Text sentiment analysis using the Lightautoml framework

Sentiment analysis (sentiment analysis) is a field of computational linguistics that deals with the study of emotions in text documents, based on machine learning.
In this article, I will show how we used the company’s internal development for these purposes – the LightAutoML framework, which has everything to solve the task – pre-trained ready-made vector representations of FastText words and ready-made text presets, in which you only need to specify hyperparameters.
Task
If difficulties arise in working with automated systems, internal customers leave messages of a neutral or negative nature (positive is not taken into account due to the fact that there are very few such requests).
Sentiment analysis of the text will allow you to understand what the user is trying to convey in the appeal – something neutral or negative. We are interested in cases where problems in an automated system are directly described and which require attention and further analysis.

The first step is to download and anonymize the data. Now you can start manually marking calls and forming a dataset, on the basis of which the model will be trained and tested. This dataset included 1500 manually labeled instances. In the future, we added another 2300 samples to the sample from among the calls correctly marked by the model.
Data preprocessing
Let’s preprocess the data using regular expressions, removing extra characters and stop words. In addition, we will normalize words using the pymorphy2 library.
data['text'] = data['text'].replace("[0-9!#()$,'-.*+/:;<=>?@[]^_`{|}"]+", ' ', regex=True)
data['text'] = data['text'].replace(r's+', ' ', regex=True)
data['text'] = data['text'].apply(lambda x: ' '.join([word for word in x.split() if word not in (stop_words)]))
data['text'] = data['text'].apply(lambda x: ' '.join([morph.parse(word)[0]. normal_form for word in x.split()]))
Model description
Next, based on the labeled dataset, we form training (65% of its size) and test (35%, respectively) samples and set hyperparameters for the model. We will use a text preset that was implemented specifically for NLP tasks.
automl = TabularNLPAutoML(task=Task('binary', metric = f1_binary),
timeout=2000,
memory_limit=16,
cpu_limit=4,
text_params={'lang': 'ru'},
general_params={'nested_cv': False,
'use_algos': [['linear_l2', 'lgb']]},
reader_params={'cv': 3, 'random_state': 42}-
task=Task(‘binary’, metric = f1_binary) – as a task, we choose a binary classification and a metric function that calculates the F1-score
-
timeout=2000 – set the time limit for the model to be 2000 seconds
-
memory_limit=16 – designate the amount of allocated RAM
-
cpu_limit=4 – denote the number of allocated nuclei
-
text_params={‘lang’: ‘ru’} – select Russian as text parameters
-
general_params={‘nested_cv’: False – denote that we do not need to perform hyperparameter optimization
-
‘use_algos’: [[‘linear_l2’, ‘lgb’]]} – as the algorithms used, we denote the ridge regression and the LightGBM ensemble
Model training:
The model training code looks like this:
roles = {'target': 'sentiment', 'text': ['review']}
pred = automl.fit_predict(train_data, roles=roles, verbose=3)
print('oof_pred:n{}nShape = {}'.format(pred, pred.shape))
class_result = classification_report(y_true=train_data['sentiment'].values, y_pred=np.where(pred.data[:, 0] >= 0.5, 1, 0), target_names=['Neutral', 'Negative'])
print(class_result)-
roles = {‘target’: ‘sentiment’, ‘text’: [‘review’]} – describe the key and text fields
-
pred = automl.fit_predict(train_data, roles=roles, verbose=3) – we train the model based on the training sample, we pass the affected fields
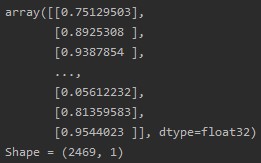
At the output, we have a one-dimensional array that shows the probability of referring the call to a negative class
When training the model, the value of the F1-score metric reached 0.894; accordingly, we can conclude that the model copes well with the task of identifying neutral and negative calls.

Also, one way to evaluate the performance of the model as a whole is by the ROC-AUC curve, which describes the area under the curve (Area Under Curve – Receiver Operating Characteristic).

