Why do you need other people’s mistakes? We fix vulnerabilities in third-party libraries

What is SCA as a process? The application source code or, in some cases, executable code is supplied as input, after which SCA determines which third-party libraries are used in the application. In the future, this information is used to identify vulnerabilities in the application, and can also be useful for checking the license purity of the library. There are various ways to determine which libraries / frameworks are used:
- If the input is source code, then the surest way is to look at the config files, since in most cases the build system can show all dependencies without the build itself. For example, on mvn dependency: tree, in which dependencies are written, you need to make a list of such files. Also, the necessary dependencies can be created by compiling the necessary files, for example, for Java, such files will be added by building the source code (see examples of files):
- Java / Scala / Kotlin – pom.xml, build.gradle, build.sbt + Manifest
- C # – * .csproj
- PHP – composer.json
- JavaScript – package.json (Node.js)
- Ruby – Gemfile, Gemfile.lock
- Can be identified by package / file names.
- By the hashes of the files, you can understand which libraries and which versions are used.
- You can also use special tools, for example, OWASP dependency check, to post-process the results. For example, to independently search for vulnerabilities in components that have been identified by similar means.
Sources of information for SCA
Sources of information will vary depending on the risks that are analyzed by the SCA. They can be divided into three types:
- security risks (Security Risk), that is, searching for vulnerabilities in third-party components;
