The perfect pipeline in a vacuum

In interviews for a position that involves understanding DevOps, I like to ask candidates this question (and sometimes they also ask me):
What do you think the ideal pipeline from commit to production should be? / Describe the ideal CI / CD / etc
Today I want to tell you about my vision of an ideal pipeline. The material is aimed at people with experience in building CI / CD or seeking to get it.
Why is it important?
-
The good thing about the ideal pipeline is that it doesn’t contain a precise answer.
-
The candidate begins to reason, and it is the ability to think that is valued in cool specialists.
-
When such an absolute adjective as “ideal” is added to the question, we immediately untie the hands of the candidates in the open space for creativity and imagination. Applicants have the opportunity to show what improvements they see (or not see) in the current job, and what they would like to add themselves. We can also find out if our prospective colleague has a motivation to improve processes, because the concept “works – don’t touch” is not about the dynamic world of DevOps.
-
Organizational check. Allows you to find out how wide the applicant’s picture of the world is. Conventionally: from creating a task in Jira to setting up a node in production. Here you can also add an understanding of gitflow, gitlabFlow, githubFlow strategies.
So, before proceeding to the construction of any CI process, it is necessary to decide what steps are available to us?
What can you do in CI?
-
scan the code;
-
build code;
-
test the code;
-
deploy the application;
-
test the application;
-
do Merge;
-
ask other people to approve MR through code review.
Let’s take a closer look at each item.
Code scanning
At this stage, the main idea is that nobody can be trusted.
Even if Vasya is a Senior / Lead Backend Developer. Despite the fact that Vasya is a good person / friend / comrade and godfather. The human factor is still the human factor.
You need to scan the code for:
-
compliance with the general guidelines;
-
vulnerabilities;
-
quality.

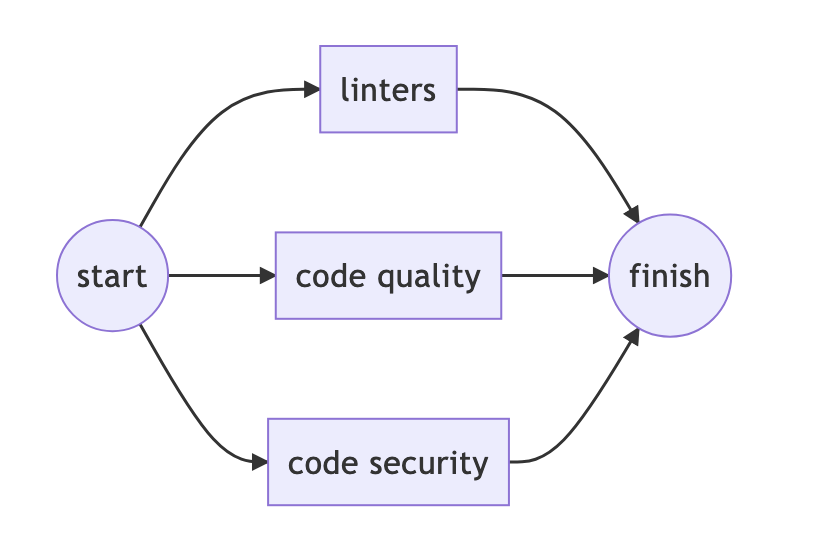
Tasks at this stage should be performed in parallel.
And trigger only if the source files change, or only if there was an event git push…
Example for gitlab-ci
stages:
- code-scanning
.code-scanning:
only: [pushes]
stage: code-scanning
Linters
Linters are a wonderful thing! Many articles have already been written about them. More details can be found in the material “A holy story about linters”.
Linters’ most important task is bring code to consistency…
After implementing this trick, the developers will start to love you. Because they will finally begin to understand each other. Or hate, deciding that you stick im spokes in the wheels linters in CI. It already depends on your soft skills, culture and knowledge sharing…
Instruments
|
Tool |
Features of the |
|---|---|
|
eslint |
JavaScript |
|
pylint |
Python |
|
golint |
Golang |
|
hadolint |
Dockerfile |
|
kubeval |
Kubernetes manifest |
|
shellcheck |
Bash |
|
gixy |
nginx config |
|
etc |
Code quality
code quality – these tools can be both advanced linters and those that combine all sorts of ML-models to find weaknesses in the code: memory leaks, unsafe methods, dependency vulnerabilities, etc. code security competence.
