Gradient descent and loss landscape animations of neural networks in Python

Figure 1 – Loss landscape of a convolutional neural network with 56 layers (VGG-56, a source)
The above image shows a neural network landscape with a high degree of surface loss. A loss landscape is a visual representation of the values that the cost function takes on for a given range of parameter values based on our training data. Since our goal is to visualize costs in three dimensions, we need to choose two specific parameters that will vary in our graphs, while all other parameters of the model remain unchanged. It is worth noting, however, that there are more advanced techniques (eg dimensionality reduction, filter normalization) that can be used to approximate neural network loss landscapes in low-dimensional subspaces. A 3D representation of the loss landscape of a 56-layer VGG neural network is shown in Figure 1. However, this is beyond the scope of this article.
The artificial neural network we will be working with consists of one input layer (with 784 nodes), two hidden layers (with 50 and 500 nodes, respectively) and one output layer (with 10 nodes). We will use the sigmoid function as an activation function throughout. The neural network will not be subject to bias. The training data consists of 28×28 pixel images, handwritten digits ranging from 0 to 9 from MNIST dataset… Technically, we could have chosen any of the 784 * 50 + 50 * 500 + 500 * 10 = 69,200 weights that we use in our neural network. I arbitrarily chose to use the weights w250, 5 (2) and w251.5 (2), which connect the 250th and 251st nodes of the second hidden layer with the 6th output neuron, respectively. In our model, the 6th output neuron returns activation for the model, predicting the presence of the digit “5” in the image. Figure 2 schematically shows the neural network architecture we will be working with. For reasons of clarity, some of the connections between neurons – and most of the weight annotations – have been intentionally omitted.
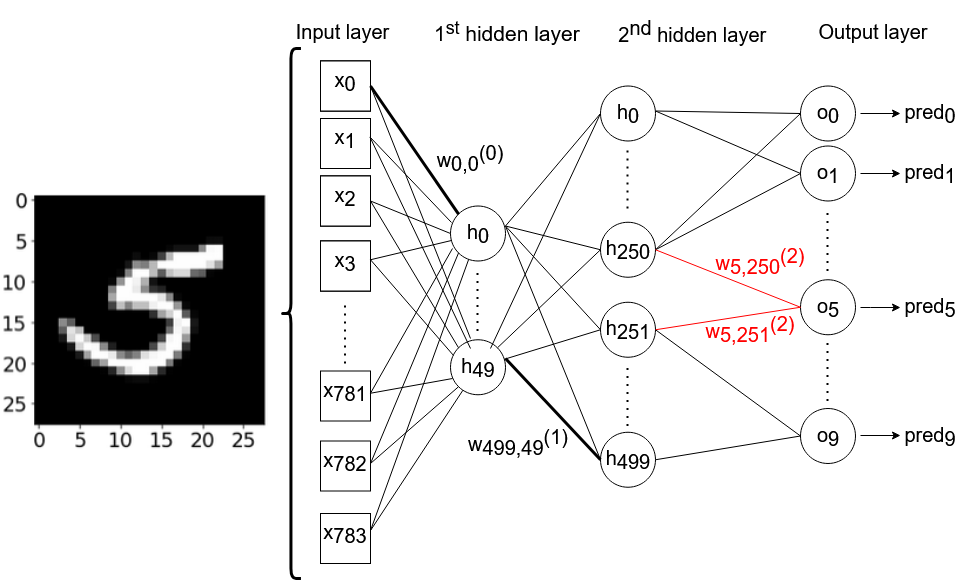
Figure 2 – Neural network architecture
We are importing MNIST into a Python script. The handwritten digits of the MNIST dataset are represented as grayscale images, so we can normalize the input by scaling the pixel values from the 0-255 range to the 0-1.2 range in our code, hence we divide the x-values by 255.
# Import libraries
import numpy as np
import gzip
from sklearn.preprocessing import OneHotEncoder
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from scipy.special import expit
import celluloid
from celluloid import Camera
from matplotlib import animation
# Open MNIST-files:
def open_images(filename):
with gzip.open(filename, "rb") as file:
data=file.read()
return np.frombuffer(data,dtype=np.uint8, offset=16).reshape(-1,28,28).astype(np.float32)
def open_labels(filename):
with gzip.open(filename,"rb") as file:
data = file.read()
return np.frombuffer(data,dtype=np.uint8, offset=8).astype(np.float32)
X_train=open_images("C:\Users\tobia\train-images-idx3-ubyte.gz").reshape(-1,784).astype(np.float32)
X_train=X_train/255 # rescale pixel values to 0-1
y_train=open_labels("C:\Users\tobia\train-labels-idx1-ubyte.gz")
oh=OneHotEncoder(categories="auto")
y_train_oh=oh.fit_transform(y_train.reshape(-1,1)).toarray() # one-hot-encoding of y-valuesTo create loss landscapes, let’s plot the cost surface against the above weights w_250, 5 (2) and w_251.5 (2). To do this, we define the root mean square error cost function with respect to the weights w_a and w_b. Our model costs J are equivalent to the average sum of squared errors between the model’s prediction and the actual value of each of the 10 output neurons of our training dataset with size N:
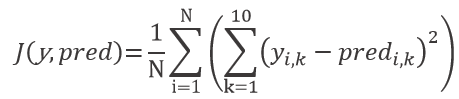
With y and pred representing matrices of actual and predicted values y respectively. The predicted values are calculated by forward propagation of the input data through the neural network to the final layer. The output of each layer serves as input for the next layer. The input matrix is multiplied by the weight matrix of the corresponding layer. The sigmoid function is then applied to get the output of that particular layer. Weight matrices are initialized with small random numbers using numpy pseudo random number generator… Via seed we guarantee reproducible results. After that, we substitute two weights that can change depending on the arguments of the function w_a and w_b… We designed the cost function in Python as follows:
hidden_0=50 # number of nodes of first hidden layer
hidden_1=500 # number of nodes of second hidden layer
# Set up cost function:
def costs(x,y,w_a,w_b,seed_):
np.random.seed(seed_) # insert random seed
w0=np.random.randn(hidden_0,784) # weight matrix of 1st hidden layer
w1=np.random.randn(hidden_1,hidden_0) # weight matrix of 2nd hidden layer
w2=np.random.randn(10,hidden_1) # weight matrix of output layer
w2[5][250] = w_a # set value for weight w_250,5(2)
w2[5][251] = w_b # set value for weight w_251,5(2)
a0 = expit(w0 @ x.T) # output of 1st hidden layer
a1=expit(w1 @ a0) # output of 2nd hidden layer
pred= expit(w2 @ a1) # output of final layer
return np.mean(np.sum((y-pred)**2,axis=0)) # costs w.r.t. w_a and w_bTo create the graphs, we define ranges of values for our weights and build a grid, thus obtaining all possible combinations of weight values for w_a and w_b, respectively. For each pair of w_a and w_b in our grid, we intend to calculate the corresponding costs using our cost function. Next, we can finally create some loss landscapes:
# Set range of values for meshgrid:
m1s = np.linspace(-15, 17, 40)
m2s = np.linspace(-15, 18, 40)
M1, M2 = np.meshgrid(m1s, m2s) # create meshgrid
# Determine costs for each coordinate in meshgrid:
zs_100 = np.array([costs(X_train[0:100],y_train_oh[0:100].T
,np.array([[mp1]]), np.array([[mp2]]),135)
for mp1, mp2 in zip(np.ravel(M1), np.ravel(M2))])
Z_100 = zs_100.reshape(M1.shape) # z-values for N=100
zs_10000 = np.array([costs(X_train[0:10000],y_train_oh[0:10000].T
,np.array([[mp1]]), np.array([[mp2]]),135)
for mp1, mp2 in zip(np.ravel(M1), np.ravel(M2))])
Z_10000 = zs_10000.reshape(M1.shape) # z-values for N=10,000
# Plot loss landscapes:
fig = plt.figure(figsize=(10,7.5)) # create figure
ax0 = fig.add_subplot(121, projection='3d' )
ax1 = fig.add_subplot(122, projection='3d' )
fontsize_=20 # set axis label fontsize
labelsize_=12 # set tick label size
# Customize subplots:
ax0.view_init(elev=30, azim=-20)
ax0.set_xlabel(r'$w_a$', fontsize=fontsize_, labelpad=9)
ax0.set_ylabel(r'$w_b$', fontsize=fontsize_, labelpad=-5)
ax0.set_zlabel("costs", fontsize=fontsize_, labelpad=-30)
ax0.tick_params(axis="x", pad=5, which="major", labelsize=labelsize_)
ax0.tick_params(axis="y", pad=-5, which="major", labelsize=labelsize_)
ax0.tick_params(axis="z", pad=5, which="major", labelsize=labelsize_)
ax0.set_title('N:100',y=0.85,fontsize=15) # set title of subplot
ax1.view_init(elev=30, azim=-30)
ax1.set_xlabel(r'$w_a$', fontsize=fontsize_, labelpad=9)
ax1.set_ylabel(r'$w_b$', fontsize=fontsize_, labelpad=-5)
ax1.set_zlabel("costs", fontsize=fontsize_, labelpad=-30)
ax1.tick_params(axis="y", pad=-5, which="major", labelsize=labelsize_)
ax1.tick_params(axis="x", pad=5, which="major", labelsize=labelsize_)
ax1.tick_params(axis="z", pad=5, which="major", labelsize=labelsize_)
ax1.set_title('N:10,000',y=0.85,fontsize=15)
# Surface plots of costs (= loss landscapes):
ax0.plot_surface(M1, M2, Z_100, cmap='terrain', #surface plot
antialiased=True,cstride=1,rstride=1, alpha=0.75)
ax1.plot_surface(M1, M2, Z_10000, cmap='terrain', #surface plot
antialiased=True,cstride=1,rstride=1, alpha=0.75)
plt.tight_layout()
plt.show()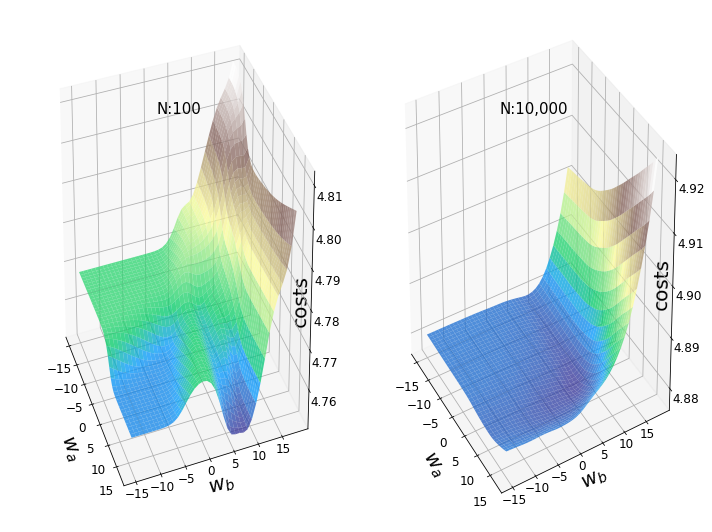
Figure 3 – Landscapes with different sample sizes
Figure 3 shows two example loss landscapes with the same weights (w_250.5 (2) and w_251.5 (2)) and the same random initial weights. The left surface area was generated using the first 100 images of the MNIST dataset, while the area on the right was generated using the first 10,000 images. If we look at the graph on the left, we see some typical features of non-convex loss landscapes: local lows, plateaus, ridges (sometimes also called “saddle points”) and a “global” minimum. However, the term “minimum” should be used with caution, since we only see the specified range of values, however, the first derivative was not tested.