- risks of using outdated software (Obsolescence risk);
- license risks (License Risk), that is, the legality of using third-party components due to licensing policy…
In our case, we are talking about security risks, for which vulnerability databases are used as sources of information. Below are a couple of examples of such databases:
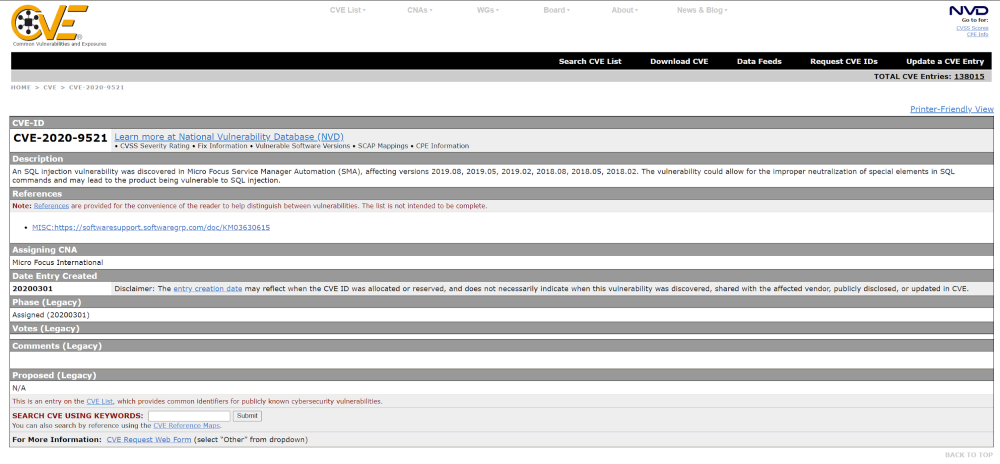
- CVE – the main source of information about vulnerabilities in specific versions of the product, the most complete of the free databases with vulnerabilities, the rest rely on it (see screenshot):
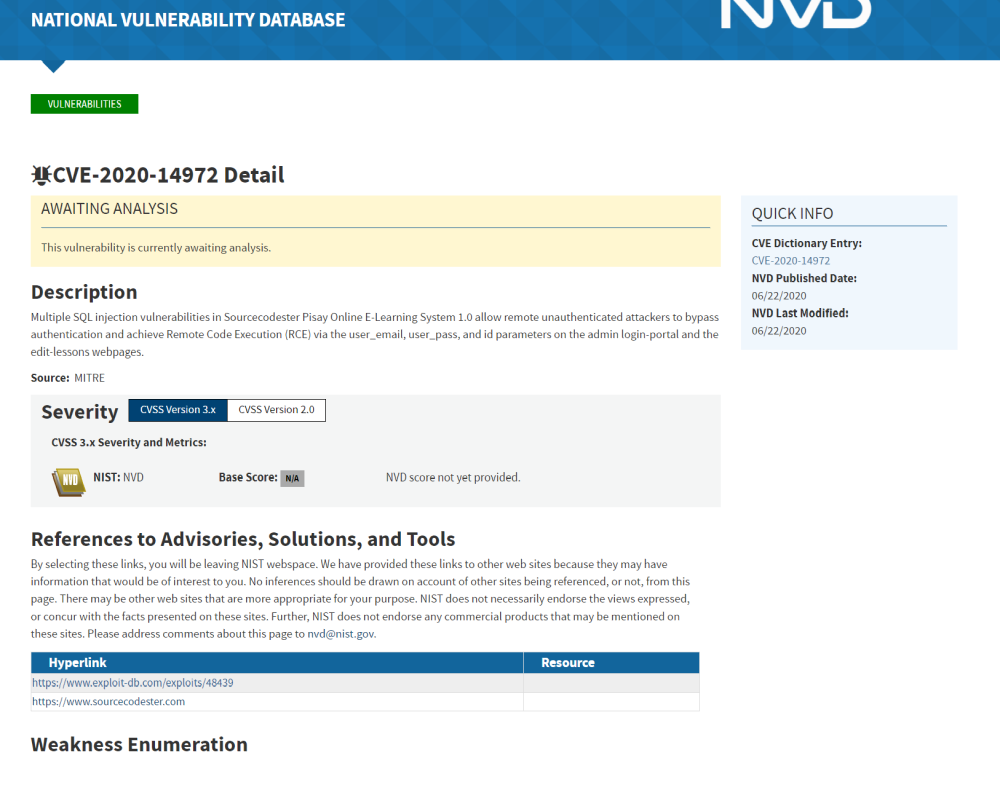
- NVD – National Vulnerability Database of the United States, based on CVE, for many vulnerabilities the CVSS (Common Vulnerability Scoring System) scores are 3.0 and 2.0, which can be useful for understanding the criticality of the entry. Example:
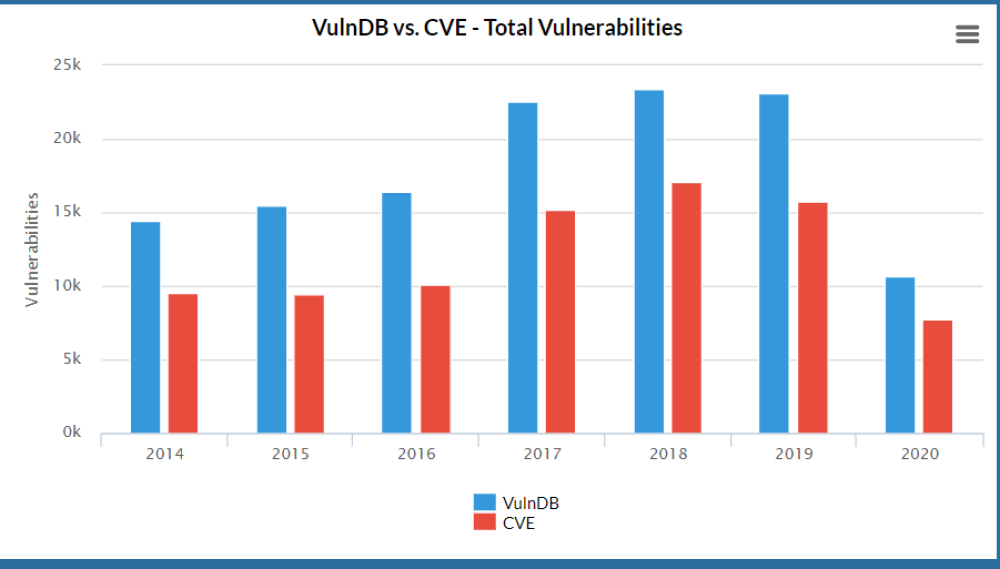
- VulnDB – a paid database that contains more complete information on vulnerabilities than CVE.
An example of how an SCA tool works
After downloading a project, for example, a git repository, its components are analyzed. It should be noted that each programming language may have its own requirements for analysis. For example, for Java, you need the project to be correctly built by the basic commands of the Maven tool, or you can transfer an already assembled project for analysis. First of all, the safety of the project is assessed, followed by an assessment of the licensing purity, that is, how legitimately one or another third-party library is used. As an example, let us consider the results of an analysis carried out using a WhiteSource product, since the report presented by it and its visualization most clearly demonstrates the capabilities of SCA tools.
