a review of the latest events that rocked the world of AI
We give a detailed plot of personnel changes at OpenAI and Microsoft, talk about Q*, its possible connection with Q-learning and MRPPS with technical details, and reflect on artificial general intelligence.
Not long ago, the AI world was rocked by news of personnel changes at OpenAI: the company’s board of directors fired its CEO Sam Altman, the most prominent figure in the field of generative AI. Altman learned about his resignation at an online meeting of the board of directors, organized on the initiative of Ilya Sutskever, chief scientist at OpenAI: “…has not always been frank in his interactions with the board, which limits his ability to fulfill his duties” is exactly what the part sounds like the wording of the statement.

Altman was replaced on an interim basis by Mira Murati, chief technology officer. In addition, the personnel changes also affected Greg Brockman, who lost his co-founder status. Investors, like ordinary employees, were not prepared for such a development of events. If the former were allegedly notified of the resignation of the “face of OpenAI” a few minutes before the announcement of the board of directors, then for the latter it definitely came as a shock. What happened, according to the media, is the result of a hidden confrontation between Altman, who advocated the active development of AI, and the board of directors, whose position was a smoother and more consistent development of artificial intelligence.
Less than a day later, the OpenAI board of directors changed its mind and began to consider the option of returning Sam Altman to his previous post. A day later, he had to visit the company office using a guest badge. The purpose of the visit is negotiations with the board of directors. They had to agree with Altman’s demands and return the CEO’s chair to him, which, it seemed, was not destined to happen:

Meanwhile, Emmett Shear has become OpenAI’s new “new” CEO, replacing Mira Murati. He previously held a similar position at Amazon Twitch. Murati regained her position as technical director.

The next shock was that more than 700 company employees signed a letter calling for the return of Altman and Brockman and the dissolution of the previous OpenAI board of directors. They themselves planned to follow their ideological leader to Microsoft, where they are now developing a chatbot built into Bing and working on DALL-E. And oh, miracle! A couple of days later, OpenAI announced Altman’s return to the position of CEO. He’s also forming a new board of directors that includes chairman Bret Taylor, Larry Summers and Quora CEO Adam D’Angelo. Ilya Sutskever, as well as Tasha McCauley and Helen Toner, left their chairs.


Interestingly, everything that happened was preceded by several events. The first is a letter to the board of directors from the company’s research team. What was in the letter? Mystery. What is clear is that the information it contained influenced the decision to Altman’s dismissal. Presumably, it talks about the creation of AI, which, according to council members, could pose a real danger. We are talking about the Q* or Q-Star algorithm – a potential breakthrough in the field of artificial intelligence.

The second is Sam Altman’s statement at the Asia-Pacific Economic Cooperation summit of world leaders in San Francisco: “In the history of OpenAI, I’ve had the privilege of being in the room four times now (most recently just in the last couple of weeks) as we kind of pushed back the veil of ignorance and pushed the frontiers of discovery forward, and it’s been the professional honor of a lifetime to be able to do that.”
A day later, the decision was made to fire him.
")
In fact, it is unknown how OpenAI is developing its technology. It is also unknown how Altman supervised the work on future, more powerful generations. What is clear is that the non-disclosure campaign is working very well. Almost.
Theory 1: Q-learning
Q* is based on the Q-learning method, which includes training an algorithm. It works on the principle of positive or negative feedback to create game bots and customize ChatGPT to be more useful. AI can independently find optimal solutions without human intervention, unlike OpenAI’s current approach of learning with human feedback (RLHF).

In Q-learning, Q* is the desired state where the agent knows what to do to increase the level of total expected reward over time. From a mathematical point of view, it satisfies the Bellman equation, which describes the optimal value of a state function or strategy in problems where decisions are made sequentially over time. In the case of a control problem, the Bellman equation can be expressed as a recurrence relation that relates the optimal value in the current state to the optimal values in subsequent states.