Instruments
|
Tool |
Features of the |
Price |
|---|---|---|
|
Finding bugs and weaknesses in the code |
From € 120 |
|
|
Github native, search for CVE vulnerabilities |
OpenSource – free |
|
|
etc |
Code Security
But there are also separate tools, sharpened only for code security… They are designed to:
-
Fight password / key / certificate leak.
-
Scan for known vulnerabilities.
It doesn’t matter how big the company is, the people in it are the same. If a developer “goes” to production through a certificate, then for his convenience the developer will add it to
git… Therefore, it will take time to explain that the certificate should be stored invault, not ingit
Instruments
|
Tool |
Features of the |
Price |
|---|---|---|
|
Used in Gitlab Security, it can scan the interval from commit “A” to commit “B”. |
Free |
|
|
We recently launched the Enterpise Edition. |
From $ 336 |
|
|
etc |
The Vulnerability Scanner must be run regularly, as new vulnerabilities tend to be SUDDENLY discovered over time.

Code Coverage
And of course, after testing, you need to find out code coverage…
Percent source code program that was executed during testing.
Instruments
|
Tool |
Features of the |
Price |
|---|---|---|
|
For Golang. Already built into Golang. |
Free |
|
|
Powered by jcoverage. Java world |
Free |
|
|
Good old classics |
Free up to 5 users |
|
|
etc |
Unit test
Unit tests tend to spill over into tools code qualitywho are good at unit tests.
Instruments
|
Tool |
Features of the |
|---|---|
|
PHP (My mom says I am special) |
|
|
Java (many tools support junit output) |
|
|
etc |
Build
Stage for building artifacts / packages / images etc. Here you can already think about what the strategy for versioning the entire application will be.
For the versioning model, you can choose:
In the days of containerization, images for containers and how to version them are primarily of interest.
Tools for assembling images
|
Tool |
Features of the |
|---|---|
|
docker build |
Almost everyone knows only this. |
|
The Moby project has provided its implementation. Supplied with docker, included by option |
|
|
A tool from Google that allows you to collect in a userspace, that is, without a docker daemon. |
|
|
Developed by colleagues from Flant. Inside stapel. All-in-one: can not only build, but also deploy. |
|
|
Open Container Initiative, Podman. |