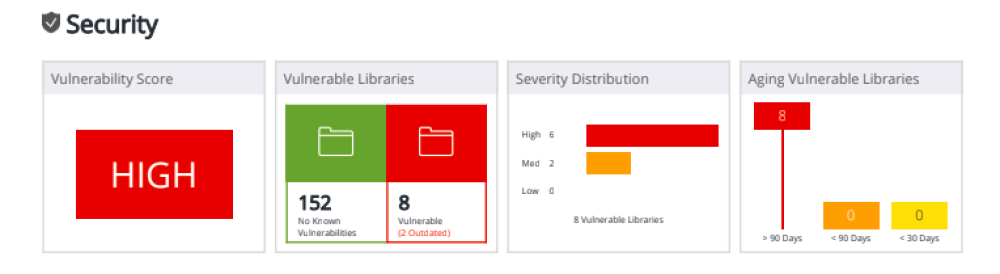

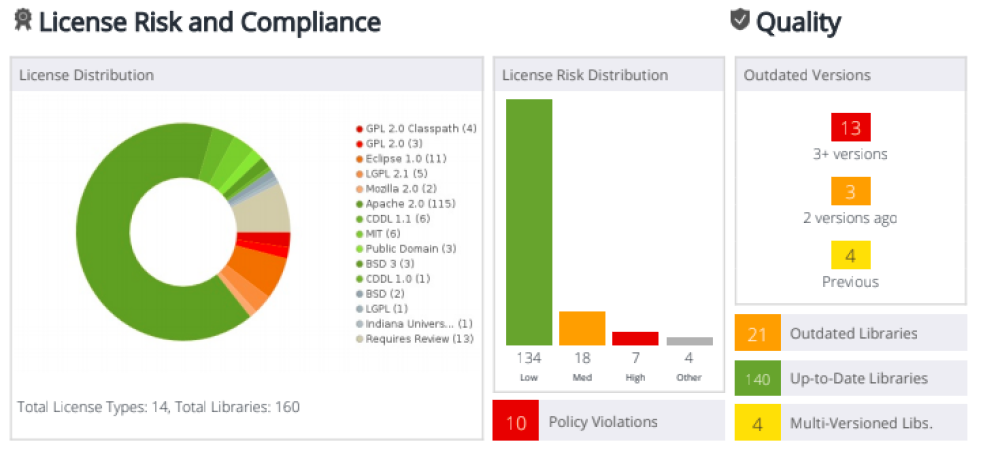
This product works according to the 3rd method of determining the libraries / frameworks used – determination by hash sum: the hash sum of the library is compared with various hash sums from the vendor’s database. As you can see in the screenshots above, indeed, the SCA tool can find problematic libraries and tell you what to do with them. It is often enough to simply patch them to a safe version. But is it really that simple?

There are several nuances:
- You can use a developed or modified component (library / framework), which is simply not in the vendor’s database, but you need to check it. For example, a .jar library, without which some module of your web application does not work.
- You can also use a highly specialized version of the library, which cannot be upgraded to secure without affecting your application.
- Or a library is used in some specialized programming language, for example, Solidity, for which there is simply no entry in the vendor’s database, as well as support for the analysis of such libraries in general.
- There may be a problem with the completeness of the SCA tool database for your project type. Basically, vendors of these systems use their own library search databases, so there may not be such libraries in the vendor’s database for your project stack.
These are quite common cases that you need to work with. In addition, problems may appear with the assembly of some of the system components or the correct configuration of the SCA tool to obtain full results. But such difficulties are no longer associated with the technology for analyzing third-party components in general, but rather with the solution of a specific vendor.
What to do with the nuances?
Static analysis tools are well suited for dealing with nuances: they can be used to analyze, for example, a .jar file that is not in the database, and eliminate vulnerabilities at the source code level. And if there is the source code of the component being developed, then the task becomes even easier.
Let’s take a closer look at the use cases of SAST tools to solve such problems.
The easiest option is when the source code of the library is. In this case, to analyze the code for vulnerabilities, you just need to load it into a static analyzer as an archive with the code.
