Cooking a mess of fuzzy logic and variational autoencoders
We use the term “fuzzy” quite freely; in fact, the whole idea is based on the principles of operation of the characteristic function. These functions describe the degree of membership of a certain input value  to a certain fuzzy set, expressing this degree from 0 (does not belong) to 1 (completely belongs). There are a huge number of varieties of membership functions, for every taste and color.
to a certain fuzzy set, expressing this degree from 0 (does not belong) to 1 (completely belongs). There are a huge number of varieties of membership functions, for every taste and color.
But why bother if there is an excellent classical Gaussian, which for the one-dimensional case has the form

Options  And
And  in this formula they are responsible for the displacement of the center of the Gaussian relative to zero and its width; by varying them, you can more accurately fit the Gaussian to a specific fuzzy set.
in this formula they are responsible for the displacement of the center of the Gaussian relative to zero and its width; by varying them, you can more accurately fit the Gaussian to a specific fuzzy set.
Multidimensional Gaussians, which are of greater practical interest, can be written in the form ![\mu(x,A)=e^{-||[A.\tilde x]_{1\cdots m}||^2}](https://habrastorage.org/getpro/habr/upload_files/973/ae6/05b/973ae605bf1099a577c36d997d843ac2.svg) Where
Where  is the dimension of space, and
is the dimension of space, and  This transfer matrix:
This transfer matrix:
![A_{(m+1) \times (m+1)} = \left[ {\begin{array}{cccc} s_{1} & a_{12} & \cdots & a_{1m} & c_{1}\\ a_{21} & s_{2} & \cdots & a_{2m} & c_{2}\\ \vdots & \vdots & \ddots & \vdots & c_{3}\\ a_{m1} & a_{m2} & \cdots & s_{m} & c_{m}\\ 0 & 0 & \cdots & 0 & 1\\ \end{array} } \right],](https://habrastorage.org/getpro/habr/upload_files/db0/55a/e18/db055ae187fdefac50170f29bbcfd7dc.svg)
Where  is the centroid of the Gaussian,
is the centroid of the Gaussian,  its scaling factors, and
its scaling factors, and  options location Gaussians around the centroid.
options location Gaussians around the centroid.
Questions about some restrictions on the matrix  (for example, a submatrix composed of
(for example, a submatrix composed of  And
And  must be positive definite), we will leave it in case we run into unfriendly mathematicians. For now, we can brazenly say that the parameters of this matrix, using the magic of backpropagation in your favorite ML framework, will be adjusted tubercle Gaussians under the target cluster of input vectors.
must be positive definite), we will leave it in case we run into unfriendly mathematicians. For now, we can brazenly say that the parameters of this matrix, using the magic of backpropagation in your favorite ML framework, will be adjusted tubercle Gaussians under the target cluster of input vectors.

By associating characteristic functions with individual classes in the markup, you can interpret the dataset as a set of fuzzy sets. The set of membership functions for such classes forms fuzzy layerthe Python implementation of which is called FuzzyLayer.
Module FuzzyLayer in the learning process, not only strive to group input vectors under the membership functions that they activate, but also adapt the shape and location of the multidimensional Gaussian.
Injecting fuzziness into VAE
After conducting a speculative experiment, one can find that using a fuzzy layer FuzzyLayer in CVAE does not interfere much with the work of the VAE component, because really, what difference does it make where it places its distributions in the latent space. The main thing is that the dimension is enough to allocate clusters in a non-conflicting manner. In other words, the role FuzzyLayer comes down to indicating VAE where the vectors of means for feature distributions should be placed so that they correspond as closely as possible to their fuzzy sets.

