Why engineers can’t estimate development time
A statistical approach to explaining erroneous deadlines in engineering projects

Whether you are a junior, senior, project manager, or senior executive with twenty years of experience, estimating the time of a software development project is never an easy task. No one, regardless of his experience and genius, can claim to know the exact time of completion of a software project.
This problem is especially relevant in software design, but other engineering disciplines suffer from the same. So while this article talks about software design, it applies to some degree to other disciplines as well.
general information
Let’s first take a bird’s eye view of the problem, its implications, and potential root causes.
Problem
Software projects rarely meet deadlines.
Effects
Wasted marketing costs, frustrated customers, exhausted developers feeding low-quality code to meet deadlines at the expense of product reliability degradation, and ultimately the likely project termination.
Known causes
- Incorrect timing (main topic of this article)…
- Requirements that are vaguely formulated at the start of the project with their subsequent change.
- Embellishments: Too much attention is paid to details that are not related to the essence of the project.
- Not enough time has been devoted to the research and architecture design phase. Or vice versa – too much time has been spent.
- Underestimating potential integration problems with third-party systems.
- Striving to “get it right the first time”
- Parallel work on too many projects or distraction (too frequent interruption of the flow).
- An unbalanced balance of quality and performance.
Over-optimism, the Dunning-Kruger effect, sheer uncertainty, or just math?

Fifth stage: ACCEPTANCE.
Over-optimism can be discarded right away – it is logical that no developer who has ever experienced problems with deadlines will be optimistic about their choice. If the project management does not have engineering experience and does not understand what it is doing, then this is a topic for a completely different article.
Some people associate erroneous time estimates with the Dunning-Kruger effect, but if underestimating time is due to lack of experience or overestimation of one’s abilities, then gaining experience should definitely solve the problem, right? However, even the largest companies with almost infinite resources still have surprisingly high rates of missed deadlines, so this hypothesis is disproved. Not to mention the fact that we all experienced it ourselves. Having more experience doesn’t help much in estimating time.
Many developers, especially the most experienced ones, quickly come to the conclusion that it is purely a matter of uncertainty. Therefore, time estimates will always be wrong and this is just a fact of life. The only thing we can do about it is to try to satisfy the client’s requirements and ask the developers to “just crunch” when things go awry. We are all familiar with the stress, junk code, and utter chaos created by such a philosophy.
Is there a technique in this madness? Is this really the best way to solve problems? I don’t think this is so, so I decided to go in search of a rational mathematical explanation for why all these smart people cannot estimate the time it will take them to complete the work.
It’s just math!

