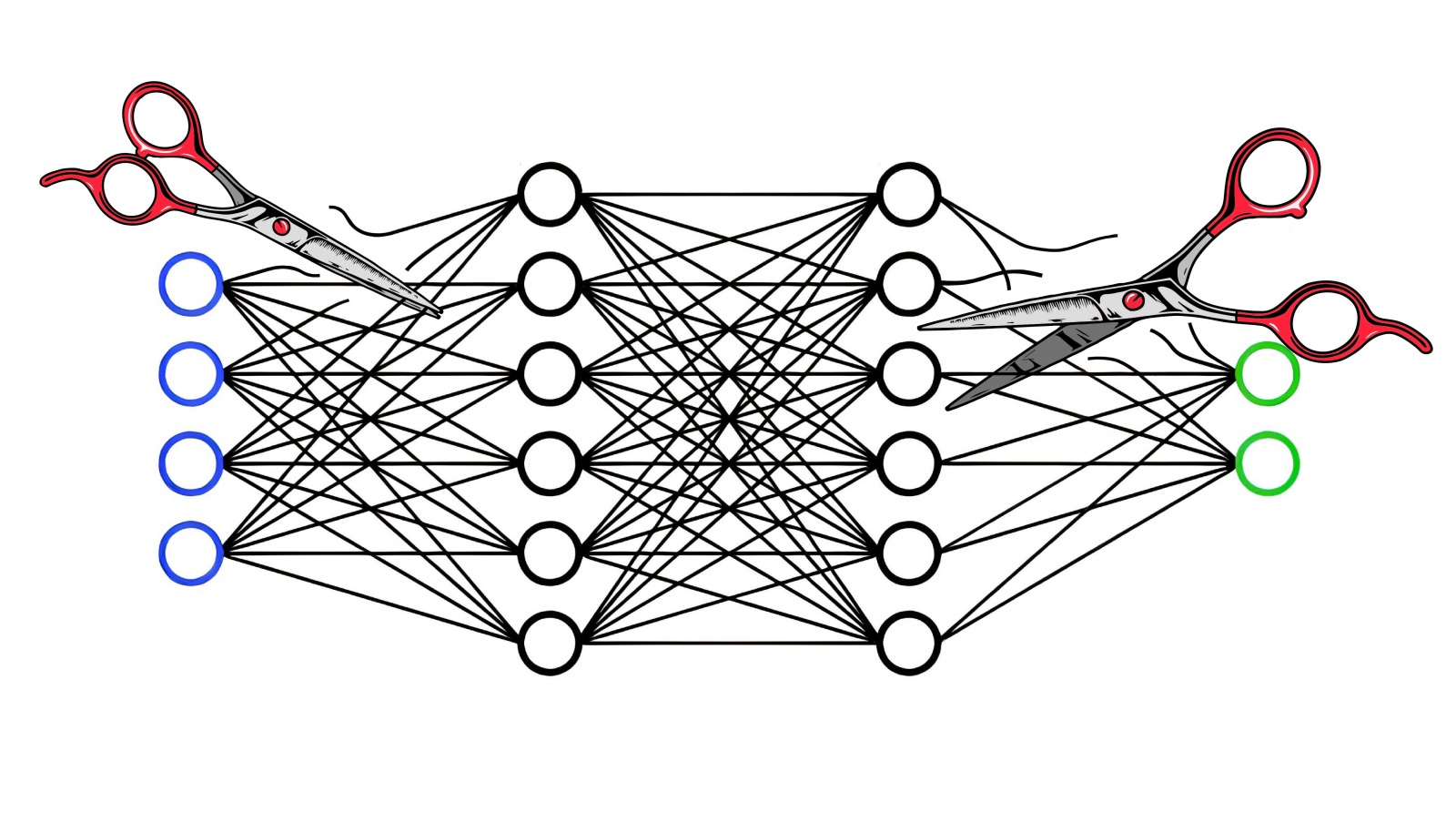
Pruning is just like optimizing a rocket before launch. We look for and remove “extra” connections between neurons that carry little or no valuable information. This makes neural networks lighter and more efficient.
This is why pruning is so important. It allows us to create more efficient neural networks that can perform their tasks better. This is especially true when working with limited resources, such as on mobile devices or in cloud computing.
The use of pruning also helps make neural networks more resistant to overfitting. By removing redundant connections, we create simpler, more efficient models that better generalize information from the training data.