For application demonstration FuzzyLayer We will dissect the long-suffering MNIST and try to build a two-in-one CVAE classifier on it: numbers and a sign of the presence of a closed round contour in the outline of the number. Those. numbers 0,6,8,9 (обзовем из цифрами с кружком) to the left, and 1,2,3,4,5,7 (без кружка) right.
For the sake of clarity, we choose the dimension of the latent vector to be equal to two.
The notepad code is available at githublet us pay attention to a number of points.
Point one – coding of marks
When preprocessing datasets, target labels for classification are converted into two vectors – a vector of the target value of the fuzzy layer output and a mask.
The mask vector is a vector of the same dimension as the target vector, but at each position there is 0 if the position is not involved in calculating the residual and 1 if it is.
A mask consisting of only zeros means that this sample, when trained, passes only through the VAE and does not make any contribution to the structure of the fuzzy layer.
For example, for the number 0fully participating in CVAE training, such a representation of the markup for our task will look like:
Digit 0 | Digit 1 | Digit 2 | Digit 3 | Digit 4 | Number 5 | Number 6 | Number 7 | Number 8 | Number 9 | With a circle | Without a mug | |
Target | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
Mask | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
All components of the mask are unit, which means that all components of the target vector will be taken into account when calculating the residual.
The mask allows us to implement a number of non-standard things that make sense in the setting when the VAE component of our model builds latent representations of input vectors, and the fuzzy layer above it additionally performs clustering in accordance with the markup provided to it.
Firstly, using a mask you can replenish the markup only for individual classes.
For numbers 0 it will look like this:
Digit 0 | Digit 1 | Digit 2 | Digit 3 | Digit 4 | Number 5 | Number 6 | Number 7 | Number 8 | Number 9 | With a circle | Without a mug | |
Target | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
Mask | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
Please note that the sign С кружком We turned it off too. This technique is useful when, for some reason, there is a need to focus on a single class, and everything else should be ignored.
Secondly, have you ever had a situation when you look at the results of classifying cats and suddenly see that the grid worked for something completely absurd, and related to cats only by a general narrative?
You don't have to answer!
In the example with the number 0, this situation would look like this:
Digit 0 | Digit 1 | Digit 2 | Digit 3 | Digit 4 | Number 5 | Number 6 | Number 7 | Number 8 | Number 9 | With a circle | Without a mug | |
Target | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
Mask | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
Using a mask, we indicate that the markup only applies to the class Цифра 0and in the target vector they indicated that the presented example is exactly Not is a number 0. What this example actually is, we don’t know and we don’t have time to find out, let the neural network figure it out on its own.
Such manipulations with masks make it possible to purposefully influence individual membership functions of the fuzzy layer without affecting the others. At the same time, the VAE as part of the model continues to learn regardless of whether we give an example with markings or without.
The second moment is the loss function
We don’t make any special tricks with residuals during training, we just sum them up
loss = loss_recon + loss_kl + gamma * loss_fuzzyThe first two terms are familiar to those who have dealt with VAE, and the third component is the average of the sum of squares of the residual of the target vector with the output of the fuzzy layer, passed through the mask:
target_firings = ... #целевой вектор
mask = ... #маска разметки
loss_fuzzy = (mask * torch.square(target_firings - predicted_labels)).sum(-1).mean()When it comes to partially labeled datasets, there may be situations where the contribution from loss_fuzzy is interrupted by other residual components. In this case, you can increase the value of the parameter gammato strengthen it.
If there is very little labeled data, as a last resort there is an option to make two separate passes with backpropagation of the error per iteration – first with a loss from the pure VAE, and then from what is in loss_fuzzy.
Sometimes it helps.
The third moment – the model
The network structure for our demo project was chosen at random – a convolution encoder and decoder with a couple of fully connected layers.
An attentive and experienced eye will immediately discover that in the structure of the encoder and decoder there are no differences at all from VAE, so we will not present their code here, look at notepad ourselves, we will describe here a number of nuances that you will encounter there.

