Spam, spam, spam …
Model building
So, we were faced with the task of binary classification.
Indeed, how to distinguish a subscriber (even a very sociable, with a wide range of new contacts) from a spammer who tirelessly imposes the services of another medical center? At first, we considered those numbers that call many different subscribers to be spam, but it turned out to be difficult to distinguish from online stores. Then we decided to take the numbers, whose calls are often dropped, but people sometimes drop calls when they are just not comfortable talking. We also tested the hypothesis that subscribers will not call back to spammers’ numbers (within a short period of time after a missed call), but there were too many such numbers, perhaps for some subscribers this is standard behavior, they do not call back to friends. As a result, we came to the decision that spam numbers differ in the level of user dissatisfaction with them. Therefore as target variable numbers were taken, which received a lot of complaints, and negative examples were marked out of those that have few negative reviews or none at all.
Aggregated data on the subscriber activity of the subscribers were used as signs: the average duration of calls, the periods of the day with the highest activity, the average duration of a break between calls, the speed of updating the circle of contacts, and many others. We also noticed that many spammers select “beautiful numbers” or similar to well-known existing ones (for example, the bank’s hotline number) and add such binary features.
Metric Selection
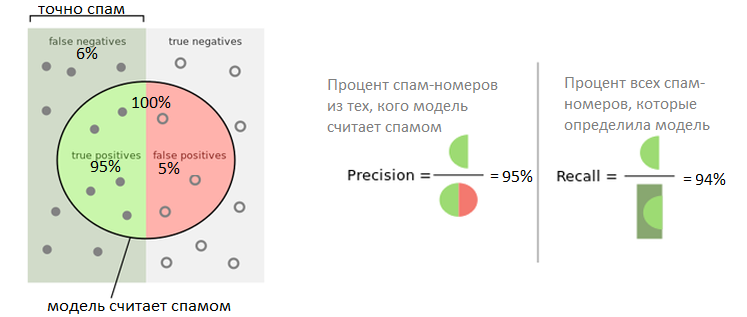
The next step was to choose an optimization metric. In our decision, it was important not to block calls from regular numbers, so we determined that the accuracy of the model should be at least 95%. Precision is the percentage of numbers recognized as objects of a spam class that the model correctly predicted. But it is important to block as many unwanted numbers as possible, so choose the maximum recall (recall) for an acceptable level of accuracy. The final version of the model has the following indicators: 95% precision, recall 94%. Now the model is on the schedule and is regularly retraining to note changes in the call activity of various groups of subscribers, and these metrics are checked so that they do not fall below 90% each.
Due to the fact that spam numbers are much smaller than usual, that is, the sample is unbalanced, the number of negative examples has been reduced relatively positive (undersampling). In the validation sample, the class ratio was chosen real in order to have an idea of the quality of the model’s work “in battle”. Also, only those spam numbers that were active on a certain date due to the inconsistency of spammers were included in the sample: there are periods of active dialing, and there is a period of passivity when they make several calls, most likely to maintain the number. Sometimes the numbers after the campaign are blocked and transferred to another owner.