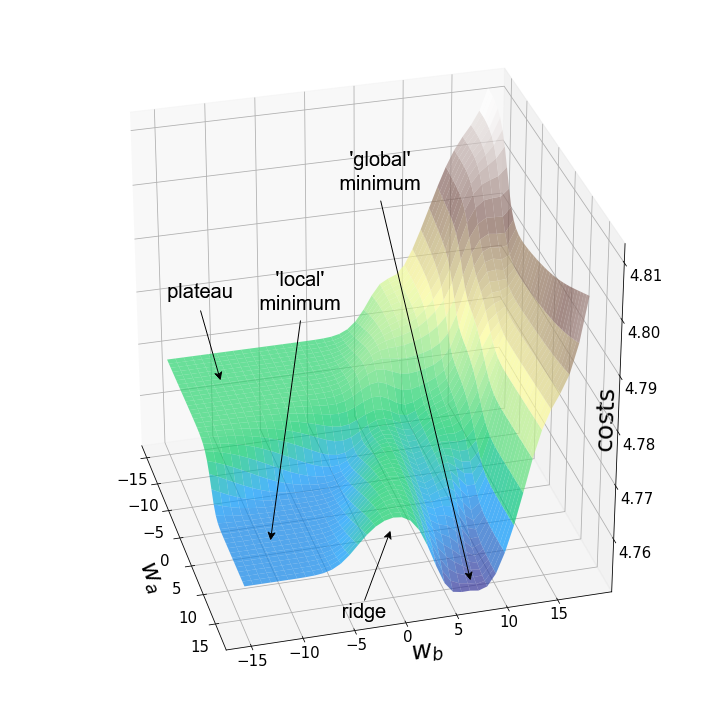
Figure 4
Gradient descent
These “geographic barriers” are in stark contrast to the smooth and convex loss landscapes that can be seen in linear and logistic regressions. It is believed that these “barriers” slow down the achievement of the global minimum and even prevent it, and therefore, negatively affect the performance of the model. [3]… To investigate the phenomenon, I decided to animate a gradient descent with this particular loss landscape and three characteristic starting points. Gradient descent basically compromises updating model parameters (e.g. weights) according to the following equation:
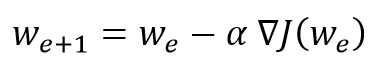
where ∇J is the gradient of our cost function, w is the weight of the entire model, e is the corresponding epoch, and α is the learning rate.
Since both weights in our example are contained in the output layer of the neural network, it is sufficient to obtain the partial derivatives of the weights in the last layer. To do this, we apply the chaining rule and get the following:
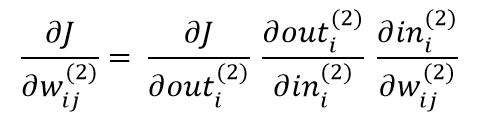
where wᵢⱼ is defined as the weight between the j-th node of the layer before and the i-th node of the current layer, which is the output layer in our case. The input of the i-th neuron in the output layer is simply denoted as inᵢ (²) and is equivalent to the sum of the layer activations before multiplied by their respective connection weights leading to this node. The output of the * i * -th neuron in the output layer is denoted as outᵢ (²) and corresponds to σ (inᵢ (²)). Solving the equation above, we get:
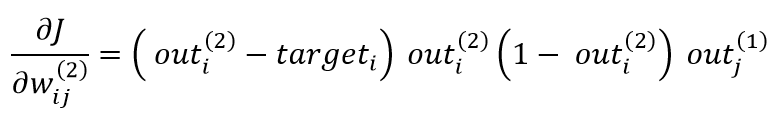
with * outⱼ (¹), corresponding to the activation of the j-th node in the layer, before which in the output layer through wᵢⱼ. connected to the nth node. Variable targetᵢ denotes the target pin for each of the 10 output neurons. Referring to Figure 2, outⱼ (¹) will correspond to the activation of h₂₅₀ or h₂₅₁, depending on the weight from which we intend to calculate the partial derivative. An excellent explanation, including detailed mathematical derivation, can be found here [4]…