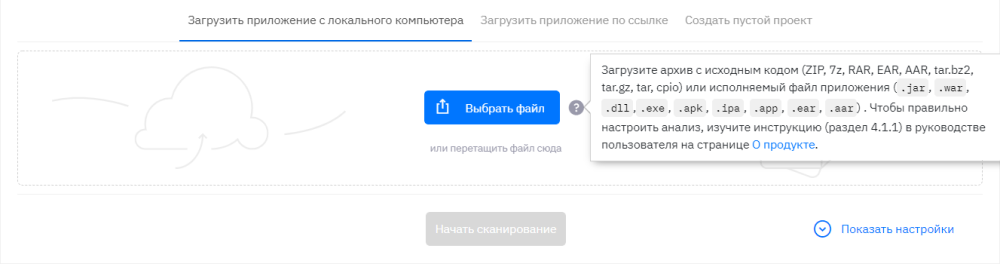
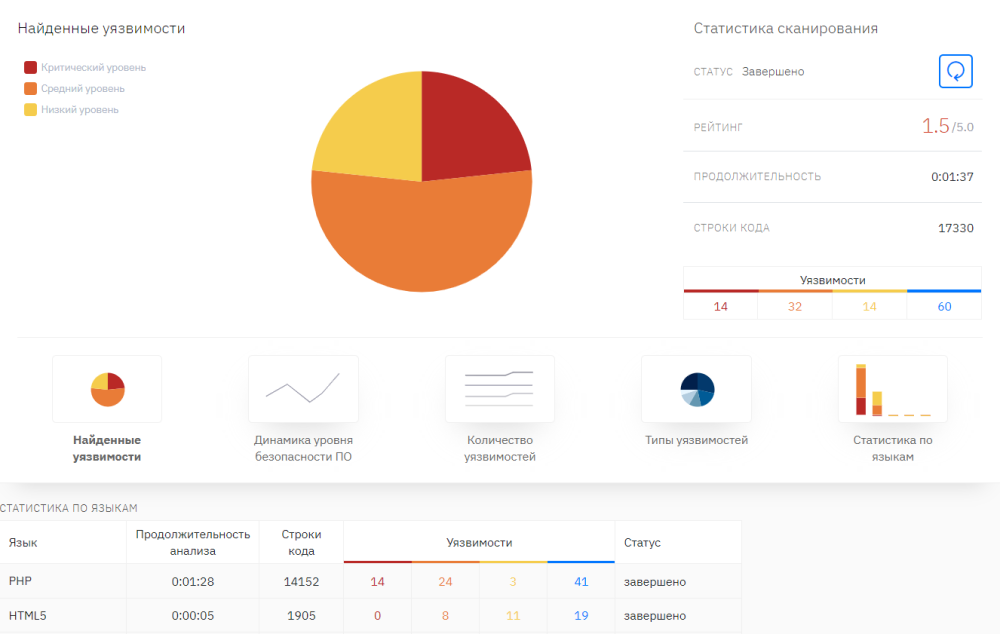
Ok, we’ve got the results of the static analyzer, what should I do next? In an ideal situation, you should look at all vulnerabilities and assess their real criticality in the context of your application, since the static analyzer may not fully understand the logic of your application.
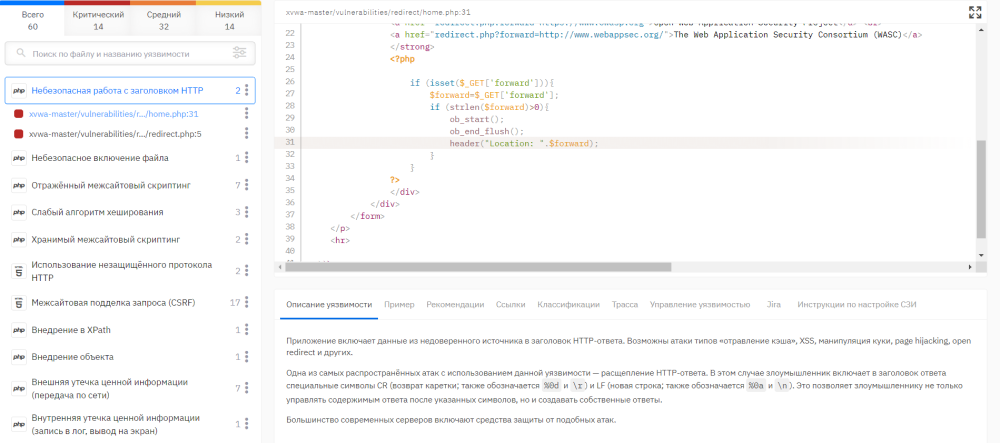
But to be realistic, then you don’t want to rewrite someone else’s library, spending a lot of resources on it (which are not there anyway). In this case, we recommend trying to close at least critical vulnerabilities. The static analyzer clearly shows where exactly the vulnerability is contained in the code and provides a detailed description of it with recommendations for elimination, which greatly simplifies such work.
