ABBYY FineReader Server against chaos. How does our solution remove duplicates and tidy up business documents?

Hello, Habr! You probably remember the posts about how our ABBYY Recognition Server helped in the digitization of materials and library catalogs on Sakhalin, Latvia, Great Britain and other countries. We haven’t talked about this product for a long time, but all this time it has been developing. We taught him new abilities, improved his skills using the latest generation of intelligent OCR technologies and even gave a new name – ABBYY FineReader Server. Let us explain: under the common FineReader brand, we have combined all products for recognizing, converting and editing documents.
Today ABBYY FineReader Server helps not only to digitize materials from libraries and archives, but also to organize the storage of information in large companies. For example, the group FESCO digitizes accounting invoices and waybills and sends them to a single electronic archive in order to conduct transactions faster, and employees PwC converts photos of invoices, contracts and other documents directly from a mobile phone into PDF with the possibility of full-text search and send them to corporate systems. US law firm Kantor & Kantor uses this solution to quickly find meaningful information in thousands of pages of court cases.
In this post we will tell you about several new features of ABBYY FineReader Server: how they are technically implemented and why large companies use them.
According to O’Reilly Research “State of Data Quality in 2020”, most large companies have difficulty dealing with corporate information. For example, 60% of respondents noted a large number of corporate sources and duplication of information in them, and 49% – the lack of control over the quality of incoming data. Duplicates are not the only problem. Information becomes outdated, and voluminous and no longer relevant files slow down the search for information, make it difficult for corporate systems, and take up space, which directly affects the cost of data storage. This is not the kind of ballast that should be carried over to brand new DMS or ECM systems.
In fact, such problems are familiar to every user. It is enough sometimes to look at your desktop to understand: it’s time to put things in order in this zoo. What can we say about the corporate repository of a large company, where there are thousands of employees and millions of documents.

Intelligent information processing technologies help to cope with these problems – to manage document flows, store only the necessary data and in the format you need. Below we will tell you about several features that have appeared in ABBYY FineReader Server and will help get rid of the chaos:
• Automatic removal of full duplicates;
• Pre-processing of documents;
• Improved recognition of most popular barcodes, including ISBN, PDF417, Aztec and QR;
• A single web interface for file recognition and conversion;
• Improved compression of color images.
Full Duplicates: Find and Stop

Companies of all sizes tend to have electronic archives that have evolved over the years. Let’s say your SharePoint has historically accumulated a lot of files. What is stored there and how you can quickly find the desired document is sometimes a big secret even for its creators. But not for ABBYY FineReader Server. It has a working mode Audit, which allows you to see which documents are stored in the repository and how many there are.
First, you will get general statistics on files: how many images are in graphic format, scanned copies of documents, PDF with a text layer, MS Word documents. In addition, you will see the total number of files in other, non-text formats: video, audio, executable files, application system files, etc. ABBYY FineReader Server does not process them, but they exist in the archive and this should be taken into account. The audit will also determine how many documents it costs to convert, what groups of duplicates are in the repository and where they are. Let’s tell you more about them.
Hash sum Is a unique identifier for the file. It is calculated by a computer through mathematical transformations of the information contained in it. If files are duplicates, then their hashes will be the same, even if the files have different names and extensions. By default, ABBYY FineReader Server uses the 128-bit MD5 hashing algorithm.