Explanation of how the model worksAs a confirmation of the above, we can cite the work of the built-in LAMA module – LIME, which reveals the work of the model by coloring words in one color or another, depending on their emotional color. The implementation of this may be presented in the code below:
lime = LimeTextExplainer(automl, feature_selection='lasso', force_order=False)
exp = lime.explain_instance(data.iloc[1013], labels=(0, 1), perturb_column='review')-
lime = LimeTextExplainer(automl, feature_selection=’lasso’, force_order = False) – we call the LIME function and pass our trained model as parameters, as a feature selection algorithm – LASSO (least absolute shrinkage and selection operator – the least absolute shrinkage and selection operator)
-
exp = lime.explain_instance(data.iloc[1013], labels=(0, 1), perturb_ column= ‘review’) – then we pass a random string of our dataset as parameters, denote the class signatures and the affected column
We apply it to a hit that is not contained in the marked-up data and get the following result:


Looking at this example, we see that the model most clearly highlights the words related to the negative – input and error, which signal that there are some problems with the input in this automated system. Now consider an example where words of both classes occur:


We see that the words thank you and please are correctly recognized in the neutral class, the words route signal problems with the connection, which takes a long time, which correctly belongs to the negative class.
What else is the framework capable of
First of all, it is worth highlighting the multiclass classification, the implementation syntax of which is identical to the binary one, but as a task we choose multiclass:
automl = TabularNLPAutoML(task=Task('multiclass', metric = f1_score)
. . .After marking our sample with the third (positive) class and training the model on it, we get the following result:

Where the first column means the probability of a negative color of the appeal, the second – neutral, the third – positive.
The framework can also solve regression analysis tasks, the purpose of which is to determine the relationship between variables and the evaluation of the regression function.
automl = TabularAutoML(task = Task ('reg', loss="rmsle", metric = rmsle_metric, greater_is_better = False)
. . .Work with textLightAutoML has a large number of options for developing a particular model that works with text. The library provides not only obtaining standard features based on TF-IDF, but also based on embeddings: 1) Based on the built-in FastText, which can be trained on a particular corpus 2) Pre-trained Gensim models 3) Any other object that has the form of a dictionary, where on the input is a word, and the output is its embeddings
Among the strategies used for extracting text representations from word embeddings, we can distinguish:
1) Weighted Average Transformer (WAT) – each word is weighed with some weight
TabularNLPAutoML(task = task,
autonlp_params = {'model_name': 'wat',
'transformer_params': {'weight_type': 'idf',
'use_svd': True}}
)2) Bag of Random Embedding Projections (BOREP) – a linear model is built with random weights
TabularNLPAutoML(task = task,
autonlp_params = {'model_name': 'wat',
'transformer_params': {'model_params':
{'proj_size': 300, 'pooling': 'mean',
'max_length': 200, 'init': 'orthogonal',
'pos_encoding': False},
'dataset_params':
{'max_length': 200}}}
)3) Random LSTM – LSTM with random weights
TabularNLPAutoML(task = task,
autonlp_params = {'model_name': 'random_lstm',
'transformer_params': {'model_params':
{'embed_size': 300, 'hidden_size': 256,
'pooling': 'mean', 'num_layers': 1},
'dataset_params':
{'max_length': 200, 'embed_size': 300}}}
)4) Bert Pooling – getting embedding from the last output of the Transformer model
TabularNLPAutoML(task = task,
autonlp_params = {'model_name': 'pooled_bert',
'transformer_params': {'model_params':
{'pooling': 'mean'},
'dataset_params':
{'max_length': 256}}}
)The tokenizer class is responsible for text preprocessing, by default it is used only for TF-IDF.
What is done for the Russian language:
1) ё is replaced by e
2) Punctuation marks, separate numbers are removed
3) Tokenization occurs by space
4) Text is reduced to lowercase
5) Words consisting of one character are deleted
6) Optionally remove stop words
Summing up, it should be said that LightAutoML, thanks to the built-in tools, is able to show quite good results in binary or multiclass classification and regression tasks.
Specifically, in our case, we managed to create a model of sentimental analysis, which with 89% accuracy determines the emotional coloring of the address and the words that have the greatest impact on it.