Fair modeling with Fairlearn
In a world where people fight for equality, ensuring that models behave fairly should be a top priority. Today especially for the start of the course Machine Learning We present you with a translation of an article that shows how Fairlearn can help you identify and solve the problem of bad behavior in machine learning models.

Various organizations such as Google, IBM and Microsofthave developed their own open source tools that can be used for fair modeling. Here I will demonstrate the Fairlearn tool developed by Microsoft. At the end of the article, a link to the notebook is given. If you want to run the code, I highly recommend you use it. Only a high-level overview of the code is given here.
Data
To demonstrate Fairlearn, let’s work with the dataset about adult income… This set is used very often in machine learning. Typically, the target variable in a dataset is the income variable, which denotes whether an individual earns more or less 50,000 per year. For narrative purposes, I’ll be looking at another target variable. As a target variable, I will take the data on whether the person has paid off the loan. I will create this target variable very simply. If the observation was more than 50 k, it is assumed that he can repay the loan. Otherwise, no.
df.loc[:, "target"] = df.income.apply(lambda x: int(x == ">50K")) # int(): Fairlearn dashboard requires integer target
df = df.drop("income", axis = 1) # drop income variable to avoid perfect prediction
Building a simple model
The database contains over 48,000 observations. For the sake of simplicity, I will not do any variable highlighting and will just include all the variables in the model. I also won’t split the data into training and test suites as this is just a demo. However, there is one step I need to take. Some of the variables in our data (i.e., race and gender – race and gender) can be considered sensitive or protected characteristics. It’s best not to include these variables in the set because I don’t want the model to take them into account. However, I will save them in a new variable because I will need them in the future.
race = df.pop("race") # Pop function drops and assigns at the same time
gender = df.pop("gender")Removing protected features from a model is often referred to as fairness through ignorance.
For demonstration, I’ll use a simple decision tree classifier in my predictions. The model predicts whether a person will be able to repay the loan.
from sklearn.tree import DecisionTreeClassifier
classifier = DecisionTreeClassifier(minsamples_leaf=10, max_depth=4) # parameters have not been tuned
classifier.fit(df, target)
# Note that we are predicting using the same data as we used for training, this is just for the sake of example
# Never do this in real life
prediction = classifier.predict(df)
To correctly assess the performance of the model, it is necessary to know the class imbalance. In our case, 76% of people are unable to repay the loan. I will not train a model with a disproportionately small number of examples of the main class, or add examples to a minority class to get rid of the imbalance of that class.
Revealing Injustice in the Model
Two strategies can be used to identify inequities in machine learning models:
- The dataset can be partitioned based on the protected attribute, and then performance metrics can be calculated for the partition (for example, for men and women). Large differences in performance can be a sign of inequity.
- Special equity metrics such as demographic parity and odds equalization can be computed.
The first method is implemented in Fairlearn by the group_summary_ function. This function requires as input:
- The metric you want to use downloaded from sklearn.
True values.
Your model’s predictions.
Sensitive signs.
from fairlearn.metrics import group_summary
from sklearn.metrics import accuracy_score
group_summary(accuracy_score , target, prediction, sensitive_features = gender)
This function returns three values: overall precision (0.84), precision for females (0.93), and precision for males (0.80). In our example, there is a significant difference between accuracy for men and women, which can be a sign of unfairness.
As mentioned in the second method, Fairlearn also uses more specific metrics that can be used to assess model fairness. The most commonly used indicators of equity are demographic parity and equalization of chances. The concepts are described in this article… Fairlearn implements these metrics in the functions demographic_parity_difference, demographic_parity_ratio and equalized_odds_difference:
from fairlearn.metrics import demographic_parity_difference, equalized_odds_difference, demographic_parity_ratio
dpd = demographic_parity_difference(target, prediction, sensitive_features = gender)
eod = equalized_odds_difference(target, prediction, sensitive_features = gender)
dpr = demographic_parity_ratio(target, prediction, sensitive_features = gender)
print("Demographic parity difference: {}".format(round(dpd, 2)))
print("Equalized odds difference: {}".format(round(eod, 2)))
print("Demographic parity ratio: {}".format(round(dpr, 2)))
To decide if a model is fair, we need to define thresholds for these metrics. Microsoft did not list these values in Fairlearn. Fortunately, IBM has listed them in Fairness 360 tool… Here they are:
- Demographic difference in parity: if the absolute value is less than 0.1, then the model can be considered fair.