|
|
etc |
So, the assembly was successful – let’s move on.
Scan package
The package / image was assembled. Now you need to scan it for vulnerabilities. Modern registries already contain tools for this.
Instruments
|
Tool |
Features of the |
Price |
|---|---|---|
|
Docker Registry, ChartMuseum, Robot-users. |
Free |
|
|
There is everything, including Docker. |
Free and pro |
|
|
Harvester, which is not there. |
Free and pro |
|
|
etc |
Deploy
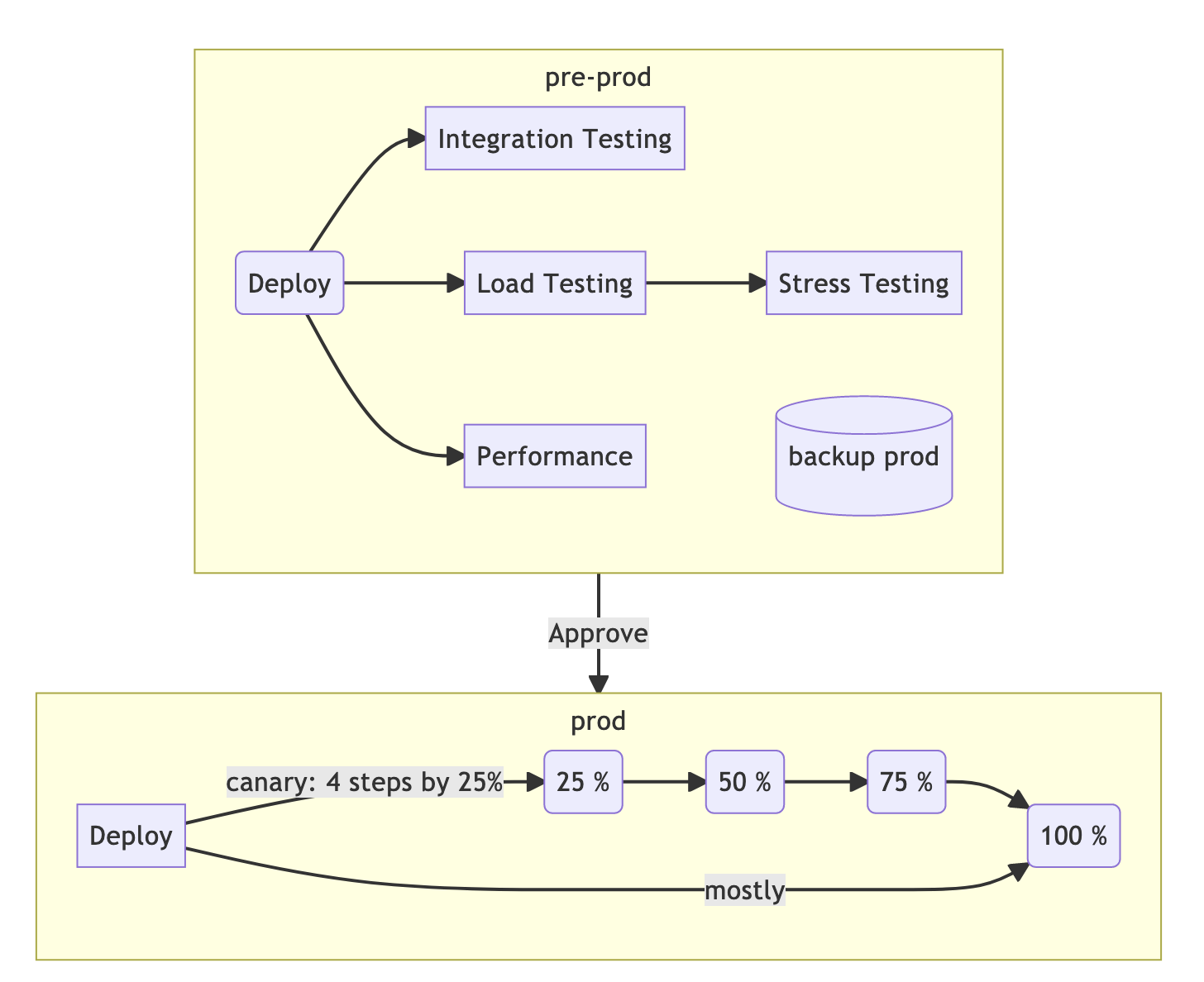
The stage for deploying the application in different environments.

We will deploy the container as soon as we can.
Not all environments go well with strategies deployment…
-
rolling – classic;
-
recreate – anything you like, but not production;
-
blue / green – in 90% of cases, this method is applicable only to production environments;
-
canary – in 99% of cases this method is applicable only to production environments.
Stateful
We must also remember that even with the same code in stage and production, production can fall apart precisely because they have different statefuls. Migrations can go well on an empty base, but when they appear on sale, they break green circles / checkmarks in the pipeline. Therefore, for stage / pre-production, an impersonal backup of the main base should be provided.
And don’t forget to come up with a way to rollback your releases to the latest / specific release.
Instruments
|
Tool |
Features of the |
|---|---|
|
Docker-compose for helm. Our development. |
|
|
We collect dimples in one place. |
|
|
“Club of fans to tickle GitOps”. |
|
|
It was higher. |
|
|
For those who like to invent templating themselves. |
|
|
etc |
As an advertisement I will say that helmwav‘I really miss your stars on GitHub. The first post about helmwave.
Integration testing
The application has been deployed or. It lives somewhere in a separate circuit. The stage begins integration testing… Testing can be either manual or automated. Automated tests can be built into the pipeline.
Instruments
|
Tool |
Features of the |
|---|---|
|
Can be run in kubera. |
|
|
Trouble with images. Requires Docker-in-Docker. |
|
|
etc |
Performance testing (load / stress testing)
It makes sense to carry out this type of testing on stage / pre-production environments. Provided that the resource capacities on it are the same as in production.
