Static analysis of large volumes of Python code: Instagram experience. Part 1

Our server application is a monolith, which is one large code base consisting of several million lines and including several thousand Django endpoints (here is a talk about using Django on Instagram). All this is loaded and maintained as a single entity. Several services have been allocated from the monolith, but our plan does not include a strong separation of the monolith.
Our server system is a monolith that changes very often. Every day, hundreds of programmers make hundreds of commits to code. We continually deploy these changes, doing this every seven minutes. As a result, the project is deployed in production about a hundred times a day. We strive to ensure that less than an hour passes between getting a commit into the master branch and deploying the corresponding code in production (here is a talk about this made at PyCon 2019).
It is very difficult to maintain this huge monolithic code base, making hundreds of commits into it daily, and at the same time not bring it to a state of complete chaos. We want to make Instagram a place where programmers can be productive and able to quickly prepare new useful system features.
This material is about how we use linting and automatic refactoring to make it easier to manage a Python codebase.
If you are interested in trying out some of the ideas mentioned in this material, then you should know that we recently transferred to the category of open source projects LibCST, which underlies many of our internal tools for lining and automatic code refactoring.
Linting: documentation that appears where it is needed
Linting helps programmers find and diagnose problems and antipatterns that developers themselves may not know about without noticing them in the code. This is important for us due to the fact that the relevant ideas regarding the design of the code are the more difficult to distribute, the more programmers work on the project. In our case, we are talking about hundreds of specialists.

Varieties of linting
Linting is just one of many varieties of static code analysis we use on Instagram.