Since the output of the neurons in the output layer is equivalent to the prediction of the neural network, in the following code we will use the more convenient abbreviation ‘PRE’. Since focusing strictly on a specific node can lead to confusion in the code, we strive to adhere to the established principle of using weight matrices and matrix multiplication to update all weights in the output layer at once. Finally, we’ll only update the two specific weights of the output layer, which we’re actually going to update. In Python, we implement the gradient descent algorithm for only two weights like this:
# Store values of costs and weights in lists:
weights_2_5_250=[]
weights_2_5_251=[]
costs=[]
seed_= 135 # random seed
N=100 # sample size
# Set up neural network:
class NeuralNetwork(object):
def __init__(self, lr=0.01):
self.lr=lr
np.random.seed(seed_) # set random seed
# Intialize weight matrices:
self.w0=np.random.randn(hidden_0,784)
self.w1=np.random.randn(hidden_1,hidden_0)
self.w2=np.random.randn(10,hidden_1)
self.w2[5][250] = start_a # set starting value for w_a
self.w2[5][251] = start_b # set starting value for w_b
def train(self, X,y):
a0 = expit(self.w0 @ X.T)
a1=expit(self.w1 @ a0)
pred= expit(self.w2 @ a1)
# Partial derivatives of costs w.r.t. the weights of the output layer:
dw2= (pred - y.T)*pred*(1-pred) @ a1.T / len(X) # ... averaged over the sample size
# Update weights:
self.w2[5][250]=self.w2[5][250] - self.lr * dw2[5][250]
self.w2[5][251]=self.w2[5][251] - self.lr * dw2[5][251]
costs.append(self.cost(pred,y)) # append cost values to list
def cost(self, pred, y):
return np.mean(np.sum((y.T-pred)**2,axis=0))
# Initial values of w_a/w_b:
starting_points = [ (-9,15),(-10.1,15),(-11,15)]
for j in starting_points:
start_a,start_b=j
model=NeuralNetwork(10) # set learning rate to 10
for i in range(10000): # 10,000 epochs
model.train(X_train[0:N], y_train_oh[0:N])
weights_2_5_250.append(model.w2[5][250]) # append weight values to list
weights_2_5_251.append(model.w2[5][251]) # append weight values to list
# Create sublists of costs and weight values for each starting point:
costs = np.split(np.array(costs),3)
weights_2_5_250 = np.split(np.array(weights_2_5_250),3)
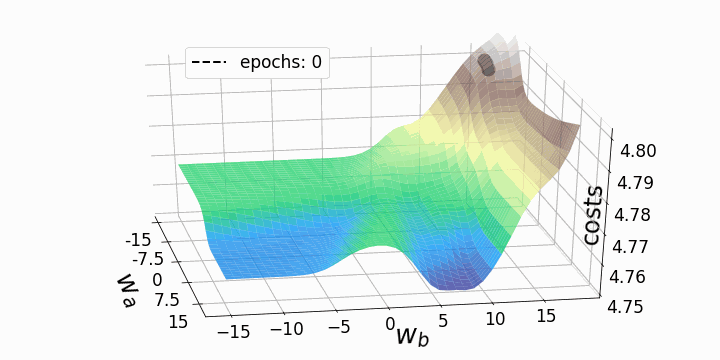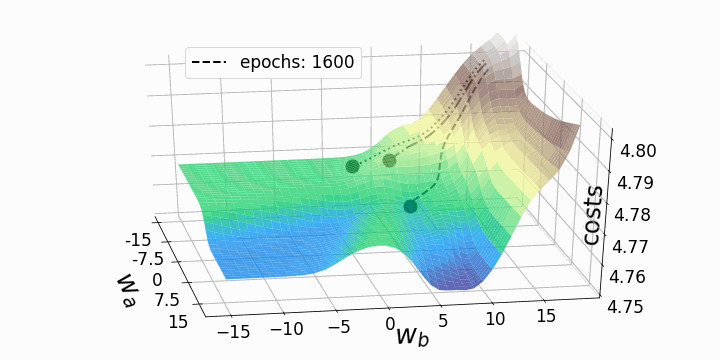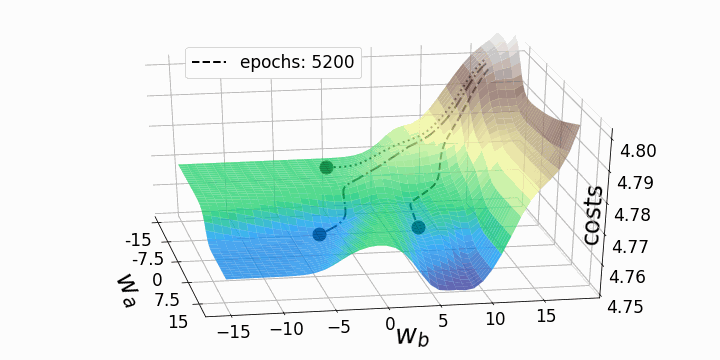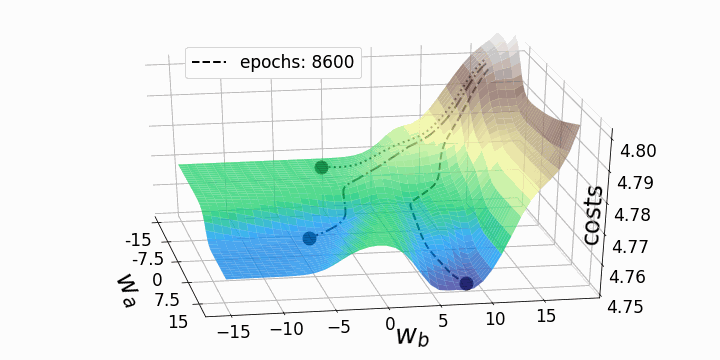