When auditing, FRS calculates the hash sum of each file and then compares them with each other. If they match, then the files are most likely full duplicates and will be included in the report:
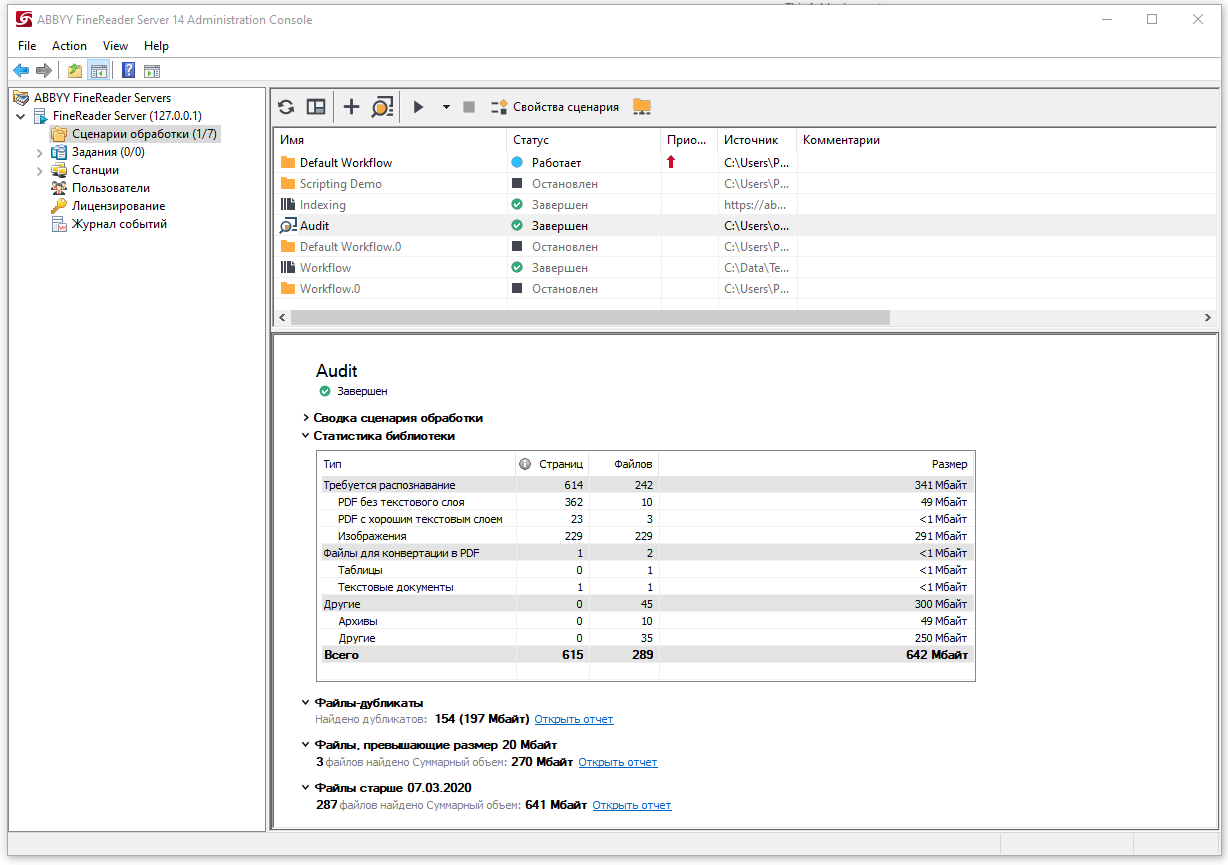
The screenshot shows statistics: how many pictures and scans need to be recognized before conversion, how many text documents can be converted to PDF and how many files in the storage that cannot be processed using FRS. Below the sign there is a report on duplicates and on files larger than 20 MB.
Let’s say a company decides to organize a centralized electronic archive based on SharePoint instead of a dozen separate repositories. To do this, you first need to analyze which files have been accumulating over the years and are now contained in the archives. What if it’s full of duplicates and outdated documents? And the company just does not need such copies, because it wants to store fewer documents and it is easier to search for the necessary information in them. After conducting an audit, you can carefully look into black hole electronic storage and see if there are duplicates and if so, what documents are we talking about. It is convenient to start an audit as a first step if the company has a large storage and, for example, you need to calculate how many pages you need an FRS license to process files.