To make it even clearer, we can look at pruning from a biological point of view, using an analogy with the real human brain. The Model Pruning process, like the mechanisms of brain plasticity, is associated with the ability of a system to adapt and change in response to changing conditions.

Brain plasticity is the brain's ability to change its structure and function as a result of experience and learning. Just as the brain can reorganize its neural connections to adapt to new conditions, neural connections in a neural network can be removed or changed to optimize its performance.
This can be compared to the way the brain reorganizes its structure to better adapt to new conditions. Flexibility is the key. And pruning allows you to create more flexible neural networks, capable of solving problems to the maximum with minimal use of resources.
What tools to use and what to cut
Is it possible to understand how each weight affects the operation of the entire neural network? Undoubtedly. To do this, we use weight analysis tools.
Here's how it works: imagine that each weight in our neural network is like a block in that board game, Jenga. In this game you need to understand which block is important for a wooden tower, and which one can be carefully removed without damaging the entire structure. It’s the same here: we analyze the impact of each weight on the operation of the entire network.
One of the tools we use for this is called weight significance analysis. We look and analyze what weight somehow affects the network output. If some weight makes a very small contribution to the final result, we can think about throwing it out of our model.
To understand this, we usually turn to gradient-based methods. We need to understand which weights have the least impact on the change in our error function. Or losses, whichever is more convenient for you.
The loss function is a measure that shows how well a model performs a task. It measures the difference between model predicted values and actual data. The smaller the loss function, the better the model performs. It determines which model parameters need to be changed to reduce error and improve its performance.
To train neural networks, we usually use some kind of loss function that evaluates how close the model's predictions are to the true values. For example, cross-entropy is often used in classification problems, and MSE is often used in regression problems.
Cross-Entropy measures the difference between two probability distributions and is used to evaluate the quality of a classification model.
The lower the cross-entropy, the better the model.
Example in Python:
import numpy as np
def cross_entropy(y_true, y_pred):
# Ограничиваем значения y_pred, чтобы избежать логарифма от нуля
epsilon = 1e-15
y_pred = np.clip(y_pred, epsilon, 1 - epsilon)
# Вычисляем кросс-энтропию
ce = -np.sum(y_true * np.log(y_pred))
return ce
# Пример данных
# Реальные метки (one-hot encoding)
y_true = np.array([0, 0, 1, 0, 0])
# Предсказанные вероятности классов моделью
y_pred = np.array([0.1, 0.2, 0.6, 0.05, 0.05])
# Вычисляем кросс-энтропию
ce = cross_entropy(y_true, y_pred)
print("Cross-Entropy:", ce)In this example, we use numpy to calculate the cross-entropy between the real labels and the model's predicted probabilities.
Mean Squared Error (MSE) measures the standard deviation (the square of the difference) between the model's predicted values and the actual data values.
The lower the MSE value, the better the model.
Example in Python:
import numpy as np
def mean_squared_error(y_true, y_pred):
# Вычисляем квадрат разности между реальными и предсказанными значениями
squared_diff = (y_true - y_pred) ** 2
# Вычисляем среднее значение квадратов разностей
mse = np.mean(squared_diff)
return mse
# Пример данных
y_true = np.array([3, -0.5, 2, 7])
y_pred = np.array([2.5, 0.0, 2, 8])
# Вычисляем среднеквадратичную ошибку
mse = mean_squared_error(y_true, y_pred)
print("Mean Squared Error (MSE):", mse)Here we use numpy to calculate the root mean squared error between the real values and the predicted values of the model.
Thus, if some weight does not significantly change the loss function, then it can be safely removed.
TensorFlow or PyTorch also make life easier when it comes to pruning neural networks. They already contain all the necessary tools and functions to carry out this procedure. Just call the necessary methods, and voila! In general, TF and PT have many tools for analyzing models, which helps to understand which parts of the network can be removed and not worry about throwing out something important. As a result, pruning becomes a matter of a couple of clicks and a little brainstorming, instead of long hours of manually setting up the model.
In what situations will pruning be useless, and in what situations is it necessary at maximum speed?
Now let’s see when pruning is, as they say, “off topic,” and when it is simply necessary.
Let's say you are dealing with a small model, where the number of parameters is not particularly large. In such cases, pruning may simply not bring a noticeable improvement, but the costs of its implementation may be unreasonably high. It's like trying to lose weight for someone who is already in great shape. I miscalculated, but where?

Another case is scale. If your model is a monster with millions of parameters that take up a lot of space and time for training, then pruning will come in handy here. You remove those neurons that have little effect on the results, and the model becomes smaller and faster, but at the same time retains its efficiency.
