volatile vs. volatile
A tale of two seemingly similar, but still different tools
Herb is a bestselling author and software development consultant, as well as a software architect at Microsoft. You can contact him at www.gotw.ca.
What does the keyword mean? volatile? How should i use it? To everyone’s confusion, there are two common answers, because depending on the language in which you write the code, volatile refers to one of two different programming techniques: lock-free programming (no locks) and working with “unusual” memory. (See Figure 1.)
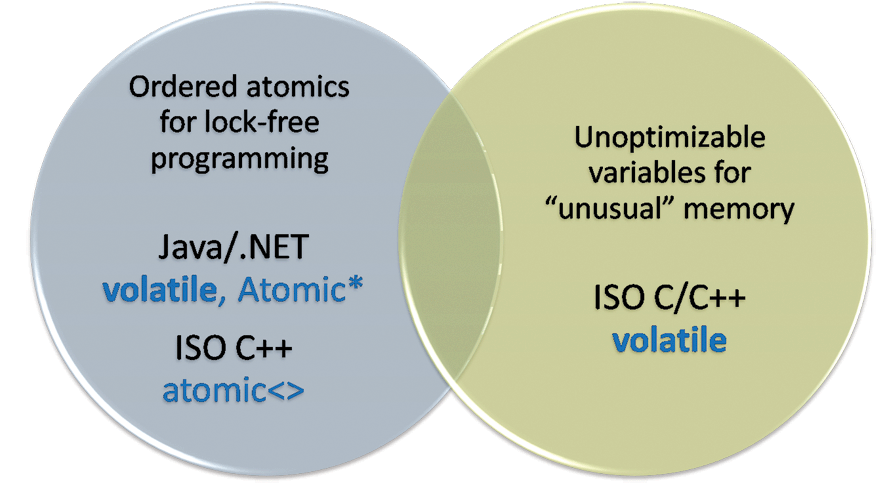
Figure 1: A tale of two technical requirements.
The confusion is further aggravated by the fact that these two different use cases have overlapping prerequisites and imposed restrictions, which makes them look more similar than they really are. Let’s clearly define and understand them, and figure out how to use them correctly in C, C ++, Java, and C # – and is it always how volatile.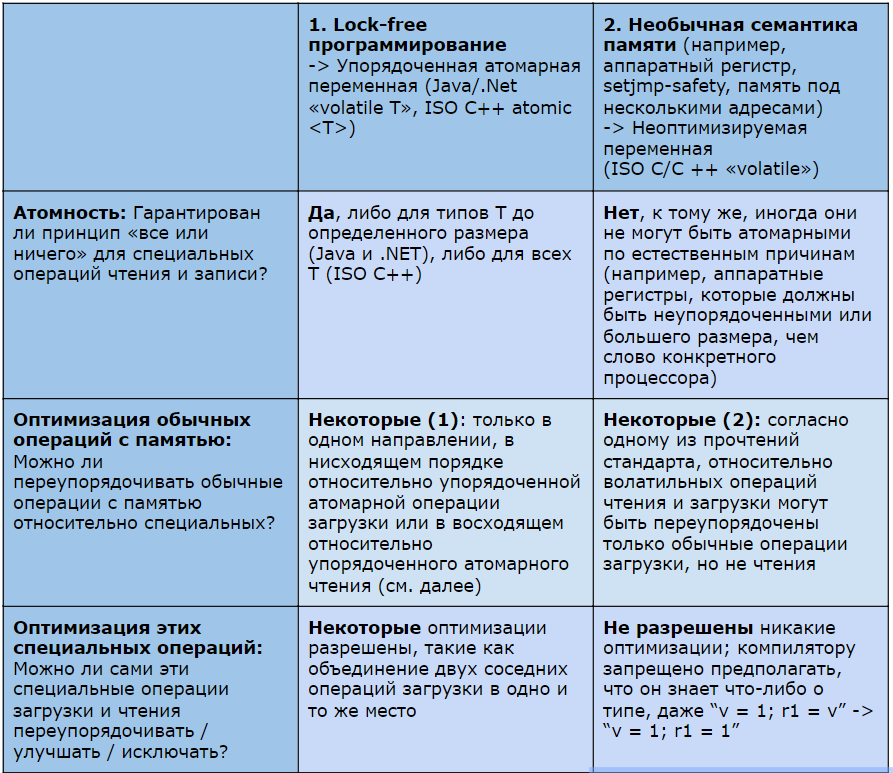
Table 1: Comparison of overlapping but different premises.
Case 1: Ordered atomic variables for lock-free programming
Lock-free programming involves establishing communication and synchronization between threads using tools of a lower level than mutually exclusive locks. Both in the past and today there is a wide range of such tools. In a crude historical order, they include explicit fences / barriers – for example, mb () on Linux), special ordering API calls (e.g. Interlockedexchange on Windows) and various varieties of special atomic types. Many of these tools are dreary and / or complex, and their wide variety means that in the end, lock-free code is written differently in different environments.
