How kittens use their paws to configure GPUs in Kubernetes and what the Mandela effect has to do with it
 We invite you to Selectel Tech Day on October 10
We invite you to Selectel Tech Day on October 10
We will tell you about new products on the market and updates in our products. You will find reports, networking, master classes and an evening program. Participation is free, but it is necessary register.
Use navigation if you don't want to read the full text:
→
Problems with GPU setup on servers
→
What to consider when configuring a GPU on a server
→
A short guide to choosing drivers
→
→
Automate GPU setup with operator
→
→
→
The Mandela Effect in the nvidia-smi team
→
→
→
→
→
Sharing resources on one video card
→
Problems with GPU setup on servers
Let's imagine a situation. We want to train models or infer on the GPU. To do this, we use PyTorch or Tensorflow, and to ensure that the frameworks have direct access to the GPU, we install CUDA. The main pain we face is the dependencies of different versions of frameworks, CUDA, and drivers on each other. And also the complexity of managing them in the infrastructure.
What to consider when configuring a GPU on a server
Let's say we want to train our model on a remote virtual server, in some Jupiter Lab with access to GPU. To do this, we need to perform a certain set of actions.
- Connect the GPU directly to the server. If it is a cloud, then the GPU is also forwarded to a specific host.
- Get the right driver version for a specific video card. In the case of NVIDIA, you can use calculatorm.
- Install the required version of CUDA.
- If we work with containerization, set it up NVIDIA container toolkit. You will need to make some small changes to the config etc/containerd/config.toml of our daemon (docker or containerd) — specify the correct value for the default_runtime_name parameter. Or, when starting, specify the –runtime=NVIDIA flag in the container.
At the same time, it is necessary to remember the dependencies of various system components. Let's look at an example with the Tesla T4 GPU.

Framework compatibility

The same version of PyTorch can be relevant for different versions of CUDA. In this case, installation via
pip
may vary – for example, for CUDA 11.8 or 12.4 you need to specify it via the flag
–index-url
special repository:
pip3 install torch torchvision torchaudio \
--index-url https://download.pytorch.org/whl/<cu118 или cu124>
Also, for each version of CUDA, it is necessary to take into account that a special version of the driver is required.
It turns out that the framework version depends on the CUDA version, and the CUDA version depends on the driver version. Do you think that's all we can disagree on?
Driver Compatibility
In practice, there are several other factors to consider. The driver version must match the OS and Linux kernel version.
The upper limit of the version number is limited by the architecture. For example, the Kepler architecture will not allow installing a driver higher than version 475, which means that new versions of CUDA will not be available.

It is also necessary to take into account the purpose of the video card – it can be a regular one (GTX 1080, 2080, etc., for example, for playing Cyberpunk), as well as specialized (A100, Tesla T4, A2, etc., for example, for data centers). Different types of GPUs have their own versions of CUDA and different series of drivers are allowed. You can read more on the NVIDIA website in the sections for
And
.
Isn't it very difficult to keep all these dependencies in your head? In your Telegram channel I have collected links to useful sources and component compatibility. Study and save for your convenience!
OS kernel compatibility
Unfortunately, we couldn't find a source describing the compatibility of drivers with different Linux kernels: there is only CUDA. This lack of information about the specifics of video cards once affected the possibility of using some of our cloud images on Kubernetes nodes with pre-installed drivers.
According to the security policy, we update images once a week. At one point, the Linux kernel in Ubuntu 22.04 was updated to version 5.15.0-113. It suddenly turned out that the 520th version of the driver, which was used by default, is not compatible with all kernels.

I had to urgently update the driver to the latest version. That's why you need to keep your GPU drivers up to date as carefully as you keep your Linux kernel up to date!
A short guide to choosing drivers
To avoid digging into all the dependencies yourself, I offer a small algorithm for choosing the appropriate version of GPU drivers.
Let's imagine a typical case. We install the latest drivers by default. All of them are backward compatible with CUDA – they work with its previous versions.
We reproduce the customer's infrastructure. We take the driver exactly as in the reproduced infrastructure.
If we cannot use the latest driver, we rely on the OS and kernel version. In the list of supported driver versions different GPUs, we look for the architecture of our video processor. Ongoing means that the latest release is supported. If there is an upper limit for the version number, we take it into account.
Let's not forget that kernels also limit the available CUDA versions. And also tasks and framework. Therefore, it is better to use containers in your infrastructure to launch CUDA, and install only drivers on virtual servers. NVIDIA containers already prepared.
What's in Kubernetes?
We've figured out how to configure drivers and CUDA on a virtual machine. Now let's learn how to do it in Kubernetes.
In addition to the above, several conditions must be met.
- On the nodes it is necessary to mark where which GPU is allocated. This can be done using labels.
- It is important to consider the capacity of resources: if pods are placed on nodes with GPUs, then their occupancy must be marked.
- GPU monitoring should be organized using DCGM to receive feedback.