Let’s also consider a more complicated option, when there is, for example, a .jar file for which the SCA tool could not find any information. In fact, this is a fairly common case when one of the components is not identified – this happens in 6 out of 10 scans. How, then, can you be sure of the safety of using the borrowed component?
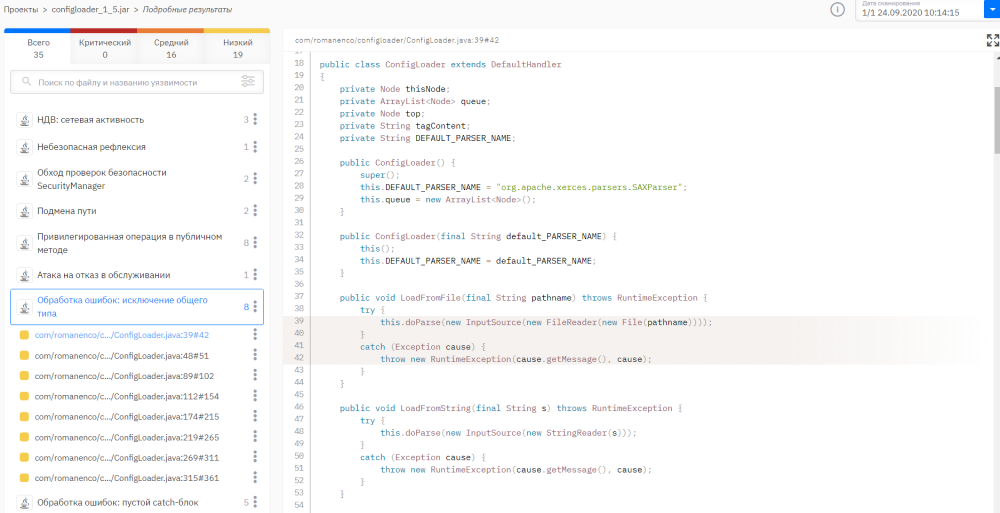
SCA clearly shows what file could not be checked – then it can be done using a static analyzer.
For a bytecode analyst, it is important to map vulnerabilities and NDVs to source code. To do this, at the final stage of static binary analysis, the process of decompiling the bytecode into the original one is started. That is, vulnerabilities can be demonstrated in decompiled code. The question immediately arises – is the decompiled code sufficient to understand and localize the vulnerability?
The decompilation quality for bytecode is great. You can almost always figure out what the vulnerability is, we wrote about this in more detail in one of our previous articles. After that, the same sequence of actions is repeated as after the analysis of the source code.
In addition to advantages, these approaches have their disadvantages. With static analysis, there is a possibility of getting false positives (when the identified vulnerability is not real). Or in the process of decompilation, for example, even if we decompile the JVM bytecode, some of the information may not be restored correctly, so the analysis itself takes place on a representation close to a binary code. Accordingly, the question arises: how, when finding vulnerabilities in the binary code, localize them in the source?
But all these questions, in fact, can be solved: there are also special modules and filters for filtering false positives. We described the solution to the problem for the JVM bytecode in the article on searching for vulnerabilities in Java bytecode.
In addition, manual review can be another alternative, since the SCA tool may not be completely sure about some heuristic results. In such a case, an expert is involved who evaluates the changes made in the library and offers recommendations for corrections, taking into account the latest version of the original library. The approach is quite laborious, since manually dealing with this will in some cases be a non-trivial task, and can also be costly if an expert from a third-party organization is involved. However, given the budget, this option can work well.
Summing up, I would like to note: SCA tools will partly help avoid headaches with third-party and native libraries, but they are recommended to be used in combination with static analysis tools for really high-quality elimination of vulnerabilities in applications. Moreover, these solutions must constantly participate in the development, for this they should be implemented in the process of secure development. This will allow for validation at various stages of the software lifecycle (as discussed in our series on implementing SAST for secure development). This way you can get the most out of these tools.
Posted by Anton Prokofiev, Lead Analyst at Solar appScreener