The most primitive way to implement linting rules is to use regular expressions. Regular expressions are easy to write, but Python is not a “regular” language. As a result, it is very difficult (and sometimes impossible) to reliably search for patterns in Python code using regular expressions.
If we talk about the most complex and advanced ways to implement linter, then here are tools like mypy and Pyre. These are two systems for static type checking of Python code that can perform in-depth analysis of programs. Instagram uses Pyre. These are powerful tools, but they are difficult to expand and customize.
When we talk about linting on Instagram, we usually mean working with simple rules based on an abstract syntax tree. It is precisely something like this that underlies our own linting rules for server code.
When Python executes the module, it starts by starting the parser and passing the source code to it. This creates a parse tree – a kind of concrete syntax tree (CST). This tree is a lossless representation of the input source code. Each detail is saved in this tree, such as comments, brackets and commas. Based on CST, you can completely restore the original code.
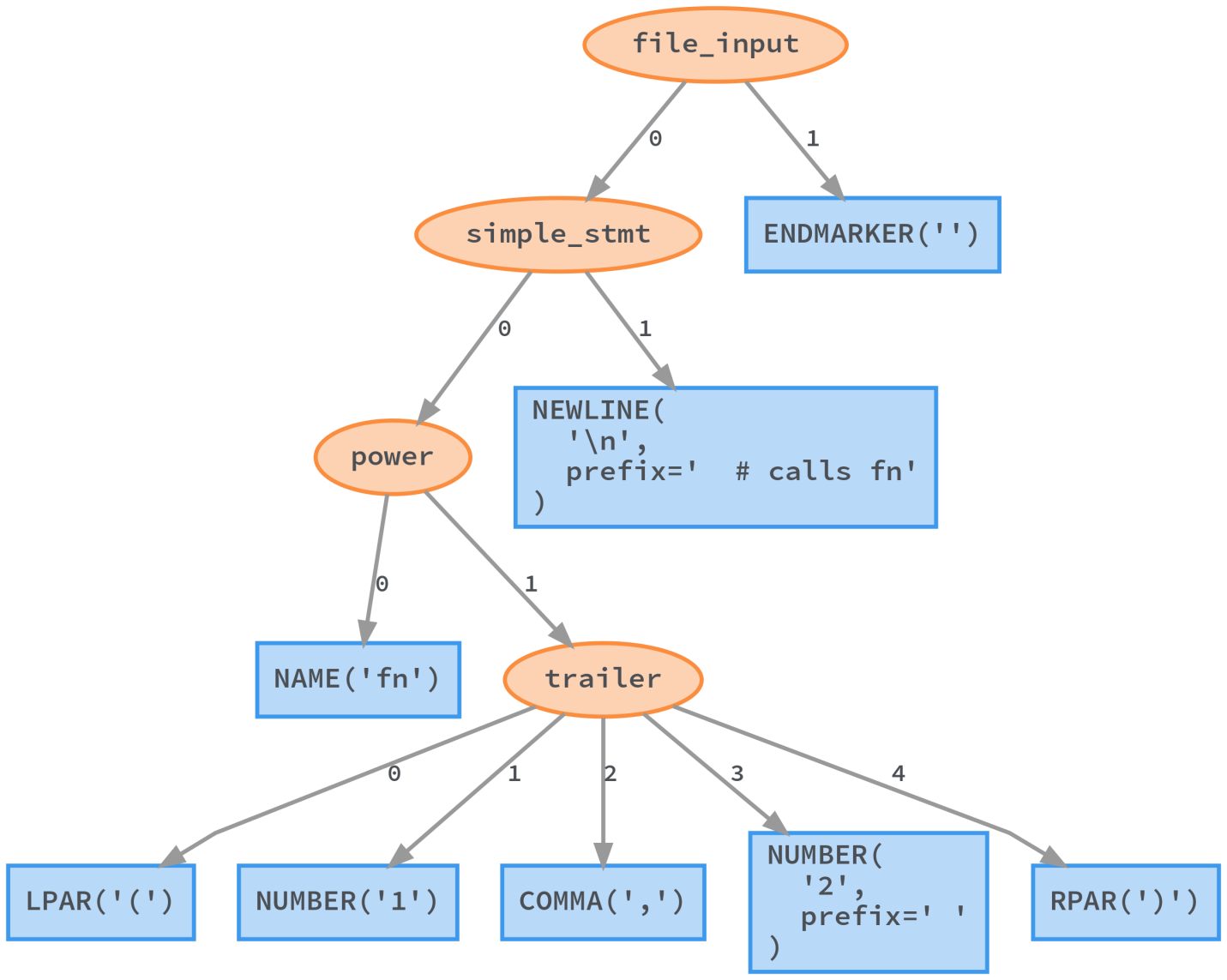
Python Parse Tree (a variation of CST) generated by lib2to3
Unfortunately, such an approach leads to the creation of a complex tree, which makes it difficult to extract semantic information of interest to us from it.
Python compiles the parse tree into an abstract syntax tree (AST). Some information about the source code is lost during this conversion. We are talking about "additional syntactic information" – such as comments, brackets, commas. However, the semantics of the code in the AST are retained.
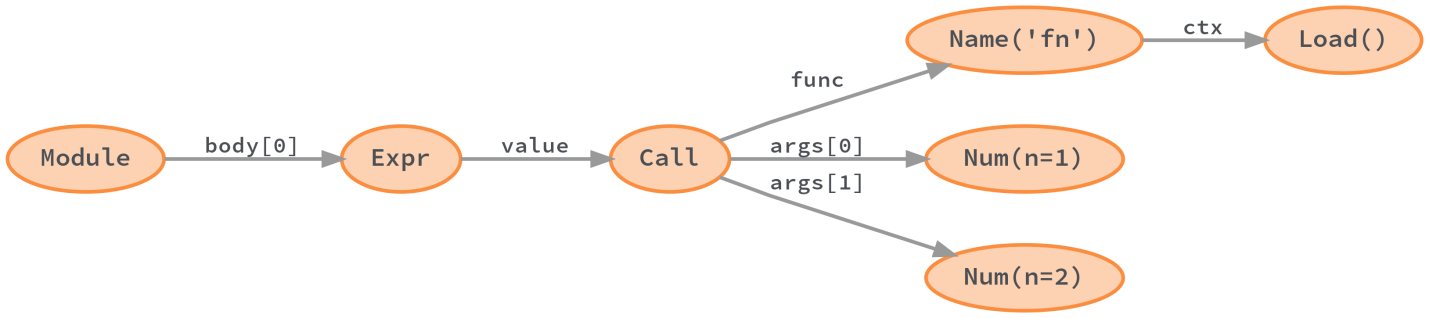
Python abstract syntax tree generated by ast module
We developed LibCST – a library that gives us the best of the worlds of CST and AST. It gives a representation of the code in which all information about it is stored (as in CST), but it is easy to extract semantic information about it from this representation of the code (as when working with AST).
