a new approach to processing long sequences by large language models

Transformers are great neural networks for working with text, speech, images, and other types of data, but they face the problem of the limited length of the context they can access. The longer the sequence, the more calculations are required so that the transformer can take into account all the elements. This leads to the fact that transformers cannot effectively model long-term dependencies and remember important information from the past. Infinityformer solves this problem by using a continuous attention mechanism, which allows you to refer to the past context as a continuous signal, rather than as a discrete sequence. This makes Infinityformer’s attentional complexity independent of context length and allows arbitrarily long sequences to be modeled and sticky memories to be maintained that highlight the most significant events from the past.
In this article, I will talk as hardcore as possible about how Infinityformer works.
How Infinityformer works
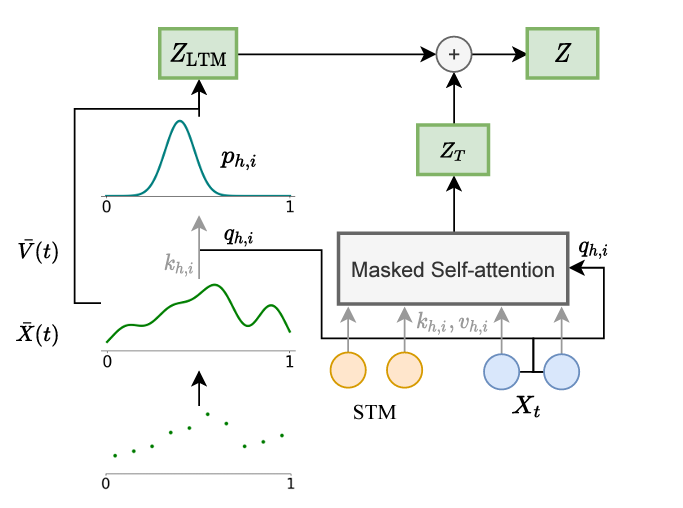
Infinityformer is a model that consists of two parts: short-term memory (STM) and long-term memory (LTM). STM is a standard transformer that handles the current context, while LTM is an extra memory that stores information from the past context. In order to link STM and LTM, Infinityformer uses a continuous attention mechanism, memory gluing and compression, and sticky memories.
Continuous Attention Mechanism for Dealing with Unlimited Long-Term Memory
The continuous attention mechanism is a way of referring to the LTM as a continuous signal rather than as a discrete sequence. This allows attention complexity to be reduced from quadratic to linear with respect to context length. The continuous attention mechanism works like this: first, it applies a kernel function to the LTM, which converts discrete elements into continuous values. It then calculates the similarity between STM and LTM using the dot product. Finally, it calculates the attention weights using the activation function and gets the output representation.
Memory bonding and compression to reduce computational complexity
Memory bonding and compression is a way to control the size of the LTM and keep it unbounded. Memory gluing is that each new element from the STM is added to the end of the LTM, forming a longer sequence. Memory compression consists in the fact that every two adjacent elements in LTM are combined into one element using a linear transformation. This reduces the LTM length by half and retains its information content.
Sticky memories for highlighting important events from past context
Sticky memories are a way to control which elements from the LTM are more important to the current context and should be better represented in the output representation. Sticky memories work like this: first, they calculate the importance of each element from the LTM using a scoring function that depends on its content and position. They then select a number of the most important items using the importance sampling method. They increase the attention weights for the selected items with the boost feature.
The evaluation function determines how relevant an element from the LTM is to the current context. It can take into account various factors such as how often an element occurs, its semantic meaning, its relationship to other elements, and so on. For example, the score function may be proportional to the inverse distance between an element and the current context, which means that newer elements are of greater importance.
The importance sampling method determines which elements from the LTM will be used as sticky memories. It can be based on different strategies such as random selection, top-k selection, or importance distribution sampling. For example, the importance sampling method can select k items from the LTM with a probability proportional to their importance.
The boosting function determines how much the attention weights for sticky memories will be boosted. It can be a constant or depend on various factors such as the element’s importance, its distance from the current context, or its similarity to other elements. For example, the boost function could be an exponential function of the item’s importance, meaning that more important items get more attention.
Sticky memories allow Infinityformer to extract the most significant events from the past context and use them to enrich the current context. This improves the quality of modeling long-term dependencies and increases the accuracy of solving various problems.
Conclusion
This model has shown excellent results on various tasks related to sequence processing, such as sorting, language modeling, and dialog generation. In the future, Infinityformer can be improved by using more sophisticated scoring, sampling, and amplifying functions for sticky memories, as well as adaptive methods for gluing and compressing memory.
Infinityformer opens up completely new possibilities for the study and application of transformers on long sequences and offers a new approach to the implementation of unlimited memory.