We can say that pruning is like clearing the brain of information garbage that prevents it from working effectively. When we remove unnecessary weights and connections in a neural network, we essentially rid it of redundant information, which helps make it easier and faster to operate and improve its decision-making ability.
Why is this even necessary: let’s look at examples
We have already realized that pruning is an important thing in ML. Now let’s finally figure out why all this is needed, and why bother with the extensive pruning of neural networks.
Let's say you have a neural network for image recognition. She can distinguish between cats, dogs, cars and other objects. But damn: this model has too many weights and neural connections, which is why she can barely plow… This is where neurofitness – pruning – will help her.
Much like on a diet: when extra pounds prevent us from moving, we begin to remove all sorts of crap from our diet in order to lose weight and improve our health. In the case of neural networks, we remove redundant connections and weights to make the network lighter and faster. And it works just as well, if not better!
Here's a simple example in Python:
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
# Создаем простую модель
model = Sequential([
Dense(128, activation='relu', input_shape=(784,)),
Dense(64, activation='relu'),
Dense(10, activation='softmax')
])
# Компилируем модель
model.compile(optimizer="adam",
loss="sparse_categorical_crossentropy",
metrics=['accuracy'])
# Обучаем модель (тут, конечно, используйте свои данные)
model.fit(x_train, y_train, epochs=5)
# Проводим прунинг
pruned_model = prune_low_magnitude(model)
pruned_model.compile(optimizer="adam",
loss="sparse_categorical_crossentropy",
metrics=['accuracy'])
# И снова обучаем
pruned_model.fit(x_train, y_train, epochs=3)This is how pruning helps make our models lighter and faster without losing quality!
How to do pruning so you don't cry later

Let's figure out how to do pruning so you don't cry from unwanted consequences later. First, always keep in mind that pruning can lead to a loss of model quality. Therefore, before you begin, carefully evaluate how much you can reduce the size of your network without significantly compromising its performance.
Secondly, choose the right methods and strategies. There are several approaches to selecting neurons or weights for removal (we discussed this above). The choice of the correct method depends on the characteristics of the model and the specific task.
The third tip is to not remove too much at once. It is better to start with a small number of neurons or weights and gradually increase, while checking the quality of the model on a validation dataset.
And of course, always test changes. After each pruning step, carefully evaluate the model's performance on the test dataset. This will help avoid unpleasant surprises in the form of loss of quality.
And one last thing: be prepared for the fact that it is not always possible to achieve a significant reduction in the size of the model without loss of accuracy. So keep in mind that pruning is an optimization tool and not a universal solution for reducing the size of models.
We hit a wall: what to do if everything went… not as planned
The first problem you may encounter is the loss of model quality after pruning. Yes, this is exactly what we warn about throughout the entire article.
There is a solution, but few people like it. It is necessary to carefully test the models after each stage of pruning. This will allow you to identify deterioration in performance and, if necessary, adjust the process of removing weights and links.
The second problem is the difficulty of choosing the optimal pruning strategy. Yes, as discussed above, there are many different methods and approaches to pruning, and choosing the right one can be non-trivial. It is recommended to start with simple methods and gradually move on to more complex ones, while assessing the impact of each method on the performance of the model.
The third problem is the difficulty of maintaining updated models. After pruning, the model may require revision and updating of other components, such as optimizers and hyperparameters. To solve this problem, it is important to develop a strategy for automatically updating the model and its components after pruning.
And finally, the fourth difficulty is managing the pruning process. This can be a time-consuming and resource-intensive process, especially when working with large models and datasets. To solve this problem, it is important to optimize the pruning process, for example, using distributed computing or specialized hardware solutions.

Overall, it is important to remember that pruning is not an end goal, but a tool for optimizing models. Difficulties may arise. And that's okay. But with the right approach and strategies, they can be overcome and achieve good results.
This is not the end, this is just the beginning
By the way, pruning is not the end goal. There is still a lot of work that needs to be done after.
And after pruning, the time comes for tuning, optimizing and adapting the model to new conditions and tasks. We can explore knowledge distillation techniques that will help transfer knowledge from a large model to a truncated one. You can also consider various compression and quantization methods to achieve even greater efficiency of models on devices with limited resources.
Overall, there is still a lot of work to be done, but this is all what helps us realize the importance of work. After all, this is the only way to develop, constantly improving the old and creating the new.