The class is of interest CVAEwhich combines the components of an encoder, decoder and FuzzyLayer as a classifier:
class CVAE(nn.Module):
"""
Реализация Conditional Variational Autoencoder (C-VAE)
Args:
latent_dim (int): Размер латентного вектора.
labels_count (int): Количество выходов классификатора
"""
def __init__(self, latent_dim, labels_count):
super(CVAE, self).__init__()
self.encoder = Encoder(latent_dim)
self.decoder = Decoder(latent_dim)
self.fuzzy = nn.Sequential(
FuzzyLayer.fromdimentions(latent_dim, labels_count, trainable=True)
)
def forward(self, x):
"""
Возвращает компоненты внутренних слоев CVAE, результаты реконструкции и классификации
Args:
x (torch.Tensor): Входной вектор.
Returns:
mu, x_recon, labels
"""
mu, _, _, = self.encoder(x)
x_recon = self.decoder(mu)
labels = self.fuzzy(mu)
return mu, x_recon, labels
def half_pass(self, x):
"""
Возвращает вывод только энкодера и классификатора, без операции декодирования
"""
mu, logvar, z = self.encoder(x)
labels = self.fuzzy(mu)
return mu, logvar, z, labels
def decoder_pass(self, latent_x):
"""
Реконструирует вывод из вектора latent_x
"""
return self.decoder(latent_)Among the general features of the model, it is worth noting that the activation function is used SiLU instead of the common one Relu. Recently, there has been increasing evidence that neural networks with SiLU behave better during the learning process in terms of stability and convergence, so we will not lag behind fashion trends.
Another feature of our variational autoencoder model is the presence of a constant small term eps to the dispersion component in the encoder. This technique was learned from other autoencoder implementations and generally improves training stability.
The next aspect of the model that is worth paying attention to is batch normalization. As practice shows, without a batch norm, autoencoders tend not to expand the latent space into a cluster structure. Apparently, this is a fairly common problem with autoencoders, and batch normalization allows us to combat this to some extent.
During training of the presented model, gradient clipping is used to slightly slow down the convergence rate of the mesh weights in the hope of better final results.
And the last thing worth saying about the presented model is that it is not in fact fuzzy inference system, since characteristic functions alone are not enough to call it that. If we add to FuzzyLayer linear layer at the input and softmax at the output, then in this form this construction can already be passed off as Mamdani’s fuzzy inference. Then the latent vector from VAE will be a set of features, a linear combination of which activates one or another fuzzy inference rule.
Now we won’t dive so deeply into this, we’ll just note that it is possible to build such systems.
As they say, I will give the lever, but I will not give the stone.
Experimenting with a fully labeled dataset
Let's finally move on to pictures and graphs.
First of all, let's consider a pure VAE with fuzzy components disabled (gamma = 0) so that we have at least some guidelines. After 50 iterations of training on the test set, we have the following picture for the loss of the VAE component:

And in the latent space some structures were formed that were colored according to the actual class label

The clusters correlate quite well with the real numbers, although creeps and overlaps are visible.
At this point, we need to overcome the strong desire to search for clusters using the same k-means and continue to live in the damned world that we ourselves will create.
Let's go further, now turn on the fuzzy layer (gamma = 1) and train the model on a fully labeled dataset of 10 classes of numbers, and for now disable 2 classes of outlines via a mask.

There is no fundamental difference in the final losses of the VAE component; the overall loss is perhaps higher due to the fact that it has been added to loss_fuzzy.
The classification accuracy of 10 digits on the test sample was ~ 96.52%. Before you close this article with laughter, remember that the dimension of latent space is two. In practically useful problems, the struggle for inference accuracy should begin with selecting the correct dimension of the latent vector. In the MNIST problem we were able to get the results above 99% on latent space dimensions above 12. However, visualization of 12-dimensional spaces is not an acquired taste and, no, t-sne is a bad recommendation, because we already know that we have pronounced cluster groupings.
This is what the structure of the latent space looks like with loss already enabled for the fuzzy layer

The clusters became noticeably better separated, and their relative positions changed.
Let's include all 12 classes, add two more descriptive classes to the 10 numbers and see what happens.

The losses of the VAE component plus or minus are the same, but the classification accuracy of 10 digits on the test sample was already ~ 97.52%, a full percentage higher. We won’t prove it statistically and deal with this phenomenon now, that’s not what the article is about. But looking ahead, we note that CVAE with a fuzzy classifier actually works better, the more diverse consistent We provide expert information about the elements of the training sample.