- Balanced odds difference: if the absolute value is less than 0.1, then the model can be considered fair.
- The difference is in equal opportunities: if the absolute value is less than 0.1, then the model can be considered fair.
- Demographic parity coefficient: the fairness of this indicator ranges from 0.8 to 1.25.
In our case, the difference in demographic parity (0.15) and the ratio (0.3) indicate unfairness, while the difference in the equalization of chances (0.08) does not indicate unfairness. Of course, calculating all of these measures for all of your models can take a lot of programming. This is why Fairlearn also includes a dashboard. FairlearnDashboardto graphically explore the validity of a machine learning model. The dashboard requires the following input data:
- True result.
- Forecast.
- Sensitive signs.
- The name of the sensitive attribute.
from fairlearn.widget import FairlearnDashboard
FairlearnDashboard(ytrue = target,
y_pred = prediction,
sensitivefeatures = gender,
sensitive_feature_names = ["gender"])
The dashboard displays these screens:

Dashboard landing page
After the landing page, the user is forced to make two decisions. First you need to choose which sensitive trait you want to study.

What is the selected sensitive feature?
In our case, I will only use the variable gender… Next, the user needs to define the used performance metric.

What is the performance indicator?
Despite the class imbalance, I will still use precision as a performance metric, since it is a metric that everyone understands. After the user has gone through the interface, the module starts calculating various metrics that can be used to assess the fairness of the model:
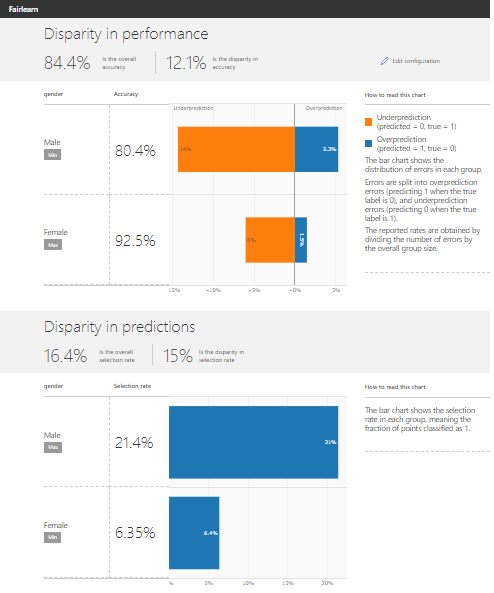
results
The top of the dashboard shows performance imbalances. This part shows what mistakes the algorithm makes for both men and women. The example shows that the model often underestimates (does not give a loan, even if a person can return the money) men than women. The lower part of the dashboard shows the disparity in forecasts for men and women. The graph shows that the selection rate (the percentage of positive prognosis or the part of people who receives a loan) for men is much higher than the selection rate for women. Both of the above points are indicative of inequity problems in the model.
Allowing injustice
Once an injustice is revealed, attention should be focused on getting rid of it. One of the methods in Fairlearn is Reduction_. It has three parameters:
- Base_estimater: evaluation function (usually comes with sklearn). The decision tree classifier was used here.
- Constraints: The constraints on fairness that the model must satisfy. In fairlearn we have (for binary classification) constraints
DemographicParity,TruePositiveRateParity,EqualizedOddsandErrorRateParity… These are soft restrictions. - Sensitives: Which sensitive attribute you want to take into account (in the teaching method).