The difference between manual and automatic configuration of GPU clusters.
As you can see, the main problem is that if you configure the GPU to run the models manually, you need to take into account the interdependencies of CUDA, frameworks, drivers, and also carefully monitor the constant updates and cluster management. But since we don’t want to “get our paws dirty”, let’s see how NVIDIA’s GPU operator copes with this.
Automate GPU setup with operator
GPU operator — is a set of services that are installed into a Kubernetes cluster using Helm charts.

GPU operator services.
The list of all services is available in the documentation on the NVIDIA websitebut we will only go over the main ones.
- Nvidia feature discovery using labels automatically marks nodes according to the features found. For example, the name of the GPU assigned to the node.
- NVIDIA container runtime installs NVIDIA runtime so that our pods can use the GPU.
- NVIDIA driver container installs the selected driver version on the node.
- NVIDIA Kubernetes device plugin — a service that allows you to manage the capacity of available GPUs through Kubernetes resources. It puts the resource on nodes nvidia.com/gpuwhere the integer denotes the number of available video processors.
- NVIDIA dcgm monitoring installs an exporter from DCGM, where we track GPU, utilization and memory.
Services are launched in the daemon set format – on all nodes that satisfy the selected node selector.
Quick start
To install all services, you can use the default settings in
values.yaml
Helm chart, plus specify the required GPU driver version. This will be enough for cases where a cluster ready to launch pods with access to the video processor is required.
By the way, an update was recently released in Managed Kubernetes. Now it is possible to deploy nodes with GPU without pre-installed drivers! This means that you can install a GPU operator and manage GPU node configurations yourself. To try it, just uncheck the box GPU Drivers when configuring.

Setting up a node in the control panel.
1. Let's add the official NVIDIA Helm charts repository:
helm repo add NVIDIA https://helm.ngc.NVIDIA.com/NVIDIA \
&& helm repo update</b>
2. Install the drivers with the selected version:
helm install --wait --generate-name \
-n gpu-operator --create-namespace \
NVIDIA/gpu-operator \
--set driver.version=<option-value>
Done! If the case is simple enough, at this stage the configuration of GPUs in clusters can already be considered automated.
Important. The GPU operator prepares the cluster to use containers with GPU access. It installs the driver and container toolkit, but does not load CUDA — you operate its version in containers yourself.
For those who are not suited to simple universal cases, I suggest considering more complex options for using the GPU operator.
Multi-driver
It is not always possible to install the latest driver release for a specific infrastructure. Therefore, it is useful to support the installation of different versions on Kubernetes nodes if they work with GPUs that do not support the latest driver releases or use different Linux kernels. For such cases, the GPU operator provides
which allow you to install drivers of different freshness on individual nodes. How to do this?
1. Let's create a CRD with the driver version and specify the node selector so that the drivers are installed only on nodes that have the corresponding label:
apiVersion: NVIDIA.com/v1alpha1
kind: NVIDIADriver
metadata:
name: driver-550
spec:
driverType: gpu
env: []
image: driver
imagePullPolicy: IfNotPresent
imagePullSecrets: []
manager: {}
nodeSelector:
driver.config: "driver-550"
repository: nvcr.io/NVIDIA
version: "550.90.07"
2. Set the label for the required node:
kubectl label node <name> --overwrite \
driver.config="driver-550"
3. Set up a chart with the required options:
helm install --wait --generate-name \
-n gpu-operator --create-namespace \
NVIDIA/gpu-operator \
--set driver.NVIDIADriverCRD.enabled=true
4. Using the manifest below, you can check the driver with the command
nvidia sm
– it will show the driver version if everything was installed successfully:
apiVersion: v1
kind: Pod
metadata:
name: NVIDIA-smi-550-90-07
spec:
containers:
- name: NVIDIA-smi-550-90-07
image: "nvcr.io/NVIDIA/driver:550.90.07-ubuntu22.04"
command:
- "NVIDIA-smi"
resources:
limits:
NVIDIA.com/gpu: 1
The Mandela Effect in the nvidia-smi team
When I first encountered this team, I experienced that very
. Let's look at the output:

Output of the nvidia-smi command.
Team nvidia sm shows the current version of the installed driver, information about the GPU and, as you can see in the upper right corner, the CUDA version. Note! This is the compatible version, not the installed one, which can be found out using nvcc –version. Remember this every time you see this sign.
Please write in the comments if you have encountered this feature and if you really thought you were seeing an installed version of CUDA.
Precompiled Driver Containers
It happens that the cluster does not have enough computing power for the usual installation of drivers, since kernel compilation requires resources. Or there is no Internet access in the cluster to download additional packages from the common network during the installation process. In this case, we can help
Ready-made containers from NVIDIA
which already contain compiled drivers.
It should be noted that NVIDIA's proposal has several limitations. It is not yet ready for production use and is only compatible with Ubuntu 22.04. However, the solution is quite functional. Containers can be taken in NGC Catalog and host it in a private Docker repository, such as Selectel CRaaS. NVIDIA's documentation also describes in detail self-assembly of containers.
Using containers is quite simple, you just need to specify certain parameters in the Helm chart:
helm install --wait gpu-operator \
-n gpu-operator --create-namespace \
NVIDIA/gpu-operator \
--set driver.usePrecompiled=true \
--set driver.version="<driver-branch>"
Also
use containers in pairs with CRDs for multi-driver support.
How we use the GPU operator
Typical use case
We are developing
where services with access to GPU are used, such as ClearML, JupyterHub, KServe. We deploy these services on the basis of Managed Kubernetes, where we install the GPU operator.
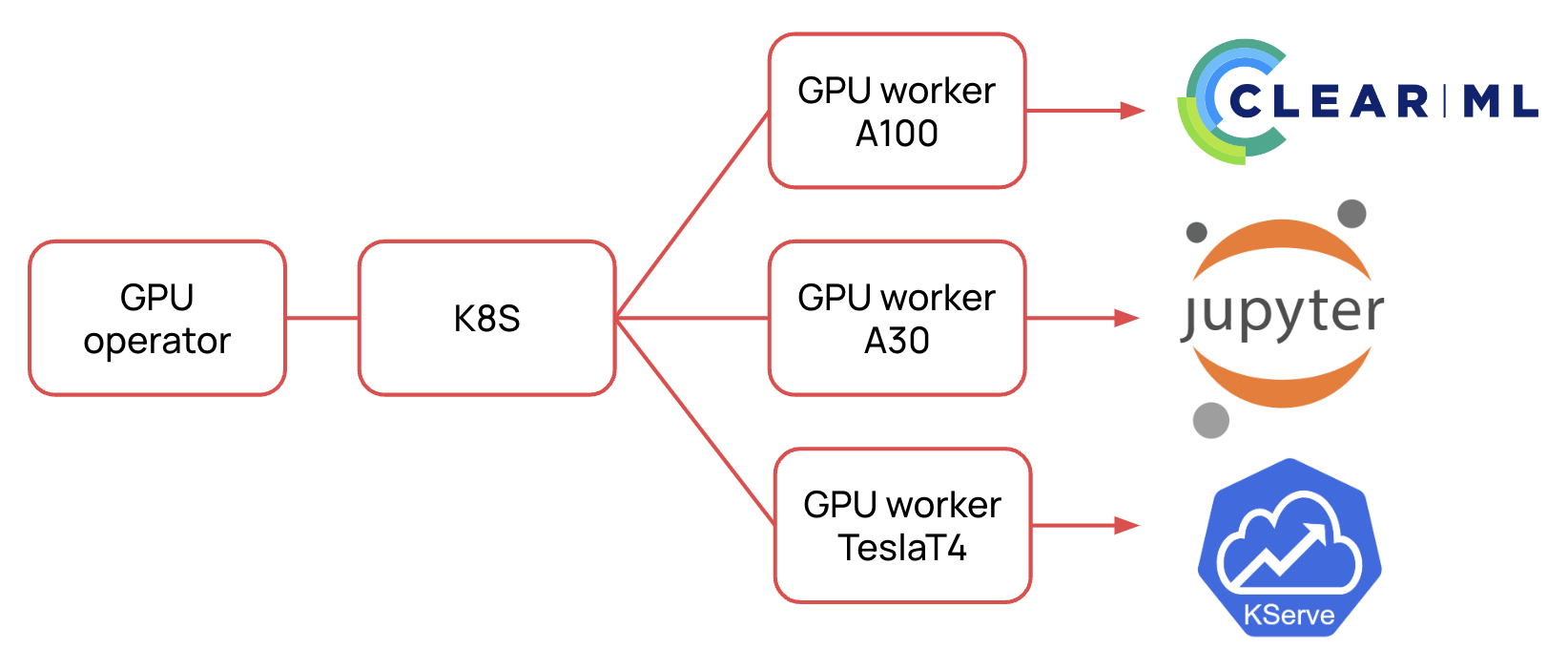
How we deploy a GPU cluster.
The basic scenario is simple. We deploy the platform using Terraform and set up all the services via Helm charts. I described how we do this in more detail in the article. In this case, the GPU operator marks the nodes, sets up the latest driver version, and declares the resources nvidia.com/gpu.
Autoscaling
In our
Managed Kubernetes
GPU node autoscaling is available. If you have a Horizontal Pod Autoscaler configured, then when the specified metric is exceeded, it will raise a pod that will require the nvidia.com/gpu resource. If it is not available, the autoscaler will raise a new node with a GPU, and the operator will install the required driver version and container toolkit inside using daemonsets. Then the resource will become available, and the pod will be allocated to the new node.

How autoscaling works in Kubernetes.
By the way, I will talk about this in more detail at the webinar that will take place… And based on your feedback, I will write an article on how to do GPU node autoscaling with your own hands.
Sharing resources on one video card
We also use the GPU operator to run multiple ML instances on a single video card. I wrote more about how this works in a series of articles
about GPU sharing
. I would like to note that the GPU operator now officially supports
MPS
– this means that there are more opportunities for sharing video cards!
Conclusion
Configuring servers to work with GPUs is not the most trivial task, which requires a lot of manual operations. And it’s good that the guys from NVIDIA were able to automate this process with a special operator, working with which does not require any special effort or knowledge of the Ops part.
Write in the comments what difficulties you encounter when preparing your infrastructure for working with ML tasks. Let's share our experience together!