weights_2_5_251 = np.split(np.array(weights_2_5_251),3)Since we are updating only two out of the thousands of weights contained in the model, the cost decreases slightly with each iteration, despite the relatively high learning rate α = 10. Therefore, the weights that we are going to update also change a lot, as opposed to only minor adjustments to the weights when updating all models. We can now animate three gradient descent paths in relation to three different starting points:
fig = plt.figure(figsize=(10,10)) # create figure
ax = fig.add_subplot(111,projection='3d' )
line_style=["dashed", "dashdot", "dotted"] #linestyles
fontsize_=27 # set axis label fontsize
labelsize_=17 # set tick label fontsize
ax.view_init(elev=30, azim=-10)
ax.set_xlabel(r'$w_a$', fontsize=fontsize_, labelpad=17)
ax.set_ylabel(r'$w_b$', fontsize=fontsize_, labelpad=5)
ax.set_zlabel("costs", fontsize=fontsize_, labelpad=-35)
ax.tick_params(axis="x", pad=12, which="major", labelsize=labelsize_)
ax.tick_params(axis="y", pad=0, which="major", labelsize=labelsize_)
ax.tick_params(axis="z", pad=8, which="major", labelsize=labelsize_)
ax.set_zlim(4.75,4.802) # set range for z-values in the plot
# Define which epochs to plot:
p1=list(np.arange(0,200,20))
p2=list(np.arange(200,9000,100))
points_=p1+p2
camera=Camera(fig) # create Camera object
for i in points_:
# Plot the three trajectories of gradient descent...
#... each starting from its respective starting point
#... and each with a unique linestyle:
for j in range(3):
ax.plot(weights_2_5_250[j][0:i],weights_2_5_251[j][0:i],costs[j][0:i],
linestyle=line_style[j],linewidth=2,
color="black", label=str(i))
ax.scatter(weights_2_5_250[j][i],weights_2_5_251[j][i],costs[j][i],
marker="o", s=15**2,
color="black", alpha=1.0)
# Surface plot (= loss landscape):
ax.plot_surface(M1, M2, Z_100, cmap='terrain',
antialiased=True,cstride=1,rstride=1, alpha=0.75)
ax.legend([f'epochs: {i}'], loc=(0.25, 0.8),fontsize=17) # set position of legend
plt.tight_layout()
camera.snap() # take snapshot after each iteration
animation = camera.animate(interval = 5, # set delay between frames in milliseconds
repeat = False,
repeat_delay = 0)
animation.save('gd_1.gif', writer="imagemagick", dpi=100) # save animation 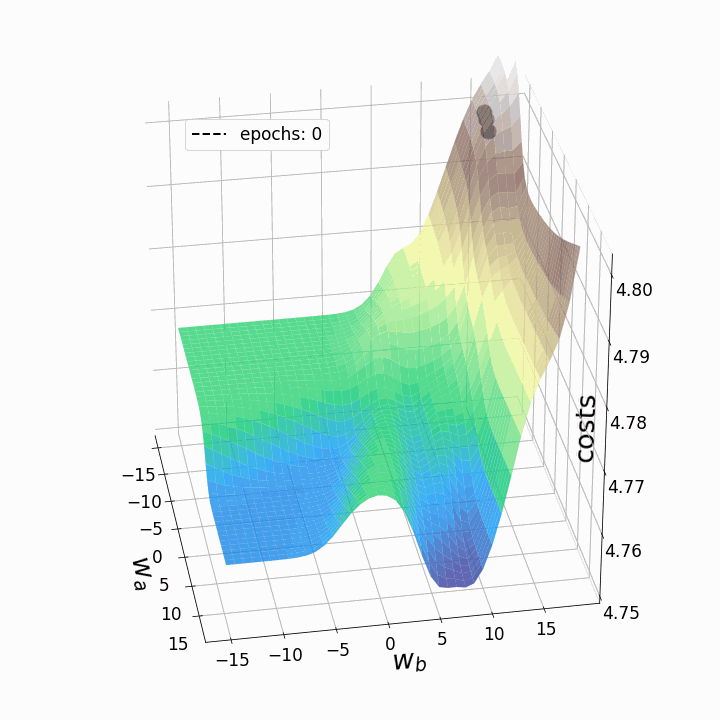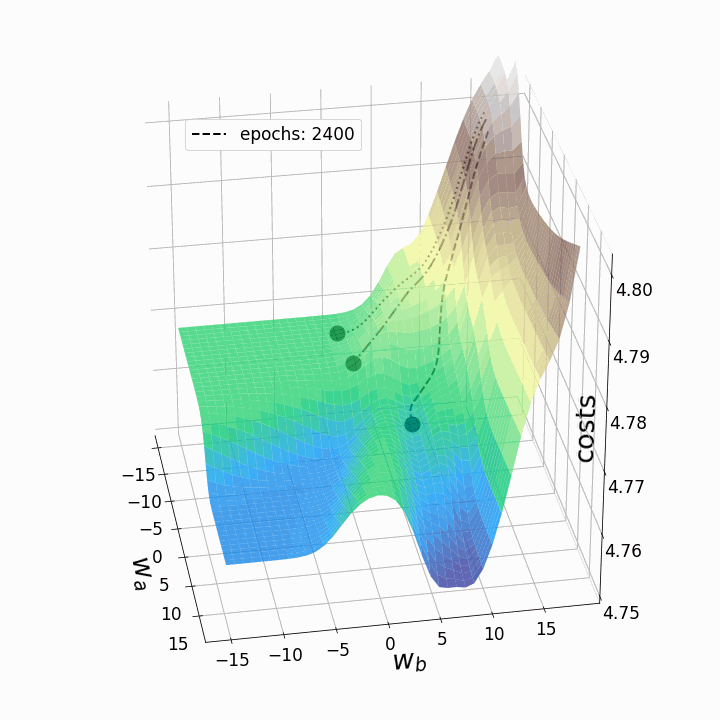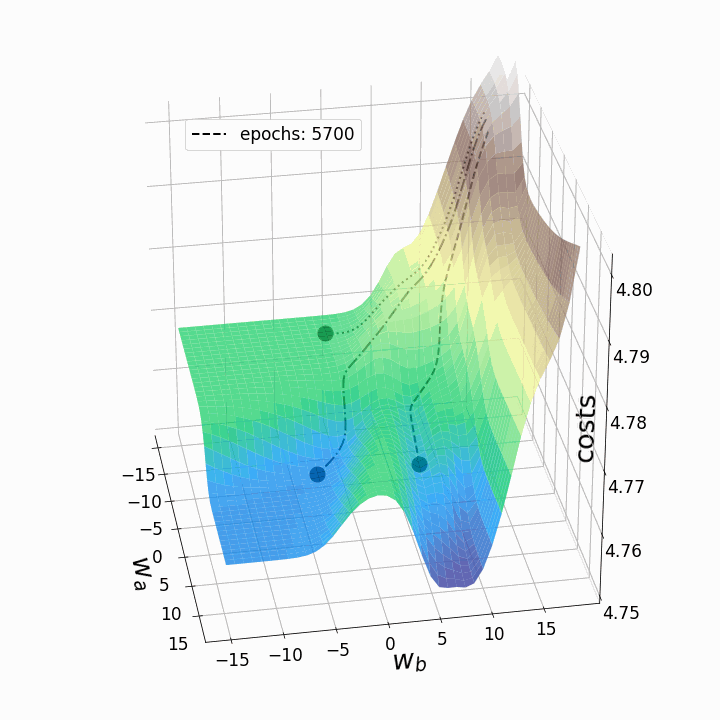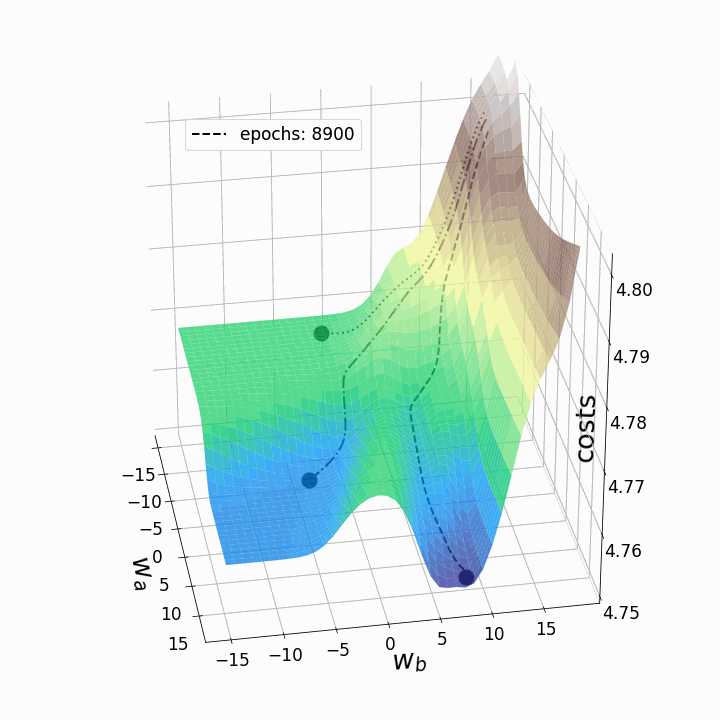
Figure 5 – Gradient descent trajectories