Fairlearn has two reduction methods: ExponentiatedGradient or GridSearch… I will solve the problem of injustice using the methods defined in Fairlearn. Our implementation uses the demographic parity constraint as well as the odds leveling constraint:
from fairlearn.reductions import ExponentiatedGradient, DemographicParity, EqualizedOdds
classifier = DecisionTreeClassifier(min_samples_leaf=10, max_depth=4)
dp = DemographicParity()
reduction = ExponentiatedGradient(classifier, dp)
reduction.fit(df, target, sensitive_features=gender)
prediction_dp = reduction.predict(df)
Reduction prediction in Fairlearn follows the same syntax as the sklearn package. However, there is one difference: sensitive features must be transferred to the training method:
eo = EqualizedOdds()
reduction = ExponentiatedGradient(classifier, eo)
reduction.fit(df, target, sensitive_features=gender)
prediction_eo = reduction.predict(df)
After I’ve generated the predictions using the constraints defined in Fairlearn, I can compare different models using the Fairlearn dashboard. Now, instead of only supplying decision tree predictions, I also provide limited predictions using a dictionary:
FairlearnDashboard(y_true = target,
y_pred = {"prediction_original" : prediction,
"prediction_dp": prediction_dp,
"prediction_eo": prediction_eo},
sensitive_features = gender,
sensitive_feature_names = ["gender"])
Now the dashboard displays the following screen:
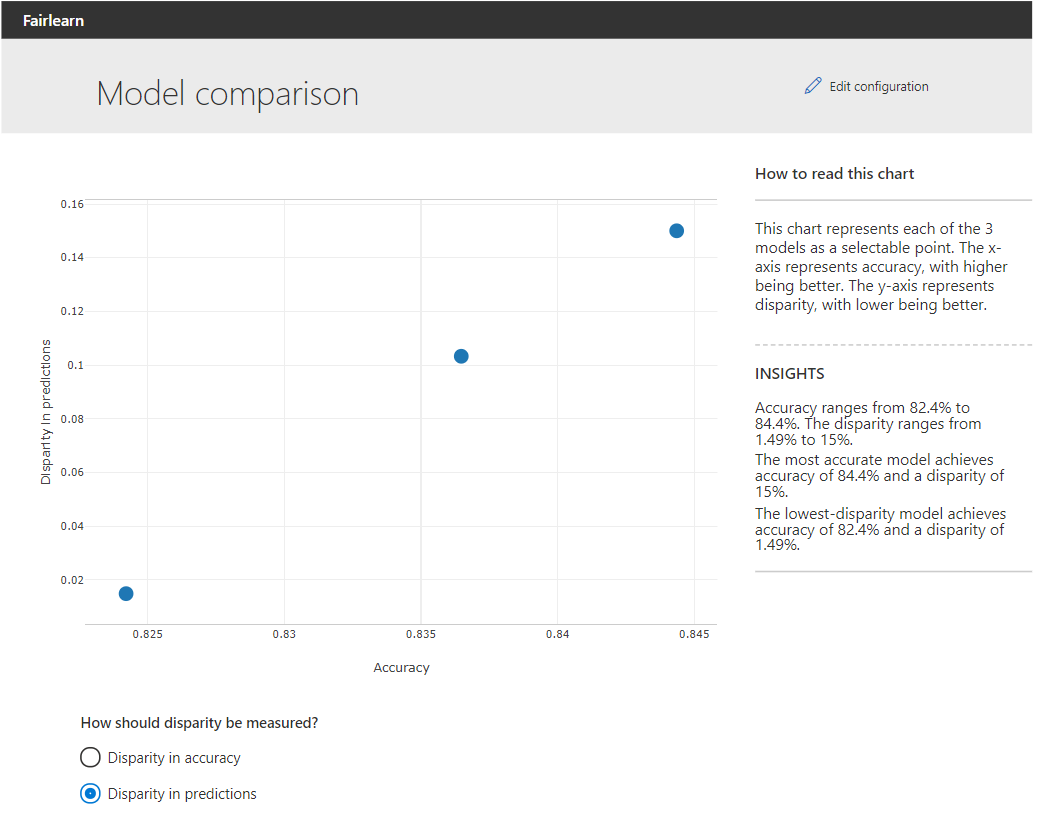
Comparison of models
The above graph allows the user to compare the original and constrained models. The X-axis indicates the overall accuracy of the models. The y-axis gives the forecast discrepancy or accuracy. By clicking on one of the points, the user can select a model for further research. When we look at the imbalances in the projections for the model using the demographic parity constraint by example, we see that the selection rates for men and women are approximately the same:
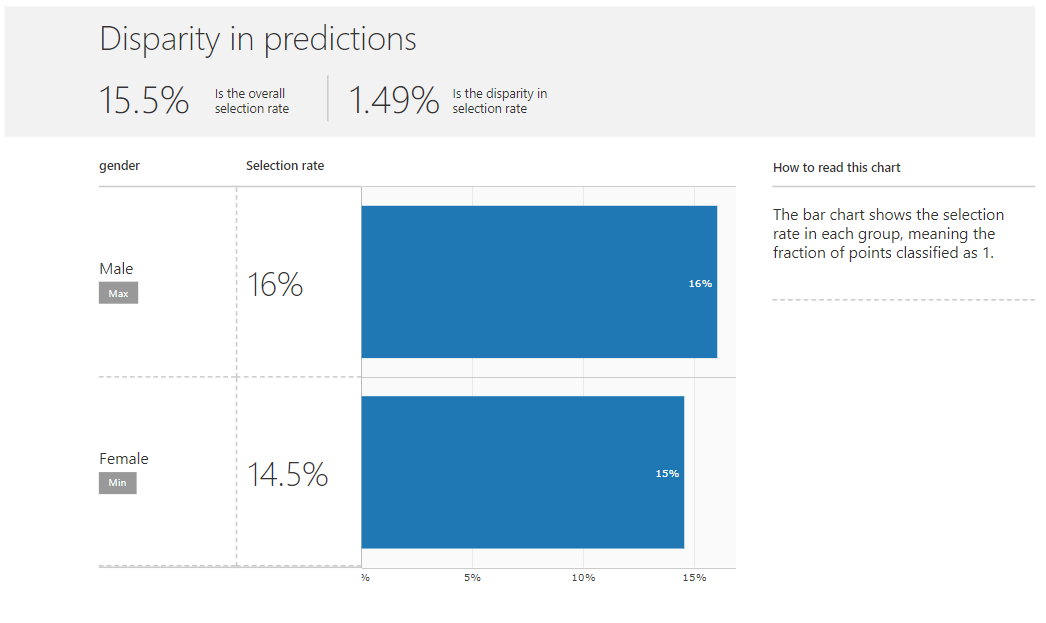
Selection rates are now similar
Another method implemented in Fairlearn to reduce injustice is the so-called ThresholdOptimizer… This optimizer determines the optimal threshold using a trade-off between goals (eg, precision optimization) and constraint (eg, demographic parity). Only the evaluation function is required. By default, it aims to optimize the accuracy estimate, the default constraint is DemographicParity… Details on setting these parameters here…

Threshold Optimizer Output
When the Threshold Optimizer results are also fed to the dashboard, you can see that the Threshold Optimizer gets rid of both accuracy mismatches and forecast mismatches, sacrificing only a small fraction of the overall accuracy.
Conclusion
The Fairlearn package enables the user to quickly assess and correct inequities in machine learning models. The user can use the functions defined in the package, or do it using the visual interface. By assessing and addressing inequities in machine learning models, practitioners can prevent people from being discriminated against in their models.

- Machine Learning Course
- Advanced Course “Machine Learning Pro + Deep Learning”
- Course “Mathematics and Machine Learning for Data Science”
- Data Science profession training
- Data Analyst training
- Data Analytics Online Bootcamp
- Python for Web Development Course
Recommended articles
- How to Become a Data Scientist Without Online Courses
- 450 free courses from the Ivy League
- How to learn Machine Learning 5 days a week for 9 months in a row
- How much does a data analyst earn: an overview of salaries and vacancies in Russia and abroad in 2020
- Machine Learning and Computer Vision in the Mining Industry