The second mode of operation of FRS – Treatment… If the company does not want to send duplicate documents to the new repository, then the program can be checked Exclude duplicate files…

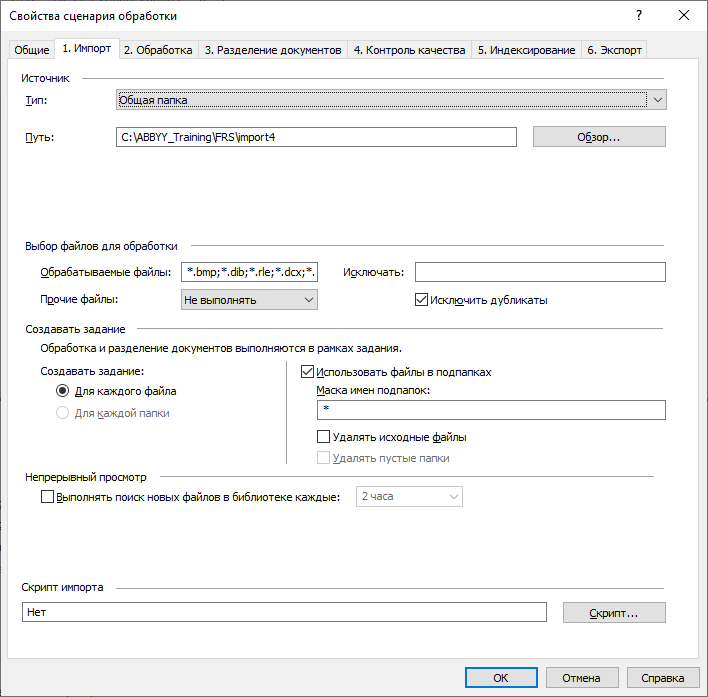
In this case, FRS processes the files, converts, and at the same moment calculates the hash of each of them and compares it with the hash of each file already found in the storage. The solution processes one file from the group of duplicates, and skips the rest. If the contents of two files are completely the same, but the names of the files are different, then such files are also considered duplicates.
When the processing is complete, FRS will report duplicates again. This is done for those users who do not know about the audit, do not want to run it, or accidentally skip this stage. They may have a question: “Were there any duplicates in the repository? What files are they? Are there many of them? ” The report will show a group of duplicates.
How to improve image quality
When processing in FRS, files go through several stages. For example, images to be recognized are first sent to the so-called preprocessing… At this stage, various filters are applied to the document in order to improve the quality of its recognition. For example, if the user has low quality scans, he can try to change the set of settings to improve the image quality: for example, adjust the brightness, contrast, intensity level of light and shadow, rotate, crop unnecessary borders, lighten the background, etc.
In most cases, the preprocessing profile that is configured in FRS by default is sufficient. It is an optimal set of filters that improves the quality of a large number of documents. The solution automatically sets the resolution suitable for text recognition, determines if the image is not rotated, and corrects skews.