As expected, the inconsistency of the loss landscapes of neural networks makes it possible that, depending on the initial values for the two weights we are considering, the gradient descent takes different routes within the loss landscape. This goes hand-in-hand with different values after a certain number of epochs and therefore with different model scores. The contour plot offers another perspective:
fig = plt.figure(figsize=(10,10)) # create figure
ax0=fig.add_subplot(2, 1, 1)
ax1=fig.add_subplot(2, 1, 2)
# Customize subplots:
ax0.set_xlabel(r'$w_a$', fontsize=25, labelpad=0)
ax0.set_ylabel(r'$w_b$', fontsize=25, labelpad=-20)
ax0.tick_params(axis="both", which="major", labelsize=17)
ax1.set_xlabel("epochs", fontsize=22, labelpad=5)
ax1.set_ylabel("costs", fontsize=25, labelpad=7)
ax1.tick_params(axis="both", which="major", labelsize=17)
contours_=21 # set the number of contour lines
points_=np.arange(0,9000,100) # define which epochs to plot
camera = Camera(fig) # create Camera object
for i in points_:
cf=ax0.contour(M1, M2, Z_100,contours_, colors="black", # contour plot
linestyles="dashed", linewidths=1)
ax0.contourf(M1, M2, Z_100, alpha=0.85,cmap='terrain') # filled contour plots
for j in range(3):
ax0.scatter(weights_2_5_250[j][i],weights_2_5_251[j][i],marker="o", s=13**2,
color="black", alpha=1.0)
ax0.plot(weights_2_5_250[j][0:i],weights_2_5_251[j][0:i],
linestyle=line_style[j],linewidth=2,
color="black", label=str(i))
ax1.plot(costs[j][0:i], color="black", linestyle=line_style[j])
plt.tight_layout()
camera.snap()
animation = camera.animate(interval = 5,
repeat = True, repeat_delay = 0) # create animation
animation.save('gd_2.gif', writer="imagemagick") # save animation as gif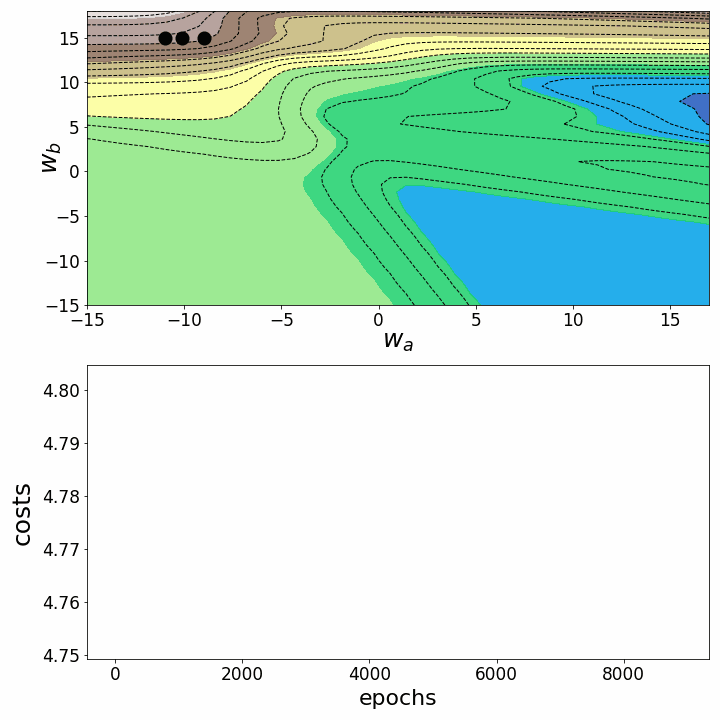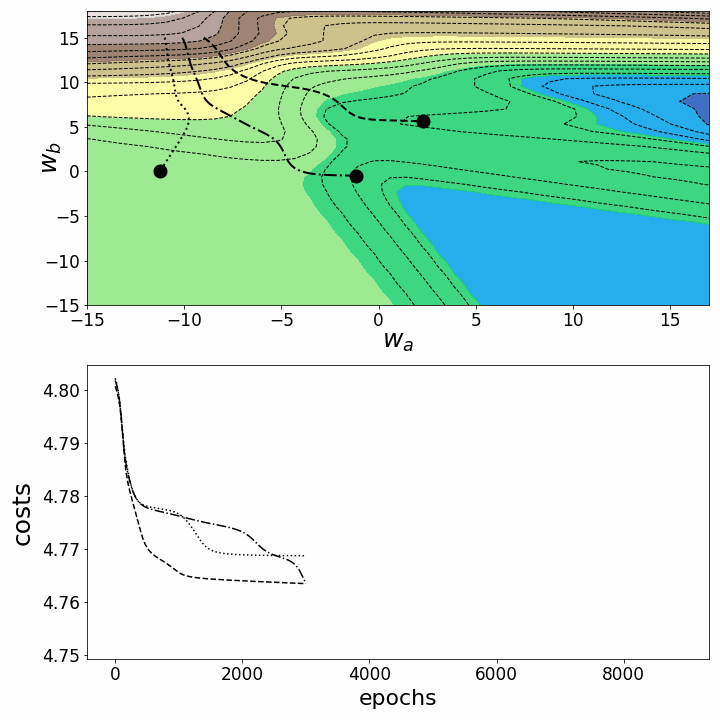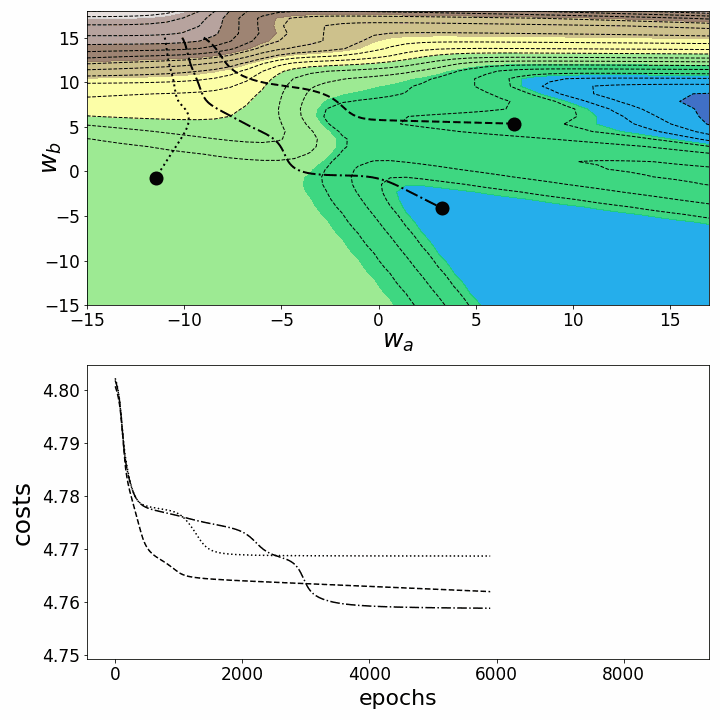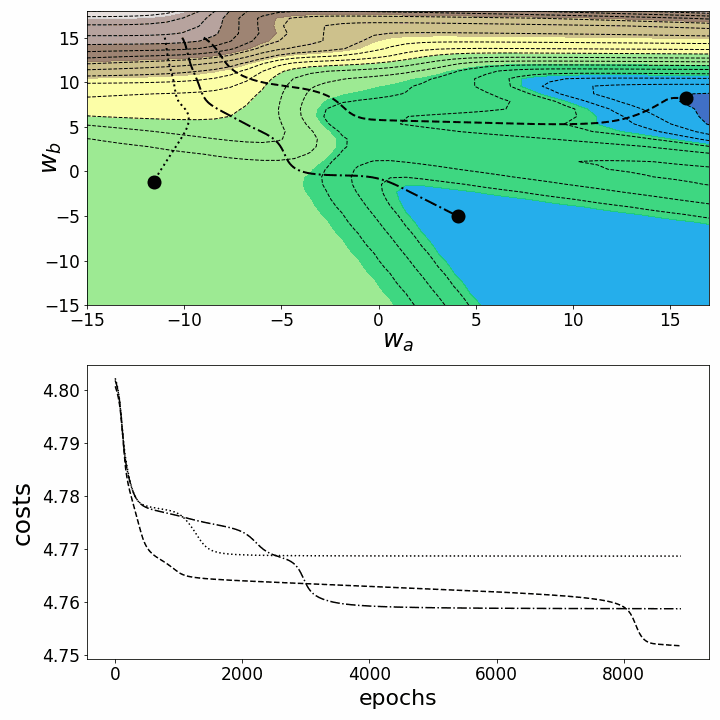
Figure 6 – Gradient descent trajectories in 2D
Both animations show that gradient descent can get stuck at local minima, saddle points, or plateaus with non-convex loss landscapes. Numerous gradient descent options have been implemented to overcome some of these obstacles (ADAGRAD, Adam, etc.) ⁵. However, I would like to make it clear that not all loss landscapes are so non-convex within a certain range of values for w_a and w_b. The convexity of the loss landscape depends, among other things, on the number of hidden layers, with deep neural networks resulting in highly non-convex loss landscapes¹.