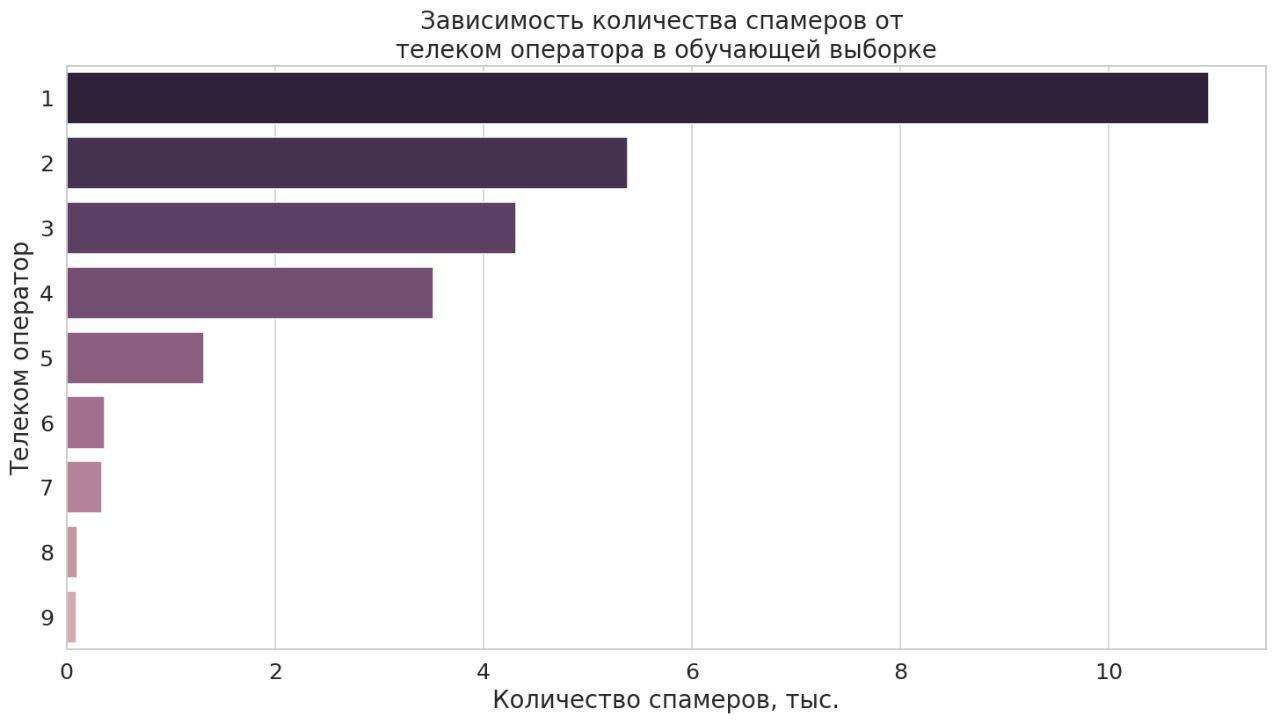
As an algorithm, the implementation of xgboost boosting was used, since it gave the best results on the validation sample. Important signs for the model turned out to be: data on the activity of subscribers at different times of the day, the number of short calls, the breadth of the circle of friends. An interesting fact was that the feature of the telecom operator entered the top features. Below on the chart, we anonymized mobile operators and presented statistics on the use of their numbers by spammers:
Testing
In this task, it was not possible to conduct A / B testing: the service at the network level does not imply the presence of various lists of spam numbers, so we launched the pilot of the first version of the model inside the company, colleagues and top management became testers. One of the positive features of internal testing is quick feedback. We immediately began to pour questions:
- why did this number get through?
- why did you block this number?
- I do not need another car insurance (how much can I ?!)
Our personal experience also became an additional reason to search for new features for the model, when after a long wait for delivery from the online store the courier’s phone was found in the list of blocked ones.
Launch in prod
Another serious problem in the classification of numbers was the difference in ideas about what spam was: for some, calls with a loan offer are unnecessary information, and someone is waiting for personal offers and choosing the best one, so the subscriber was given the opportunity to view the list of callers numbers with the option to disable those that are potentially useful to him.
