Seven patterns of continuous delivery pipelines
Translation of the article was prepared on the eve of the start of the course “DevOps Practices and Tools”.
You have a chance right now catch the course at a special price… Learn more.
Nowadays, business agility is often based on code agility. The ability to quickly and securely release on demand for today’s digital products and services is a real competitive advantage.
Since 2004, we have been developing, assembling and deploying code pipelines for automating applications and infrastructures. In this article, we share seven patterns that improve speed, flexibility, and quality while increasing autonomy, transparency, and serviceability.
Continuous delivery
Continuous delivery (Continuous Delivery) Is “the ability to reliably and quickly deliver changes of all types to users.” Looking at continuous delivery across the Agile vs Effort matrix, you can see that it sits right between continuous integration and continuous deployment. They are often collectively referred to as CI / CD.

IN 2019 DevOps Status Report over 31,000 respondents reported the effectiveness of their development and delivery processes. But the difference between leaders and laggards is staggering. Leaders have 200 times more deployments and 100 times faster deployment times, as well as 2,600 times faster incident recovery and 7 times less likely to rollback releases.
This research shows that for leaders, speed and stability are not the opposite! You can get both (in fact, you need both) to gain real competitive advantage for your digital products and services.
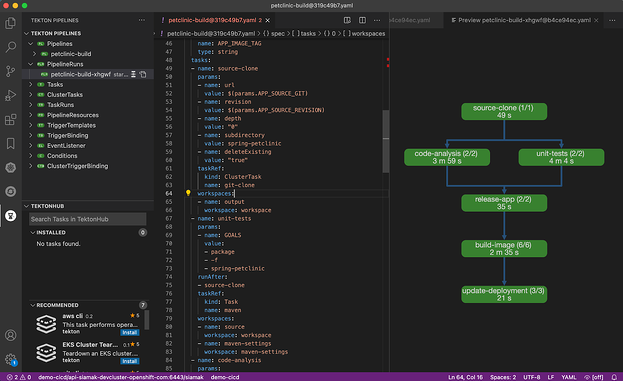
Pipelines
Pipelines (pipelines) are the main technical artifacts of continuous delivery. Modern pipelines transform application and infrastructure source code into versioned packages that can be deployed in any environment. By automating all the routine tasks of assembling and deploying systems, developers can focus on implementing really useful features.
Although code pipelines have been around for almost 20 years – CruiseControl, one of our first favorites, was released in 2001 – they have evolved significantly in recent years.
Based on our experience and that of our clients, we have identified seven pipeline patterns that we have observed in many modern technology companies.
Pipeline patterns
Pattern 1 – pipelines as code
The pipeline logic is coded and stored along with the application and infrastructure code. Containers are used to execute pipelines.

No GUI settings! All pipeline logic is managed like any other application code, and follows the same branching and review strategies.
Running pipelines in containers allows the CI / CD platform to support many different workloads, and each workload can have its own build environment to meet specific requirements.
The build environment container images use verified Docker images.
The configuration of the CI runner is automated, the same and does not require manual configuration. CI runners can scale and standby as needed to minimize latency.
Secrets are stored outside the pipelines, and their output is masked, which increases security.
Pattern 2 – transferring logic to reusable libraries
The general logic of the pipelines is brought into reusable libraries, which can be referenced from the code of the pipelines, as well as independently develop and test them.

Treat pipeline libraries like any other software. They have their own repositories, pipelines, unit tests and releases.
Whenever possible, pipelines use language-specific tools such as Make, Rake, npm, Maven, etc. to run external tasks. In order to simplify the pipeline and keep the local build process and CI identical.
Libraries are easy to find and have good documentation.
Pattern 3 – separate pipelines for build and deployment
Build and deployment pipelines should be logically separate, managed and run independently. It should be possible to start both automatically and manually.

There should be one assembly and many deployments. Concentrate on assembly. As a result, artifacts appear that can be deployed several times.
Be independent from your surroundings. In the absence of environment-specific packages and setting parameters in environment variables, the same assembly can work in any environment.
Pack everything together. Everything – All source code, including the infrastructure code, must be kept together to become a versioned package.
Pattern 4 – launching the right pipeline
Branch commits, pull requests, and mainstream merges can all trigger different pipeline behavior optimized for a specific team.

Opening a pull request creates an ephemeral testing environment.
Upstream merges are deployed to a non-production or demo environment containing the latest integrated code.
Creating new tags results in a release being released.
Pattern 5 – Fast Feedback
Each commit automatically launches a specific pipeline. At the same time, assembly pipelines are specially optimized for speed and quick notification of emerging problems.

Assembly pipelines use parallelization for independent jobs to improve performance.
Fast build pipelines complete the required tasks in minutes.
Each successful run ends with a package version creation and static analysis results.
With the help of multi-channel notifications, you can set up alerts about the status of pool requests on dashboards, in chats, by email, etc.
Pattern 6 – stable internal releases
Only versioned packages generated by the build pipeline are deployed. These deployments are triggered manually or automatically by events.

Each branch of code receives a complete ephemeral environment named after the branch name, which can be easily created or destroyed.
Any engineer can create or remove an ephemeral environment.
CI runners leverage cloud-native IAM capabilities with temporary permissions to obtain the necessary roles and permissions to do their job.
Pattern 7 – release history
Deploy tagged releases to production, automate reporting, and maintain a history of deployments.

A “release gate” in code form and standardized release processes allow for on-demand releases.
Automated releases leave a story that can be analyzed further.
The release gate can call external APIs and use the response to decide whether to continue the release or stop it.
Problems
We increasingly come across these seven pipeline patterns and use them when working with clients. But while they represent a huge leap forward in terms of speed and stability, they are not without drawbacks.
Security is the biggest issue we see. It relates to the complexity of automating processes that have traditionally been human-centered. Pipeline complexity, team acceptance, culture change, and database automation are other major issues that need to be addressed. But this is all solvable, and we work on it every day.
Outcome
Business agility is based on code flexibility. For modern digital products and services, the ability to quickly and securely release on demand is a real competitive advantage for businesses. Code pipelines, and in particular the seven patterns described, can help your organization take giant leaps forward in release speed and stability, and keep your teams at the leadership level.
Read more:
Five Best Practices for Prometheus Exporters to Improve Productivity