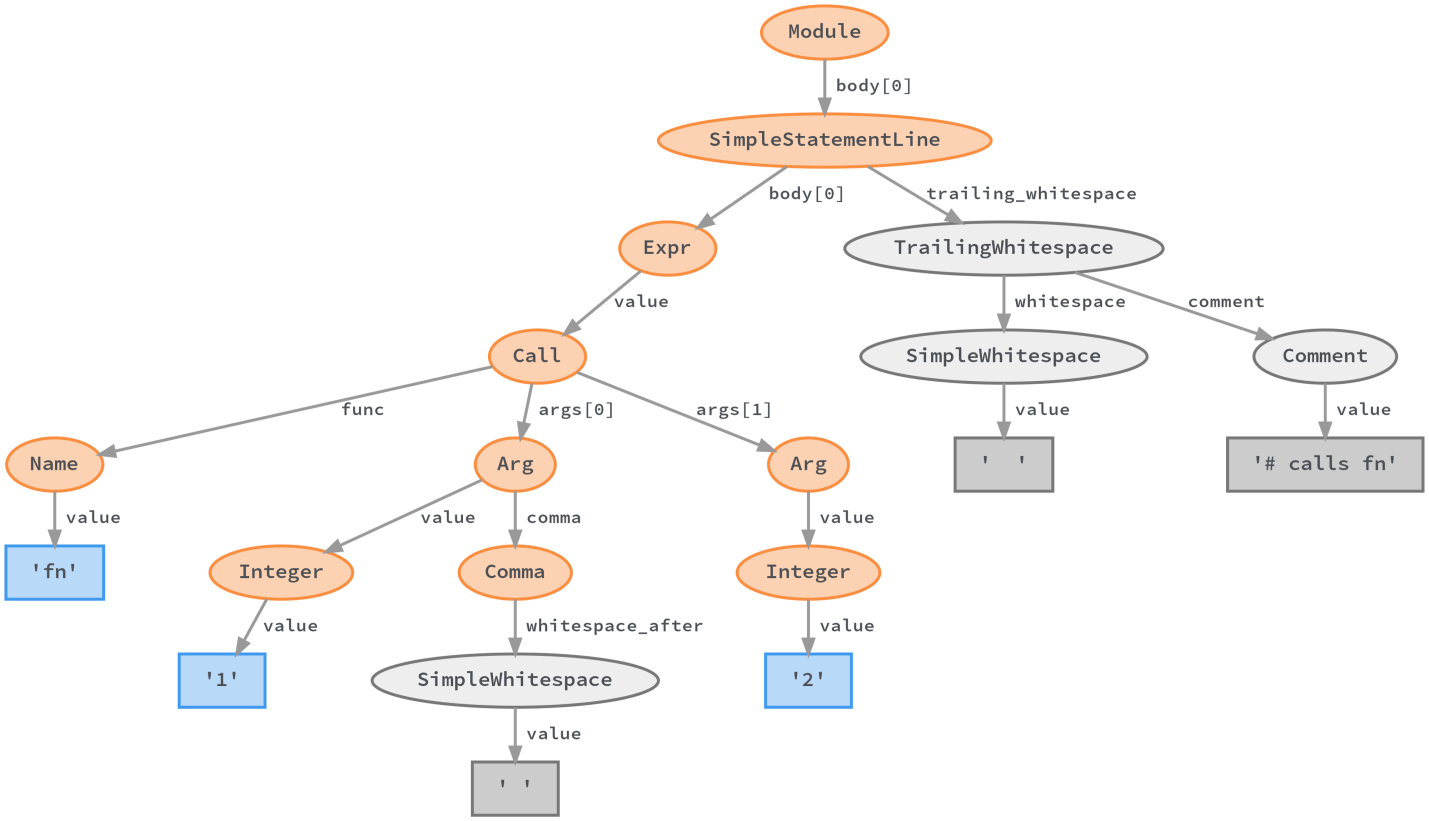
Representation of a specific LibCST syntax tree
Our linting rules use the LibCST syntax tree to find patterns in code. This syntax tree, at a high level, is easy to explore, it allows you to get rid of the problems that accompany the work with the "irregular" language.
Suppose that in a certain module there is a cyclic dependency due to type import. Python solves this problem by putting type import commands in a block if TYPE_CHECKING. This is protection against importing anything during program execution.
# import value commands
from typing import TYPE_CHECKING
from util import helper_fn
# type import commands
if TYPE_CHECKING:
from circular_dependency import CircularTypeLater, someone added another type import and another security block to the code. if. However, the one who did this might not know that such a mechanism already exists in the module.