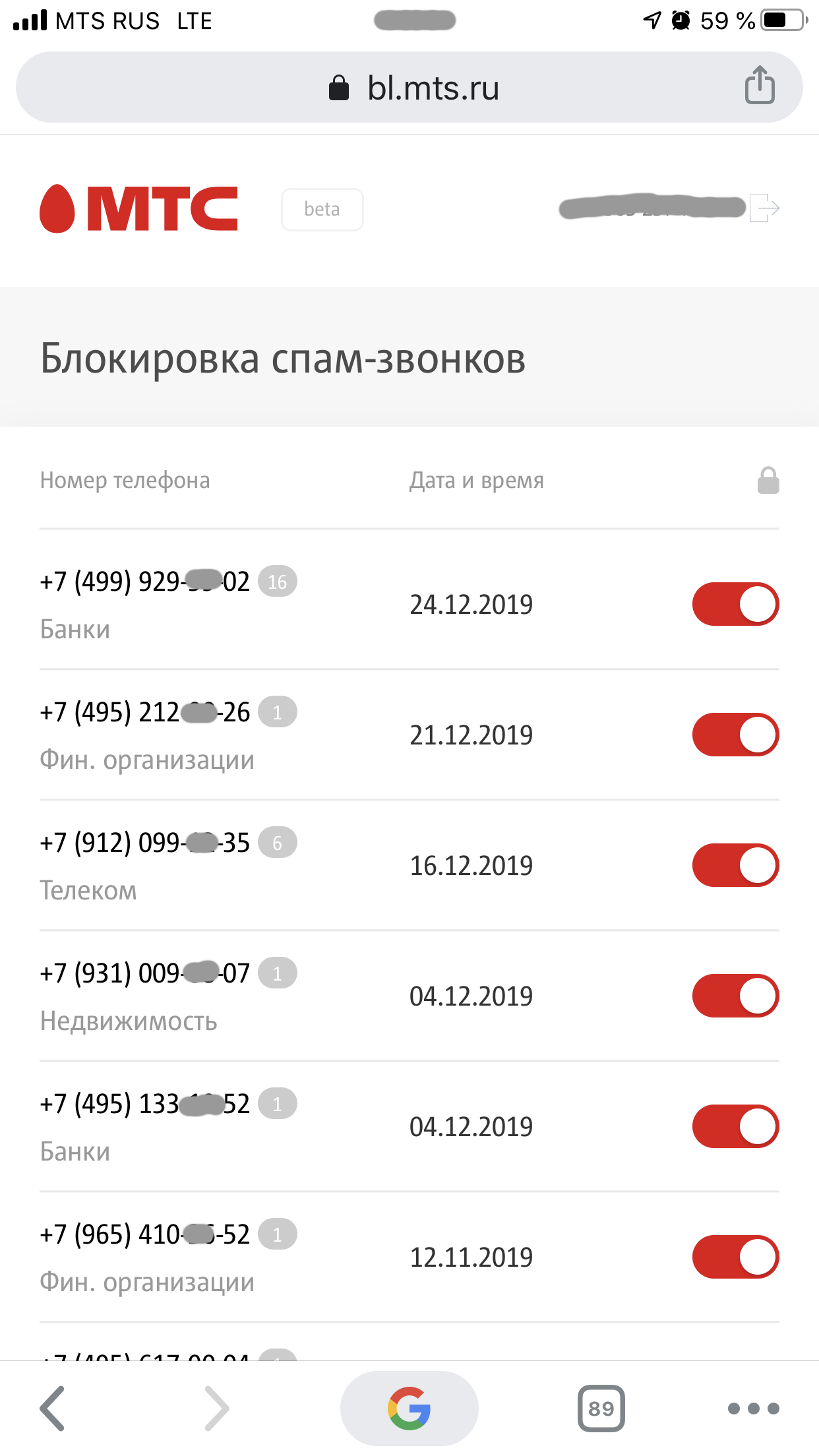
One of the most popular requests from users to finalize the service was to expand the informativeness of the SMS report on daily blocked numbers with data on call categories, for example, banks, medical services or real estate.
The first versions of the model were built on features collected over a long period of time, but we noticed that the model often does not consider numbers that appeared recently to be spam, i.e. new numbers or those that have started active caller calls after a period of “silence”. To solve this problem, we built an additional model on features collected over a shorter period. It was not enough to add “short” features to the training showcase, since the training samples themselves are different: subscribers who are active for a long and short periods of time do not match.
Our further plans for the development of the product include the creation of individual spam lists, taking into account the client’s profile and his needs, the transfer of the model’s work to online mode, so that it catches the peak of spammers’ activity starting here and now.