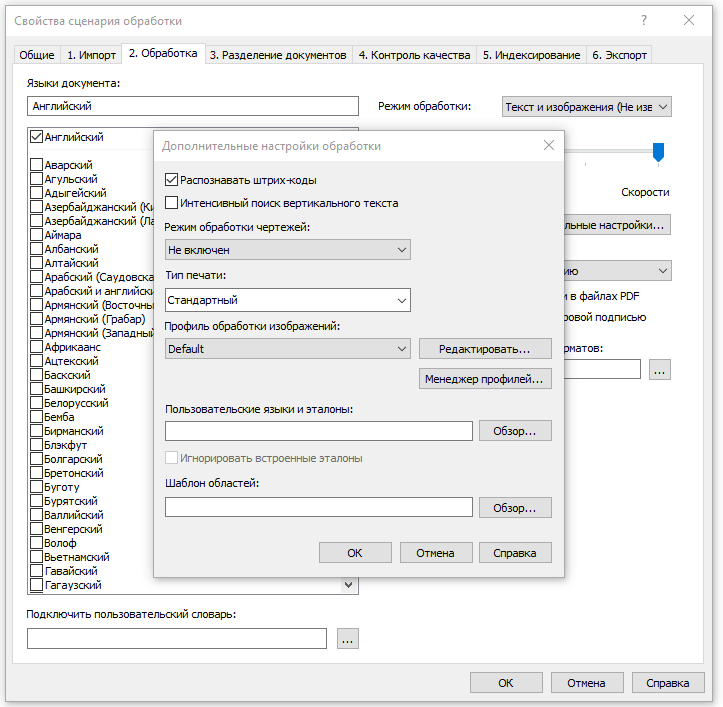
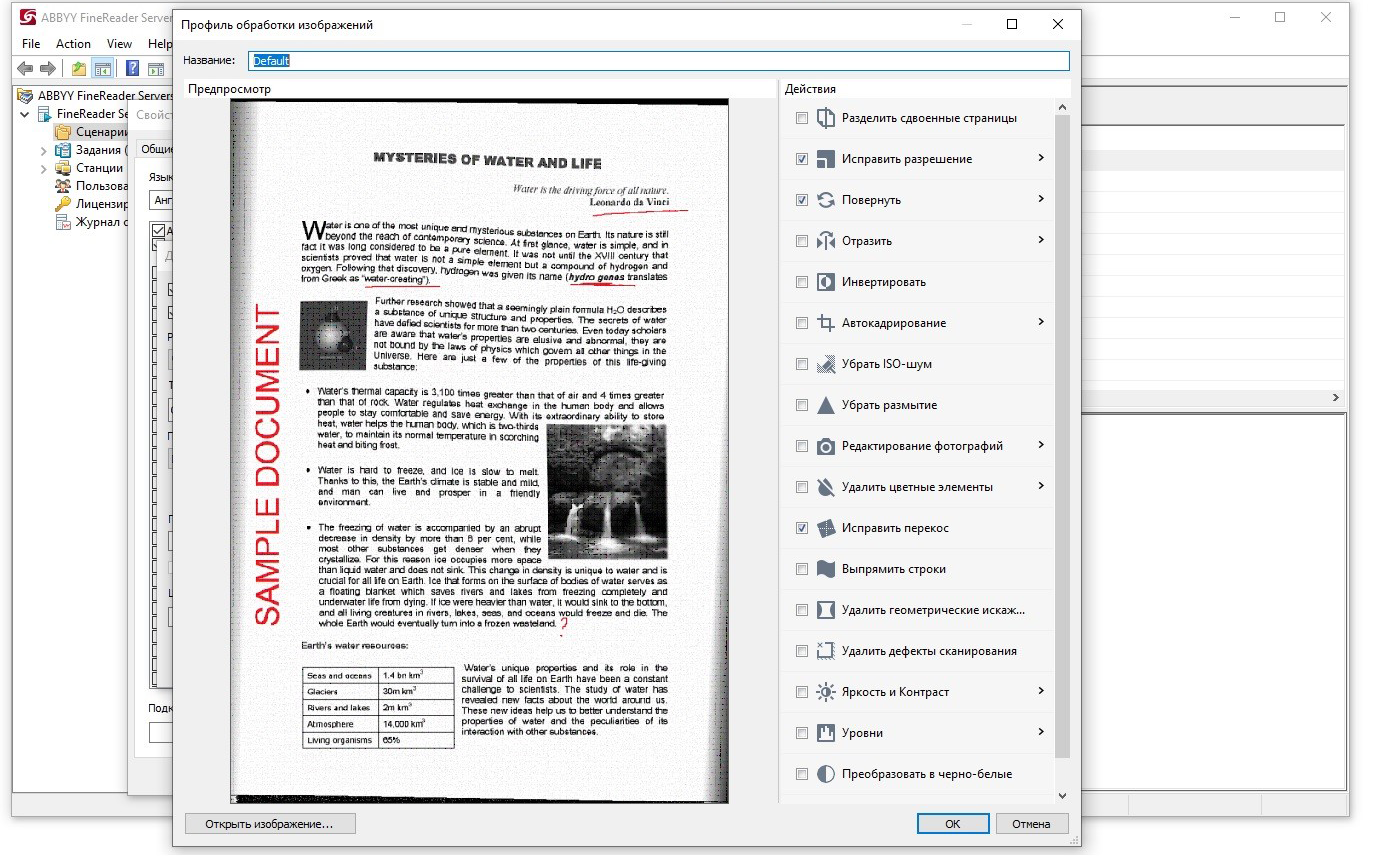
The user can choose the optimal set of filters for his documents himself and combine his groups of settings into a profile. This is convenient so that you don’t have to set 100,500 daws every time. There can be as many profiles as you like – for photo processing, for scans, etc.