Tools to give the load
|
Tool |
Features of the |
|---|---|
|
wrk |
Great hammer. But do not try to nail them everything. |
|
Stylishly fashionable JavaScript! Used in AutoDevOps… |
|
|
Artillery.io |
JS again. Comparison with k6 |
|
OldSchool. |
|
|
Stop bothering the competitors. |
|
|
etc |
Tools to evaluate the performance of the service
|
Tool |
Features of the |
|---|---|
|
sitespeed.io |
Inside: coach, browserTime, compare, PageXray. |
|
Tools from Google. Nice, you can show it to your manager. He will be delighted. It’s a pity the dogs don’t dance. |
|
|
etc |
Code Review / Approved
One of the most important stages is the Merge Request. It is in them that individual actions in the pipeline can be performed before the merger, as well as assigned group persons requiring approval before the merger.
List of commands / roles:
-
QA;
-
Security;
-
Tech leads;
-
Release managers;
-
Maintainers;
-
DevOps;
-
etc.
Obviously, it is not necessary to convene the entire consultation before each MR, each team must appear at its own specific moment MR:
-
it makes sense to call security guards only before merging into production;
-
QA before release branches;
-
DevOps should be disturbed only if their competence is affected: changes in helm-charts / pipeline / server configuration / etc.
Developing flow
More often than not, every company, or even every project in a company, decides to invent its own flow bike. Which after a few iterations comes to something that might resemble gitflow, gitlabFlow, githubFlow, or all at once.
This is neither good nor bad – this is the specifics of the project. There are opinions that gitflow is not a cake. GithubFlow for relatively small teams. And about gitlabFlow, I have nothing to add, but there is an observation that products do not like it very much – for the fact that it is impossible to track feature branches.
In short, then:
-
Gitflow: feature -> develop -> release-vX.XX -> master (aka main) ->
tag; -
GitHubFlow: branch -> master (aka main);
-
GitLabFlow: environmental branches.
TL; DR
General concept

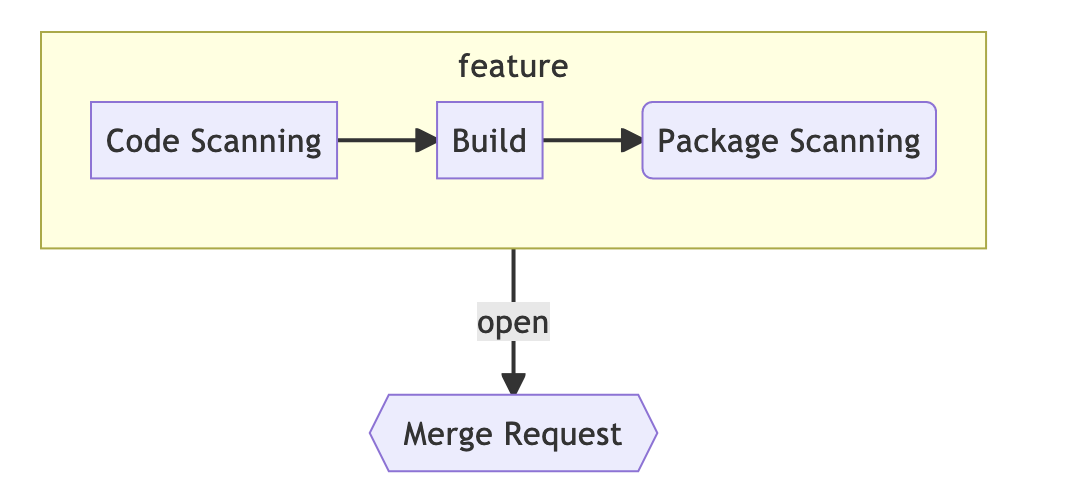
Feature branch
Pre-Production -> Production
Conclusion
If I misspelled something, missed an important detail, or, in your opinion, the pipeline is not perfect enough, write to me about it – I’ll make an update.
The developer created a branch and pushed the code into it. What’s next?
Leave options for your scenarios in the comments.