# import value commands
from typing import TYPE_CHECKING
from util import helper_fn
# type import commands
if TYPE_CHECKING:
from circular_dependency import CircularType
if TYPE_CHECKING: # Duplication of the defense mechanism!
from other_package import OtherTypeYou can get rid of this redundancy using the rule of the linter!
Let's start by initializing the counter of “protective” blocks found in the code.
class OnlyOneTypeCheckingIfBlockLintRule (CstLintRule):
def __init __ (self, context: Context) -> None:
super () .__ init __ (context)
self .__ type_checking_blocks = 0Then, meeting the corresponding condition, we increment the counter, and check that there would be no more than one such block in the code. If this condition is not met, we generate a warning in the appropriate place in the code, causing an auxiliary mechanism used to generate such warnings.
def visit_If (self, node: cst.If) -> None:
if node.test.value == "TYPE_CHECKING":
self .__ type_checking_blocks + = 1
if self .__ type_checking_blocks> 1:
self.context.report (
node
"More than one 'if TYPE_CHECKING' section!"
)Similar linting rules work by looking at the LibCST tree and gathering information. In our linter, this is implemented using the Visitor pattern. As you may have noticed, rules override methods visit and leave methods associated with the type of node. These "visitors" are called in a specific order.
class MyNewLintRule (CstLintRule):
def visit_Assign (self, node):
... # is called first
def visit_Name (self, node):
... # called for each descendant
def leave_Assign (self, name):
... # called after processing all descendants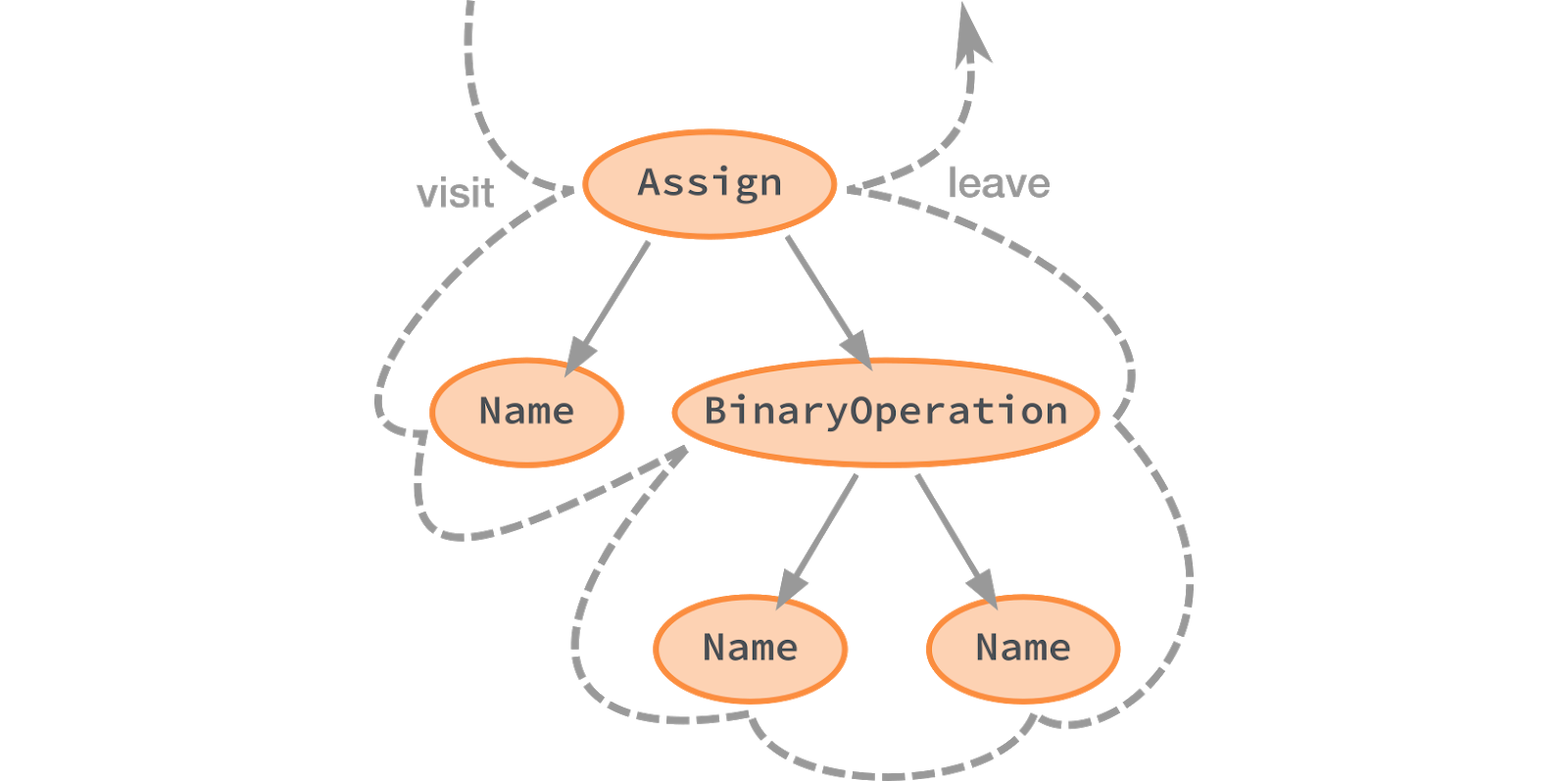
Visit methods are called before visiting descendants of nodes. Leave methods are called after visiting all descendants
We adhere to the principles of work, in accordance with which simple tasks are primarily solved. Our first linter rule of our own was implemented in a single file, contained one “visitor” and used a shared state.