I once did a task that was supposed to take 10 minutes, but ended up taking 2 hours. I started thinking about why I decided it should take 10 minutes and how that number had grown to 2 hours. My thought process was pretty interesting:
- I thought it would take 10 minutes, because in my head I knew 100% of the code that needed to be written.
- It really took about 7-10 minutes to write the code. And then it took 2 hours because of a completely unknown bug in the framework.
In project management they like to call it “Force majeure” – external uncontrolled reasons for the delay.
You are now probably thinking that with this example, I validated the planning uncertainty argument. In fact, yes and no. Let’s take a look from a little distance. Yes, indeed, uncertainty was the root cause of the delay this particular task, because I would never have guessed that such a bug exists. But should she be responsible for the delay the whole project?
Here we need to draw a line between a single task that is not representative of the whole process, and vice versa.
How do we measure time under “normal” conditions
Normal distribution (Gaussian)
Normal distributions are ubiquitous, and the human brain is comfortable with them. We are experts in evaluating processes that follow a normal distribution in nature; it is the basis for gaining knowledge from experience…
If this month you went to the nearest store almost 20 times and each time it took 5 minutes, except for the case when the elevator broke down and you had to wait 10 minutes, and also the case when you decided to wait two minutes for the rain to stop. How long do you estimate it will take to get to the store right now? 5 minutes?
I mean, it doesn’t make sense to say “15 minutes” because that’s a rare case, or “7 minutes” unless it’s raining outside. And most likely you will be right. If in 18 out of 20 cases the journey took 5 minutes, then there is definitely a high probability that it will take 5 minutes (median) this time. The probability is approximately equal to 90% (unless, of course, you do not go into more complex calculations).
But the schedule is distorted!
Even if you are good at estimating the time to complete a task, this does not mean that you will be good at estimating the time to complete the project! It’s counterintuitive, but you can be more wrong.
Anyone reading the article for nerdy mathematicians (and data scientist / statisticians) should already have recognized the normal distribution skewed to the right in the tiny graph from the previous meme. Let’s enlarge it and explain what it means:
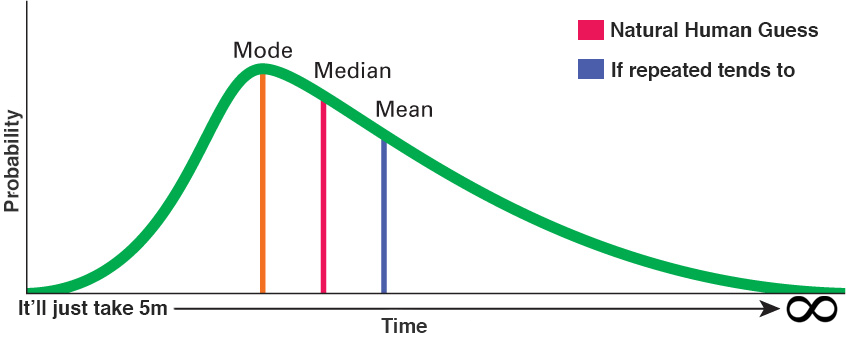
For this particular problem, the median still has a higher probability than the mean! If you try to guess the value of the mode (mode), which has the highest probability, then as the volume of the problem increases, you will be even more mistaken.
See what can go wrong here? Our “natural” guess is based on median, maximizing the probability of a correct guess, however, the real number, when performing the “event”, a sufficient number of times will always tend to average… In other words: the more similar tasks you perform, the more this error accumulates!
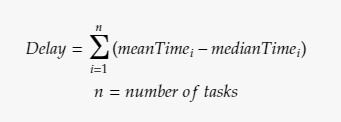
The delay equation based on this hypothesis
Programming tasks in a project are usually quite similar to each other, or at least grouped into several similar clusters! This equation also implies that this problem is scalable! While we want everything in software projects to be scalable, problems are clearly not welcome.
How can we use this knowledge?
To be honest, in the process of writing this article, I did not plan to give “recommendations” based on this hypothesis. It was supposed to be simply an explanatory analysis, culminating in a hypothesis, which the reader must interpret at his own will.
However, I understand that many will be disappointed with such incompleteness, so I will tell you what I personally learned from this.
- It is easier to say whether task X will take more / less / the same amount of time as task Y than to determine exactly how long they will take to complete. This happens because if the skewness of the curves is approximately the same (which is true for similar problems), then comparing the medians gives about the same results as comparing the means.
- I don’t memorize or write down every single problem in order to calculate and get the average (and I cannot find any data for such experiments). Therefore, I usually rate the inevitable error (mean-median) as a percentage of the time per task that increases / decreases depending on how familiar I am with the development environment. (Do I like this language / framework (40%) Do I have good debugging tools? (30%) Is the IDE support good? (25%)… etc.).
- I started dividing sprints into tasks of equal size to provide some consistency in the timing process. This allows me to use point 1. It can be easy to determine that two tasks are approximately equal in time. In addition, it makes the problems even more similar to what the hypothesis applies to, and everything becomes more predictable.
- By applying these principles, if resources are available, a “test run” can be organized. For example, if in X1 days Y1 developers completed Z1 homogeneous tasks, then we can calculate X2 (days), knowing Y2 (the number of developers available) and Z2 (the total number of remaining tasks).
Advertising
Epic servers for developers and more! Inexpensive VDS based on the latest AMD EPYC and NVMe processors, storage for hosting projects of any complexity, from corporate networks and gaming projects to landing pages and VPNs.