Why I no longer recommend Julia
For many years I have used a programming language
to transform, clean, analyze and visualize data, calculate statistics and run simulations.
I have published several open source packages to work with things like signed distance fields, find nearest neighbors and Turing patterns (a also with others), created visual explanations for Julia concepts such as broadcasting and arraysand also used Julia when creating generative graphics for my business cards.
Some time ago I stopped using Julia, but sometimes I get questions about it. When people ask me, I reply that I no longer recommend it. I thought it was worth writing why.
After using Julia for many years, I came to the conclusion that there are too many correctness and compatibility bugs in its ecosystem, and this does not allow using this language in contexts where correctness is important.
In my experience, Julia and its packages have the highest frequency of serious correctness bugs of any software system I’ve used, and I started programming with Visual Basic 6 in the mid-2000s.
It would probably be useful to give specific examples.
Here are the correctness issues I have reported:
Here are similar issues reported by other people:
I have encountered bugs of this level of severity often enough that it made me question the correctness of any calculations of moderate complexity in Julia.
This was especially true when using a new combination of packages or features – combining functionality from multiple sources was a significant source of bugs.
Sometimes problems arise from incompatible packages, other times unexpected combinations of Julia features within the same package lead to an unexpected crash.
For example, I found out that the Euclidean distance from the Distances package does not work with Unitful vectors. Other people have found that the Julia function to run external commands does not work with substrings. Someone figured out that support for missing Julia values breaks matrix multiplication in some cases. And that the standard library macro @distributed did not work with OffsetArray.
OffsetArray generally turned out to be a serious source of correctness bugs. The package provides an array type that uses flexible custom index feature Julia, which allows you to create arrays whose indices do not have to start with zero or one.
Using them often results in out-of-bounds memory accesses that you might encounter in C or C++. If you’re lucky, this will lead to a segfault, and if not, the results will be incorrect without error messages. One day I found bug in Julia corewhich can result in out-of-bounds memory accesses even if both the user and the library creators have written correct code.
I have submitted many indexing issue reports to JuliaStats, an organization that maintains statistical packages like distributionson which 945 packages depend, and StatsBase, on which 1660 packages depend. Here are some of them:
- Most sampling methods are unsafe and incorrect in case of offset axes
- Distribution alignment DiscreteUniform may return incorrect response without error message
- counteq, countne, sqL2dist, L2dist, L1dist, L1infdist, gkldiv, meanad, maxad, msd, rmsd, and psnr with offset indexes may return incorrect results
- Incorrect use of @inbounds can cause incorrect calculation of statistics
- Colwise and pairwise may return incorrect distances
- Mapping a Weights vector wrapping an array with an offset performs an out-of-bounds memory access
The root cause of these problems is not the indexing itself, but its sharing with another Julia feature called
@inbounds