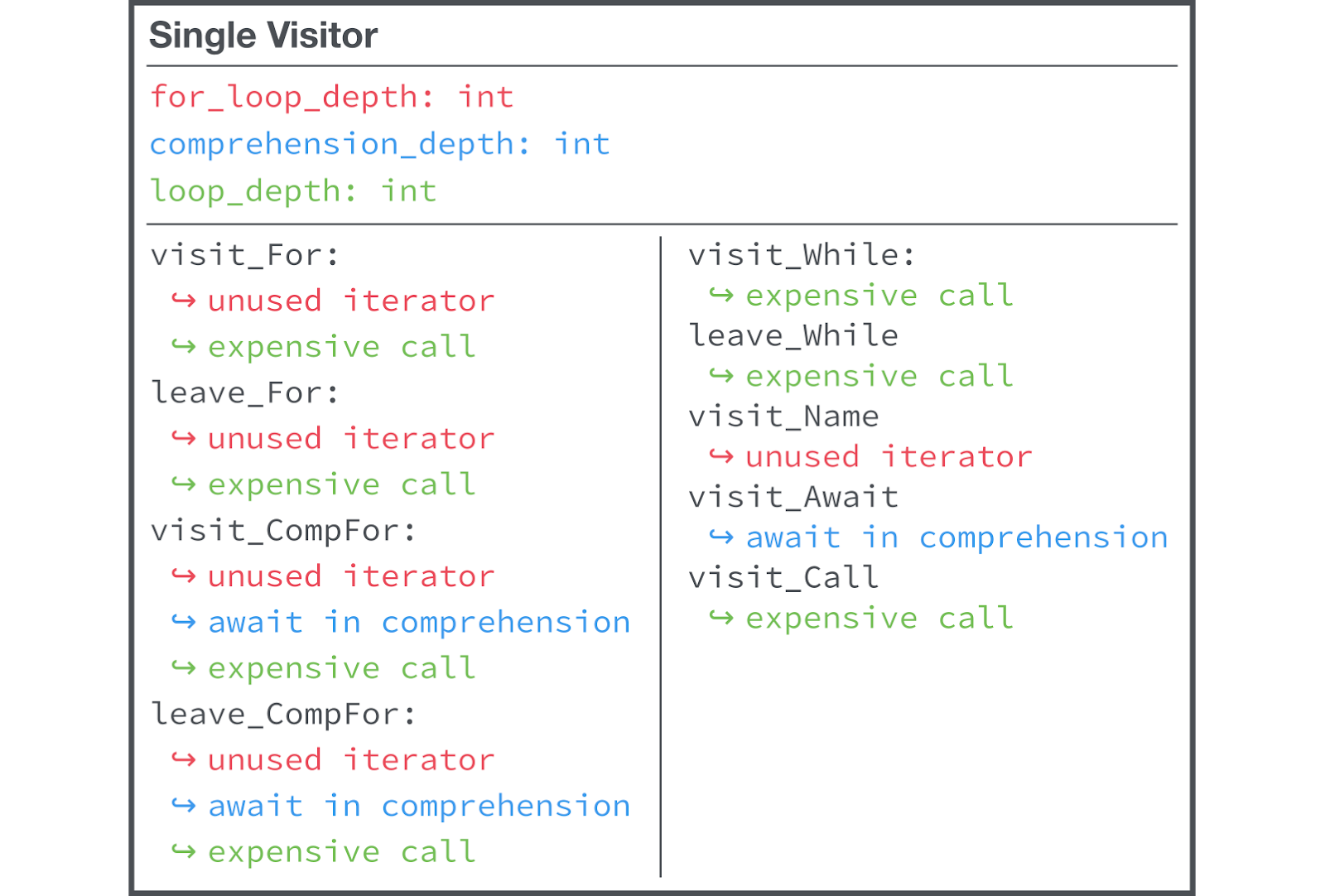
One file, one “visitor”, using shared state
Class Single visitor must have information about the state and the logic of all our linting rules that are not related to it. Moreover, it is not always obvious which state corresponds to a particular rule. This approach shows itself well in a situation where there are literally a few of your own linting rules, but we have about a hundred of these rules, which made it very difficult to support the pattern. single-visitor.