A number of interesting observations can be deduced from the structures of latent space.
First of all, this is a number class 4, which turned out to be borderline between classes with closed rounded outlines and without. It turns out that some numbers 4 have variants with a closed top. In this case, the largest area of contact with 4 the class has 9 And 0and classes 6 And 8 they practically do not come into contact with the four.
Let's now try to meaningfully travel through the latent space and turn 9 V 4 in two different ways – the first one entering close to the area of fours with closed contours, and the second – further away from the line of contact deeper into the cluster 4.

The numbers generated along route 1 turned out to be more blurry and difficult to distinguish from each other, and the contours of the fours were closed at the top.

On the second route, the images turned out to be clearer and easier to distinguish from each other, and the contours of the fours became open.
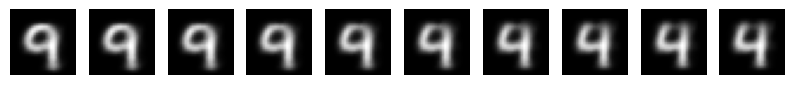
The fundamental point here is that we have just received a tool with which we can purposefully transform and generate the data that CVAE works with. At the same time, it is possible to endow them with properties conveyed using expert knowledge in markup. We remind you that specific parameters of cluster centroids and areas of their placement can be extracted from the matrix  corresponding terms of the fuzzy layer.
corresponding terms of the fuzzy layer.
Partially labeled datasets and accelerated additional labeling
Let's move on to the second crowning feature of fuzzy CVAE – training on partially labeled datasets.
Let us present the dependence of the accuracy of the 10-digit classifier on the test dataset on the percentage of unlabeled data.

Yes, from a statistical point of view, the result is not entirely correct, but the fundamental point is reflected here, and it cannot be hidden behind the lies of statistics: more or less acceptable results can be achieved on half of the labeled dataset, but further significant improvement is possible if you add the same amount more labeled data. This effect is primarily due to the fact that when marking using the square-cluster method, when everything that comes to hand is marked, there is often a situation of excessive marking. In other words, in such cases, marking new examples does not provide new knowledge of the neural network model.
We use an approach where CVAE with fuzzy layers was trained on a small portion of labeled data, and further labeling is carried out iteratively, using hints from CVAE. Each markup cycle marks new examples of classes and errors made in the previous iteration. After re-labeling a new small portion of data, CVAE is re-trained and the procedure is repeated again. The labeling process stops when a new piece of data does not provide a significant increase in the quality of the model output. Then a decision is made to either build a more complex CVAE or operate the resulting model.
The above procedure has proven to be very effective for quickly prototyping models in one helmet and in short time.
A possible reason for this efficiency is most likely due to the fact that the additional training procedure does not require a radical restructuring of the variety of latent data representation – the VAE features are already approximately located in their places, the centroids of the Gaussians from the fuzzy layer migrate slightly to new positions during additional training, everything is smooth, smoothly, without tears.
Conclusion
For now, this is all we would like to share with you. Of the big issues that have not been addressed, there remains anomaly detection, which, with the help of FuzzyLayer becomes an interesting and exciting thing.
We'll talk about it next time if you want.
The bottom line is that a CVAE model with a fuzzy classifier is presented, which allows you to reorganize the structure of the latent space in the most gentle way for VAE, preserving its cluster structure. This makes it possible, using expert knowledge (markup), to localize areas of latent space associated with specific classes from the markup. And this, in turn, makes the process of generating latent vectors a more manageable process.
On the other hand, when additional training of such models, the absence of explosive reconstruction of the latent manifold makes it possible to iteratively mark up the minimum required dataset for an acceptable solution to the problem.
Thanks to @dnlhov for help in this publication, together with whom we are developing this topic to a product state. I also express my gratitude to @sukharudze and @St_Hedgehog for productive discussions and comments.
The full code of modules and examples mentioned in the article can be found in the repository pytorch-fuzzy.