which allows Julia to remove bounds checks when accessing arrays.
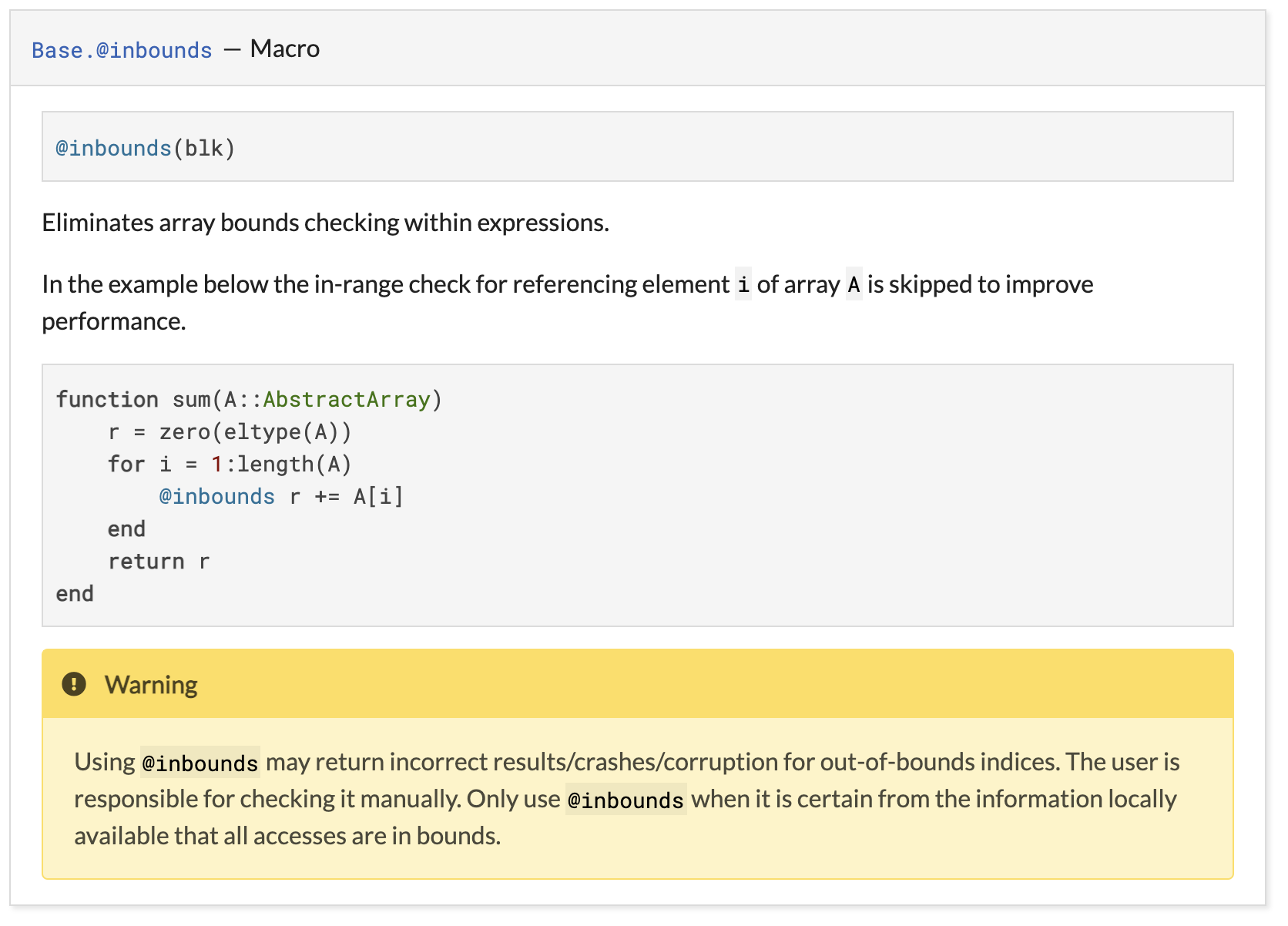
Example:
function sum(A::AbstractArray)
r = zero(eltype(A))
for i in 1:length(A)
@inbounds r += A[i] # ← 🌶
end
return r
endThe above code iterates
i
from 1 to the length of the array. If you pass an array with an unusual index range, the code will perform an out-of-bounds memory access: array access operations are annotated
@inbounds
which removes bounds checking.
This code shows how not right use @inbounds. However, for many years this was the official example of correct use @inbounds. This example was placed right above the warning about why it’s wrong:
already eliminated, but there is concern that
@inbounds
can be misused so easily, leading to subtle data corruption and incorrect mathematical results.
In my experience, these errors are not limited to the math part of the Julia ecosystem.
I encountered library bugs in the course of everyday tasks, for example, when coding JSONsending HTTP requestsuse Arrow files jointly with DataFrames and editing code Julia in a reactive environment of laptops Pluto.
When I wondered if my experience was representative, a lot of Julia users shared similar stories with me. Recently, public reports of similar experiences have also begun to appear.
For example, in this post Patrick Kiger describes his attempts to use Julia for machine learning research:
The Julia Discourse has quite a few posts “The XYZ library doesn’t work”, followed by the response of one of the library’s maintainers: “This is an upstream bug in the new abc version of the ABC library that XYZ depends on. We will push the ASAP fix.”
Here’s what Patrick’s experience with fixing the correctness bug was (emphasis mine):
I clearly remember the moment when one of my Julia models refused to learn. I spent months trying to make it work, trying every trick I could think of.
Finally I found the error: Julia/Flux/Zygote returned incorrect gradients. After putting so much energy into points 1 and 2 above, I just gave up at this point. After another two hours of development, I successfully trained the model … in PyTorch.
AT
This post, other users wrote that they also had a similar experience.
Like @patrick-kidger, I suffered from bugs with incorrect gradients in Zygote/ReverseDiff.jl. It cost me weeks of my life and forced me to seriously rethink my level of experience in the entire Julia AD system. In all the years of working with PyTorch / TF / JAX, I have never encountered a bug with incorrect gradients.
:
Since I started working with Julia, I’ve had two bugs with Zygote that slowed me down for many months. On the other hand, it made me dive into the code and learn a lot about the libraries I use. But I ended up in a situation where the workload became too much and I spent a lot of time debugging the code instead of doing climate research.
Given the extreme generality of Julia, it is not obvious
is it possible
solve correctness problems. In Julia there is no formal concept of interfaces, in generic functions often semantics are not specified in edge cases, and the nature of the most general indirect interfaces is not made clear (for example, there is no agreement in the Julia community about what constitutes a number).
The Julia community is full of capable and talented people who generously share their time, work and experience. However, systematic problems like this are rarely corrected from the bottom up, and it seems to me that the project management does not agree that there is a serious correctness problem. It accepts the existence of separate, unrelated problems, but not the pattern that these problems imply.