However, over the past few years, there has been significant convergence between hardware and software providers: the computing industry is uniting around sequentially agreed ordered atomic variables as a standard or the only way to write lock-free code using the main OS languages and platforms. In a nutshell, ordered atomic variables are safe to read and write in multiple threads simultaneously without any explicit locks, since they provide two guarantees: their reading and writing are guaranteed to be executed in the order in which they appear in the source code of your program; and every reading or writing is guaranteed to be atomic, “all or nothing.” They also have special operations such as compareAndSetwhich are guaranteed to be atomically executed. Cm. [1] for more information on ordered atomic variables and how to use them correctly.
Ordered atomic variables are available in Java, C # and other .NET languages, as well as in the upcoming ISO C ++ standard, but with different names:
- Java provides ordered atomic variables under the keyword volatile (eg, volatile int), fully supporting this with Java 5 (2004). Java additionally provides several named types in java.util.concurrent.atomic, eg, AtomicLongArraywhich you can use for the same purpose.
- .NET added them in Visual Studio 2005, also under the volatile keyword (e.g. volatile int) They are suitable for almost any use case of lock-free code, with the exception of rare examples like the Dekker algorithm. .NET fixes the remaining bugs in Visual Studio 2010, which is in beta testing at the time of this writing.
- ISO C ++ added them to the draft C ++ 0x standard in 2007 under the template name atomic
>
A few words about optimization
We’ll look at how ordered atomic variables limit the optimization that compilers, processors, caching effects, and other elements of your runtime can perform. So, let's first take a quick look at some basic optimization rules.
The fundamental rule of optimization in almost all languages is this: optimizations that reorder ("transform") the execution of your code are always legitimate only if they do not change the meaning of the program, so that the program cannot determine the difference between the execution of the source code and the converted one. In some languages, this is also known as the “as-if” rule, which gets its name due to the fact that the converted code has the same observable effects, “as if” (as if) the source code was executed in the form in which it was originally written.
This rule has a twofold effect: firstly, optimization should never allow you to get a result that was previously impossible, or to violate any guarantees that the source code was allowed to rely on, including language semantics. If we give an impossible result, in the end, the program and the user will certainly be able to notice the difference, and this is no longer “as if” we have executed the original non-converted code.
Secondly, optimization allowed to reduce the set of possible executions. For example, optimization can lead to the fact that some potential (but not guaranteed) alternations (changing the order of execution of instructions - interleaving) will never occur. This is normal, because the program still cannot rely on them to happen.
Ordered atomic variables and optimization
Using ordered atomic variables limits the kinds of optimizations your compiler, processor, and caching system can do. [3] Two types of optimizations are worth noting:
- Optimization of ordered atomic read and write operations.
- Optimization of adjacent normal read and write operations.
Firstly, all ordered atomic read and write operations in a given stream must be performed strictly in the order of the source code, because this is one of the fundamental guarantees of ordered atomic variables. Nevertheless, we can still perform some optimizations, in particular, optimizations that have the same effect as if this thread simply always performed so fast that at some points there would be no alternation with another thread.
For example, consider this code, where a is an ordered atomic variable:
a = 1; // A
a = 2; // BIs it permissible for the compiler, processor, cache, or other part of the runtime to convert the above code to the following, excluding the redundant entry in line A?
// A ': OK: полностью исключить строку A
a = 2; // B
The answer is yes. This is legitimate because the program cannot determine the difference; it is “as if” this thread has always worked so fast that no other thread running in parallel can, in principle, alternate between lines A and B to see an intermediate value. [4]
Similarly, if a Is an ordered atomic variable, and local - an indivisible local variable, it is permissible to convert
a = 1; // C: запись в a
local = a; // D: чтение из ain
a = 1; // C: запись в a
local = 1; // D': OK, применить "подстановку константы"which excludes reading from a. Even if another thread is simultaneously trying to write to a, it's “as if” this thread always ran so fast that another thread never managed to rotate the lines C and Dto change the value before we can write our own back to local.
Secondly, nearby ordinary read and write operations can still be reordered around ordered atomic ones, but with some limitations. In particular, as described in [3], ordinary read and write operations cannot move up with respect to ordered atomic reading (from “after” to “before”) and cannot move down with respect to ordered atomic reading (from “before” to “after”). In short, this can get them out of the critical section of code, and you can write programs that benefit from this in performance. For more information, see [3].
That's all for lock-free programming and ordered atomic variables. What about another case in which some kind of “volatile” addresses are considered?
Case 2: Semantics-free variables for memory with “unusual” semantics
- The second need is to work with “unusual” memory, which goes beyond the memory model of this language, where the compiler must assume that the variable can change the value at any time and / or that reading and writing can have unrecognizable semantics and consequences. Classic examples:
- Hardware registers, part 1: Asynchronous changes. For example, consider a memory cell M on a user board that is connected to a device that records directly to M. Unlike ordinary memory, which is changed only by the program itself, the value stored in M, can change at any time, even if no program thread writes to it; therefore, the compiler cannot make any assumptions that the value will be stable.
- Hardware Registers, Part 2: Semantics. For example, consider a memory area M on the user board, where writing to this position always automatically increases by one. Unlike the usual place in RAM memory, the compiler cannot even assume that writing to M and the reading immediately after it from M be sure to read the same value that was recorded.