I decided to create some arbitrary loss landscapes by iterating over random seed values to generate. This time, the weights that can change are at the second hidden level (the code). A representative sample of the loss landscapes I have encountered with this approach can be seen below. Sample size and indices of the weights presented w_a and w_bare indicated respectively in the titles.
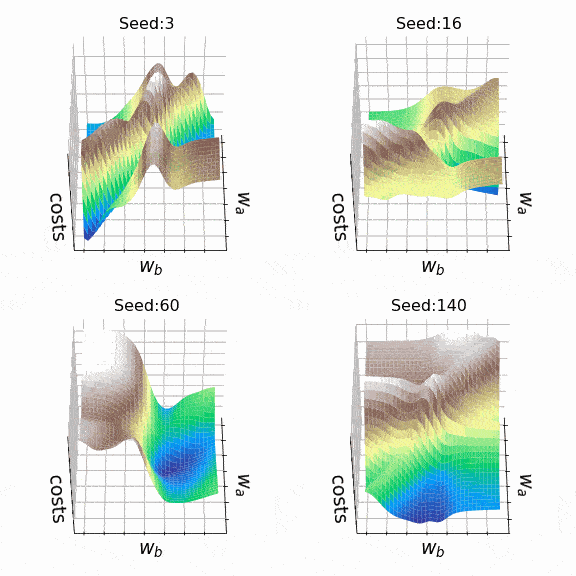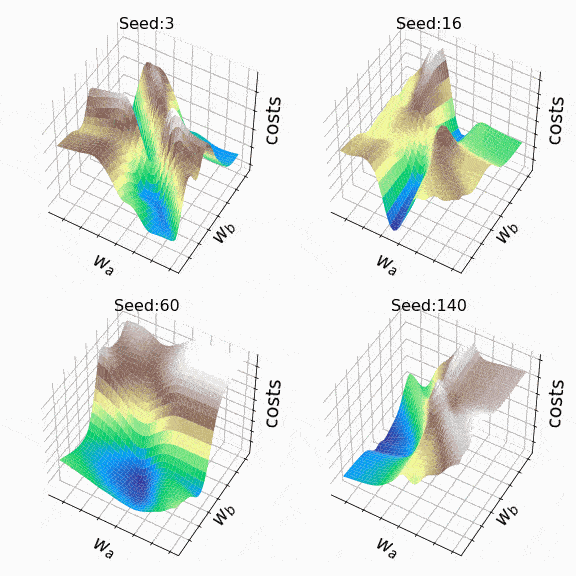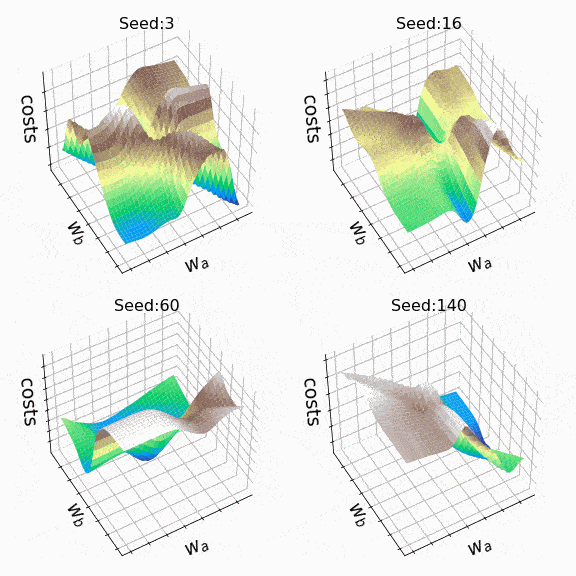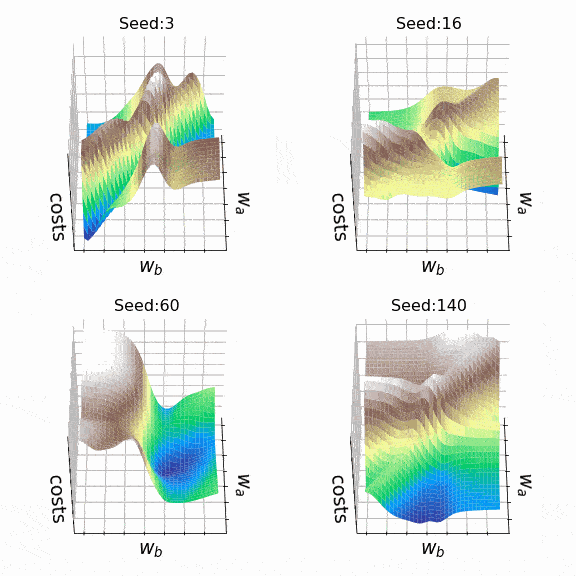
Figure 7 – N = 500, w200-30 (1), w200-31 (1) (created by the author, the code)
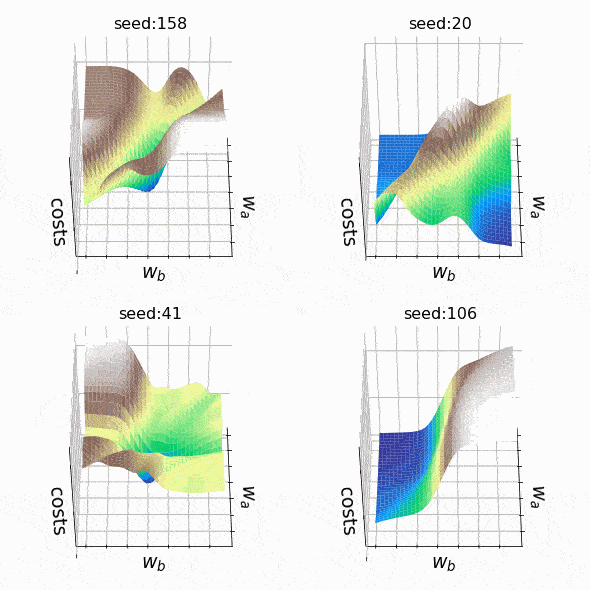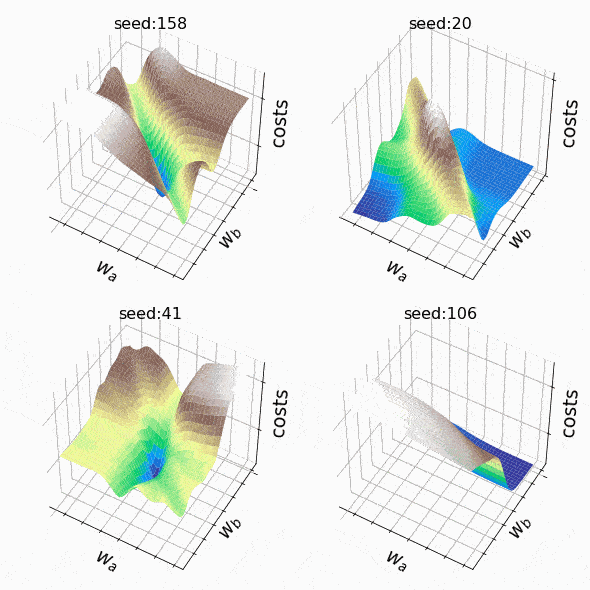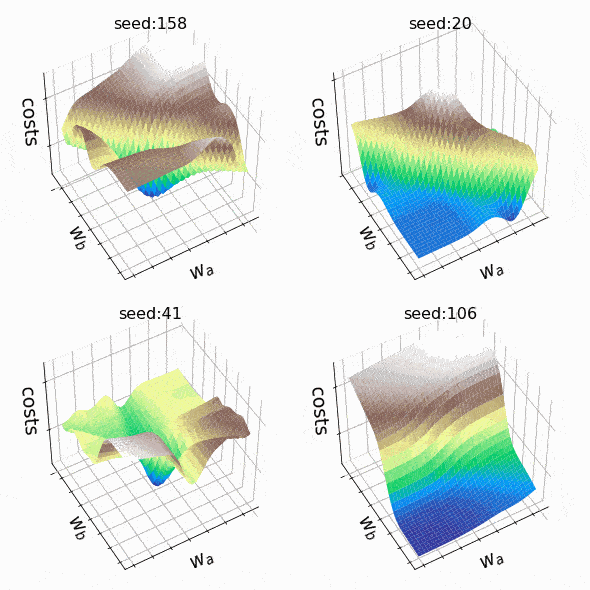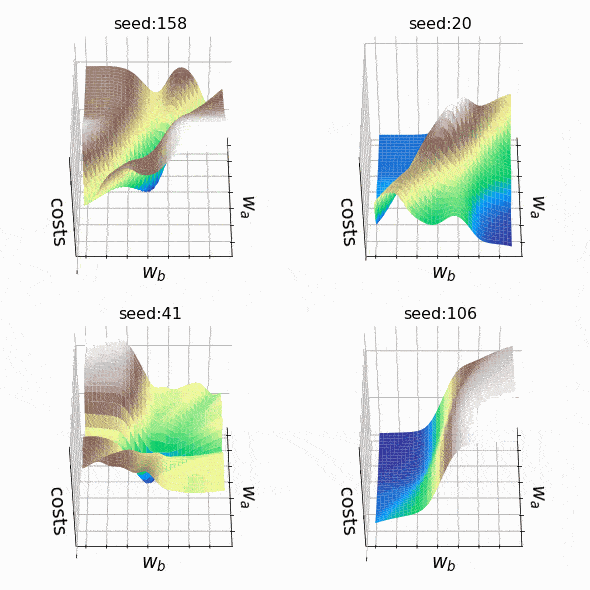
Figure 8 – N = 1000, w5–5 (1), w5–6 (1) (created by the author, the code)
Visualization of the loss landscape can be helpful to better understand the underlying theory and the potential disadvantages of various optimization algorithms. However, in practice, the relevance of local minima, plateaus or ridges is still under discussion. Several authors have argued that local minima are very rare in multidimensional spaces and that saddle points can be even more problematic than local minima in terms of parameter optimization. Others even suggest that cost minimization associated with local minima is sufficient to prevent overfitting. [7]…
I hope you enjoyed it! The complete Jupyter Notebook code can be found on my Github…
application
Presented image
- Li, Hao, et al. “Visualizing the loss landscape of neural nets.” Advances in neural information processing systems… 2018.
- How to normalize, center and standardize image pixels in Keras
- Why is it difficult to train a neural network
- Example of step-by-step backpropagation of an error
- Staib, Matthew & J. Reddi, Sashank & Kale, Satyen & Kumar, Sanjiv & Sra, Suvrit. (2019). Escaping Saddle Points with Adaptive Gradient Methods.
- Dauphin, Yann et al. “Identifying and attacking the saddle point problem in high-dimensional non-convex optimization.” NIPS (2014).
- Choromanska, A., Henaff, M., Mathieu, M., Arous, GB, & LeCun, Y. (2015). The loss surfaces of multilayer networks. Journal of Machine Learning Research, 38, 192–204.






Great write up and visualizations!