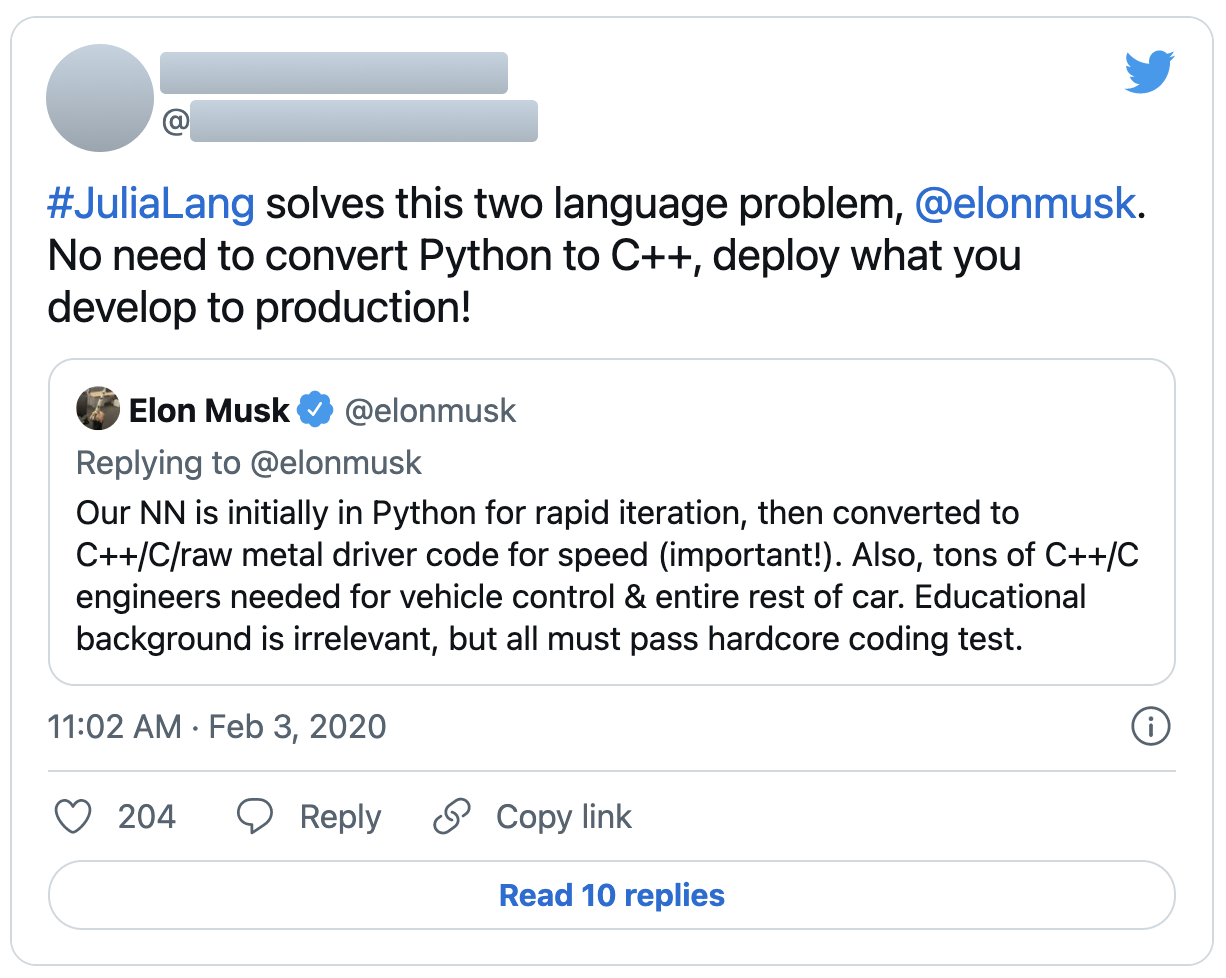
For example, at a time when the Julia machine learning ecosystem was even more immature, one of the creators of the language spoke enthusiastically about using Julia in self-driving car production:
And while attitudes may have changed since I stopped being an active participant, the following quote from another creator of the language around the same time is a good illustration of the difference in perceptions (emphasis added):
I think the most important takeaway here is not that Julia is a great language (although it is) and that it should be used for everything (although it’s not a bad idea), but that its architecture has taken an important step towards being able to code reuse. In fact, in Julia you can take generic algorithms written by one person, and custom types written by other people, and use them simply and efficiently. This seriously raises the stakes in the level of code reuse in programming languages. Language designers don’t need to copy all of Julia’s features, but they should at least understand why it works so well and aim for the same level of code reuse in future architectures.
Every time there is a post criticizing Julia, people from the community are usually quick to reply that there used to be problems, but now things have improved significantly and most of the problems have already been fixed.
Examples:
These answers often seem reasonable in their narrow context, but in general they make real situations seem downplayed and deep problems go unrecognized and unresolved.
My experience of interacting with the language and the community over the past decade suggests that, at least in terms of basic correctness, the Julia language is currently unreliable and not on the path to becoming reliable. In most of the use cases that the Julia development team is aiming for, the risks are simply not worth the rewards.
Ten years ago, the creators of the Julia language told the world about inspiring and ambitious goals. I still believe that one day they can be achieved, but without revisiting the patterns that brought the project to its current state, this is impossible.