It is difficult to know what state and logic are associated with each of the checks.
Of course, as one of the possible solutions to this problem, we could consider the definition of several “visitors” and the organization of such a work scheme that each of them would look at the whole tree each time. However, this would lead to a serious drop in productivity, and the linter is a program that should work quickly.
Each linter rule can repeatedly traverse a tree. When processing a file, the rules are executed sequentially. However, this approach, which often traverses the tree, would lead to a serious drop in performance.
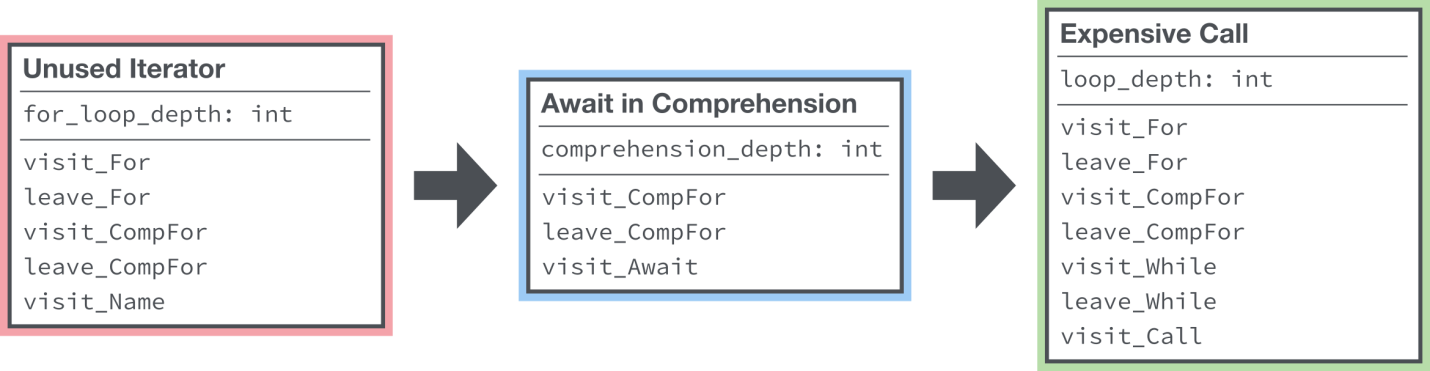
Instead of realizing something like this, we were inspired by the linters used in ecosystems of other programming languages - like ESLint from JavaScript, and created a centralized register of “visitors” (Visitor Registry).

Centralized register of "visitors". We can effectively determine which node is interested in each rule of the linter, saving time on nodes that are not interested in it.
When the linter rule is initialized, all overrides of the rule methods are stored in the registry. When we go around the tree, we look at all the registered “visitors” and call them. If the method is not implemented, it means that you do not need to call it.
This reduces the system’s consumption of computing resources when new linting rules are added to it. We usually check with a linter a small number of recently modified files. But we can check all the rules on the entire Instagram server code base in parallel mode in just 26 seconds.
After we resolved performance issues, we created a testing framework that was aimed at adhering to advanced programming techniques, requiring tests in situations where something should have some quality and in situations where something should not have some quality must.
class MyCustomLintRuleTest (CstLintRuleTest):
RULE = MyCustomLintRule
VALID = [
Valid("good_function('this should not generate a report')"),
Valid("foo.bad_function('nor should this')"),
]
INVALID = [
Invalid("bad_function('but this should')", "IG00"),
]To be continued…
Dear readers! Do you use linters?