- A memory with more than one address. If this memory location is accessible using two different addresses A1 and A2, the compiler or processor may not know that writing to a cell A1 can change the value in the cell A2. Any optimization suggesting? what's the record in A1does not change the value A2will break the program, and should be prevented.
Variables in such memory locations are non-optimizable variablesbecause the compiler cannot safely make any assumptions about them at all. In other words, the compiler needs to say that such a variable is not involved in the usual type system, even if it has a specific type. For example, if a memory location M or A1 / A2 in the above examples, the program is declared as "int", What does this really mean? The most that this can mean is that it has size and location intbut this cannot mean that he behaves like int - eventually, int Do not auto-increment yourself when you write to it, or do not mysteriously change its value when you write to something similar to another variable at a different address.
We need a way to disable all optimizations for reading and writing them. ISO C and C ++ have a portable, standard way of telling the compiler that it is such a special variable that it should not optimize: volatile.
Java and .NET do not have a comparable concept. After all, managed environments must know the full semantics of the program that they run, so it is not surprising that they do not support memory with “unknowable” semantics. But both Java and .NET provide emergency gateways to exit the managed environment and invoke native code: Java provides the Java Native Interface (JNI), and .NET provides the Platform Invoke (P / Invoke). However, in the JNI specification [5] about volatile nothing is said and no Java is mentioned at all volatilenor C / C ++ volatile; similarly, the P / Invoke documentation does not mention .NET interaction volatile or C / C ++ volatile. Thus, for proper access to the non-optimizable memory area in Java or .NET, you must write C / C ++ functions that use C / C ++ volatile to do the necessary work on behalf of the calling code, so that they completely encapsulate and hide volatile memory (i.e., did not receive or return anything volatile) and call these functions through JNI and P / Invoke.
Non-optimizable variables and (non) optimization
All read and write operations of non-optimizable variables in a given stream should be performed exactly as written; no optimizations are allowed at all, because the compiler cannot know the full semantics of the variable and when and how its value can change. These are more stringent expressions (compared to ordered atomic variables) that need to be executed only in the order of the source code.
Consider again the two transformations that we examined earlier, but this time replace the ordered atomic variable a to a non-optimizable (C / C ++ volatile) variable v:
v = 1; // A
v = 2; // BIs it legitimate to convert as follows in order to remove a clearly redundant entry in a string A?
// A ': невалидно, нельзя исключить запись
v = 2; // B
The answer is no, because the compiler cannot know that the exception is writing a string A in v will not change the meaning of the program. For example, v may be the location that the user equipment is accessing that expects to see a value of 1 before a value of 2 and otherwise will not work correctly.
Similarly, if v non-optimizable variable, and local is an indivisible local variable, conversion is not allowed
v = 1; // C: запись в v
local = v; // C: чтение из vin
a = 1; // C: запись в v
local = l; // D': невалидно, нельзя совершить
// "подстановку константы"to abolish reading from v. For example, v can be a hardware address that automatically increments every time you write, so writing 1 will give a value of 2 the next time you read it.
Secondly, what about neighboring regular read and write operations - can they be reordered around non-optimizable ones? Today there is no practical portable answer, because the implementations of the C / C ++ compiler are very different and it is unlikely that they will soon begin to move towards uniformity. For example, one interpretation of the C ++ Standard states that normal read operations can move freely in any direction relative to reading or writing volatile C / C ++, but a regular record cannot move at all relative to reading or writing volatile C / C ++ - what makes volatile C / C ++ is at the same time less and more restrictive than ordered atomic operations. Some compiler providers support this interpretation; others do not optimize reading or writing at all volatile; and still others have their own semantics.
Summary
To write secure lock-free code that communicates between threads without using locks, prefer to use ordered atomic variables: Java / .NET volatile, C ++0x atomic>
To safely exchange data with special equipment or other memory with unusual semantics, use non-optimizable variables: ISO C / C ++ volatile. Remember that reading and writing these variables does not have to be atomic.
And finally, in order to declare a variable that has unusual semantics and has any or all of the atomicity and / or ordering guarantees necessary for writing lock-free code, only a draft of the ISO C ++ 0x standard provides a direct way to implement it: volatile atomic >
- G. Sutter. Writing Lock-Free Code: A Corrected Queue (DDJ, October 2008). Available online here.
- [2] Cm. www.boost.org.
- [3] G. Sutter. “Apply Critical Sections Consistently” (DDJ, November 2007). Available online here.
- [4] There is a common objection: “In the source code, another thread could see an intermediate value, but this is not possible in the converted code. Isn't that a change in observed behavior? ” the answer is “No,” because the program was never guaranteed that it would actually alternate just in time to see this value; there was already a legitimate result for this stream - it always worked so fast that alternation never happened. Again, what follows from this optimization is that it reduces the set of possible executions, which is always legitimate.
- [5] S. Lyang. Java Native Interface: Programmer's Guide and Specification. (Prentice Hall, 1999). Available online here.
Free webinar: “Hello, World!” in Farsi or how to use Unicode in C ++ "