Users and companies set up their image preprocessing profiles with:
• Very specific documents, such as some photographs taken in a dark room.
• Documents, on the basis of which critical decisions will be made, and here it is important to fight for every percentage of recognition quality that can be improved.
• Objective – to recognize and convert files for further sending documents to intelligent systems for analyzing and extracting text information using NLP technologies – for example, on eDiscovery platforms. For them, the quality of the text is very important, and the slightest typo in a word can lead to incorrect results. For example, an entity will not be highlighted on some word.
Bewitched with barcodes
 Compared to the previous version of the solution, our developers have significantly improved the recognition of ISBN, PDF-417, Aztec and QR codes. In some categories, the quality increased by 15%. At the same time, the processing speed increased by 20%.
Compared to the previous version of the solution, our developers have significantly improved the recognition of ISBN, PDF-417, Aztec and QR codes. In some categories, the quality increased by 15%. At the same time, the processing speed increased by 20%.
We will tell you in what cases companies use such barcodes and why they need to be recognized.
The first… Logistics, transport and other companies often receive large files, which contain many scans of different documents at once – for example, invoices. And to divide this file into independent documents, a barcode is placed on the first page of each new invoice. FRS has a function for separating documents by barcode. As a result, export results in several neatly divided files instead of one large combined document.
Second… In banks, retail stores and other companies, sometimes the barcode value itself can be somehow used, for example, the file name can be encrypted in it. For example, a large retail chain may have a flow of documents from different suppliers. They use different barcodes. FRS will help you process the entire array of documents and immediately put invoices from each supplier into separate folders.
By the way, in one of the European banks we had an interesting case. The company received paper letters with barcodes, the names of the addressees were encoded in them. The client wanted to digitize such barcodes in order to send the digitized document by e-mail to the addressee who received the paper letter.
Recognition and conversion right on the web
Employees of large companies at work often need to quickly recognize and convert files into the formats they need. For example, the accounting department receives scans of invoices or invoices from contractors in different graphic formats: JPEG, TIFF, PDF. Specialists need to convert all documents into a single format, for example, to PDF with a text layer, and then forward them, put them in storage, etc.
Previously, FRS had two options for this conversion.
First: sysadmins set up two shared folders. The end user put his document into one of them, and after a while a document appeared in the output folder, already converted into the required format.
Second. The user sent a letter to a specific address with an attached document that needs to be converted or recognized. In response, he received an email with the recognition result.
Both of these methods still exist. But since everything is moving towards the web, a third opportunity has appeared in FRS – converting and recognizing documents through the web interface. We tried to make it as simple and straightforward as possible.
You upload a file, select one or several formats to convert the document into, and also select the languages that are used in the document. You get the result.