Q-learning refers us to the A* search algorithm, which can search for the best solutions. For example, as in the case of splitting complex mathematical problems into a chain of logical steps. This hints at the possibility of creating AI capable of deeper and more strategic thinking. Reminds me of the methods used in the AlphaGo or AlphaStar systems, doesn’t it? Let us recall the search for a token trajectory using a Monte Carlo tree. This method is most useful in programming and mathematics, which explains the information about Q* as a breakthrough in solving mathematical problems.
 uses the UCB (Upper Confidence Bound) approach, which has four phases: selection, expansion, simulation and backpropagation.")
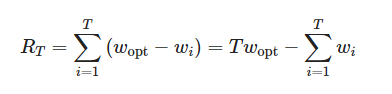
![The basis of UCT is the solution to the problem of multi-armed bandits. This version has graphs for four metrics: probability of choosing the optimal hand, average reward, total reward, and cumulative regret, which is the expectation of cumulative regret. Under the condition of a non-optimal strategy, it is bounded from below logarithmically: E[RT] = Ω (log T).](https://habrastorage.org/getpro/habr/upload_files/94c/6ff/245/94c6ff245e4654b7b45161e69c3d4f22.png "The basis of UCT is the solution to the problem of multi-armed bandits. This version has graphs for four metrics: probability of choosing the optimal hand, average reward, total reward, and cumulative regret, which is the expectation of cumulative regret. Under the condition of a non-optimal strategy, it is bounded from below logarithmically: E[RT] = Ω (log T).")
There was also talk about improving RAG (Retrieval Augmented Generation), the results of which were recently shown at OpenAI DevDAy. First, algorithms search and extract relevant pieces of information based on a user prompt or question, using BM25 for example. Next comes content generation by a language model such as GPT. It uses the resulting context to generate natural language responses.

A detailed analysis of existing reports, combined with the most pressing problems in the field of AI, suggests that the project that OpenAI spoke about in May was built on reducing the logical errors that large language models, for example, LLM, make. A process control technique that involves training an AI model to break down the necessary steps to solve a problem can improve the algorithm’s chance of getting the right answer. Thus, the project showed how this can help masters of law to accurately solve problems that require basic knowledge of mathematics.
“Q* could involve using huge amounts of synthetic data combined with reinforcement learning to teach LL.Ms specific tasks such as simple arithmetic. Kambhampati notes that there is no guarantee that this approach will be generalized into something that can figure out how to solve every possible mathematical problem.” — Subbarao Kambhampati, a professor at Arizona State University who studies the limits of LL.M. reasoning.
“LLMs aren’t so good at math, but neither are people” – says Eun. “However, if you give me a pen and paper, then I’m much better at multiplying, and I think it’s actually not that hard to set up an LLM with memory to be able to step through the multiplication algorithm.” – Andrew Ng, professor at Stanford University, head of artificial intelligence laboratories at Google and Baidu.
Theory 2: MRPPS
The proposed relationship between the Q* algorithm and the MRPPS (Maryland Refutation Proof Procedure System), which consists of several methods: binary resolution and factoring, a set of auxiliary tools, P1-Deduction, linear resolution, input resolution, linear resolution with selection function, combination of logic systems output and paramodulation. The most obvious field of application is the question-answer system. The idea is to combine semantic and syntactic information, which could mean progress in AI’s deductive abilities.
 to use. In addition, MRPPS allows multiple combinations of the above inference systems to be used simultaneously, although in some cases the resulting inference system may be incomplete. For example, if set-of support and Pl-deduction were used simultaneously, completeness could only be guaranteed if the intended theorem, together with all positive propositions, had support. Poke.")
This can be most simply explained by remembering Sherlock Holmes, the hero of Arthur Conan Doyle’s books. A fictional detective collects clues in the form of semantic information and connects them using syntax. Q from MRPPS works in a similar way.
It is worth noting that OpenAI did not explain the structure and did not even confirm or deny rumors about the existence of Q*. But we can’t help but take into account that OpenAI may have become closer to a model that understands the task without a text query.
Consequences
If Q* is an upgraded form of Q-learning, then the AI will improve its ability to autonomously learn and adapt. This can find application in areas where split-second decisions are needed in the face of constantly changing values. In the field of autonomous vehicles, for example.
If Q* refers to the Q algorithm from MRPPS, then the artificial intelligence will be capable of deeper deductive reasoning. For example, in areas where analytical thinking is involved: medical diagnostics, legal analysis, etc.
Under any circumstances, a leap in AI development is highly plausible. However, this also raises a number of new ethical and legal issues affecting security and privacy issues. It is impossible not to note the economic consequences: once again the notorious narrowing of the personnel market comes to mind.
What about AGI?
We should not forget that the ultimate goal of research in the field of AI in the form of AGI is still unattainable, since there is not yet a clear alternative to cognitive human abilities, and modern artificial intelligence cannot be called completely adaptive and universal. So far, the Q* algorithm is not capable of self-identification and works exclusively within the limits of the initial data, as well as the specified algorithms.
Conclusion
Not long ago, tech forums were abuzz with the possibility of artificial intelligence wiping out humanity. His name is p(doom). It is a hundred-point scale. The more interest you assign to yourself, the more convinced you are of the helplessness of humans in front of AI. Write your meaning, justifying it, of course. It will be interesting. Not as interesting as if AI takes over humanity, but still.

We look forward to seeing you in the comments and thanks for reading!
Author: Vlad Smirnov