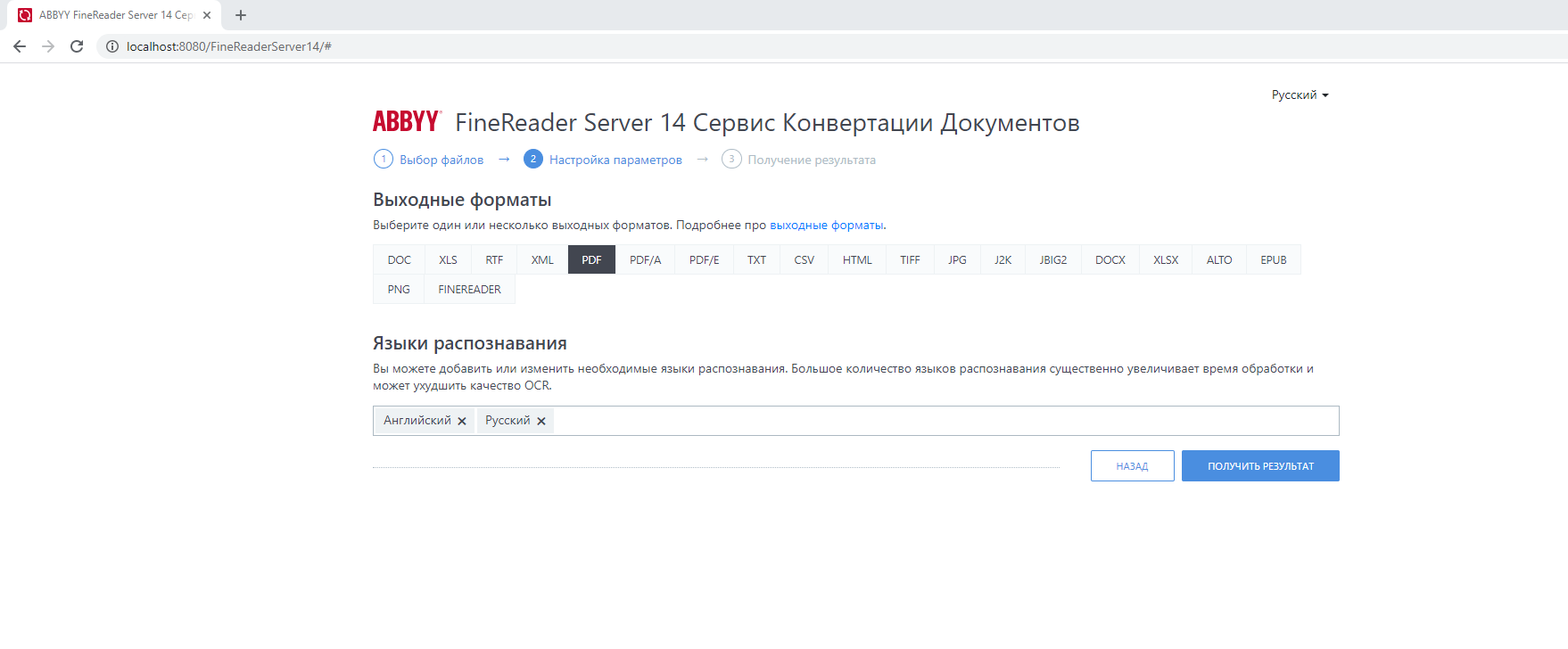
Such a service can come in handy in any company where people need to convert files in bulk. Moreover, end users do not have to waste time on settings. Everything is ready to go, just drop the file and get the result.
Better image quality and lighter weight
At FRS, we have enhanced the MRC compression algorithms to provide high quality color images while compressing heavy files. First, we selected more optimal MRC compression parameters for the minimum size and balanced modes. Secondly, we used a lax color detection detector: this means that “almost black and white” images are processed as black and white. This allows them to be significantly reduced in size. Testing the feature on samples from the ABBYY image database showed that the compression level for files with color images improved by 10-30%.
Such compression is required to convert files to PDF format. The smaller the size of the document with the image, the faster it opens on a mobile device, is downloaded from a website or sent by mail.
As a conclusion
This article tells about the most interesting and necessary, in our opinion, new features of ABBYY FineReader Server. You can try them now – download trial version product for free. If you are interested in learning more details about FRS, then write your questions in the comments!





