Right [c]read parallel PostgreSQL plans
Therefore, inside each separate process there are no traditional “strange” problems with parallel code execution, locks, race condition,… And the development of the DBMS itself is pleasant and simple.
But the same simplicity imposes a significant limitation. Since there is only one worker thread inside the process, then it can use no more than one CPU core to fulfill a request – and, therefore, the server speed directly depends on the frequency and architecture of a separate core.
In our age of the end of the “race of megahertz” and the victorious multicore and multiprocessor systems, such behavior is an unacceptable luxury and wastefulness. Therefore, starting with PostgreSQL 9.6, when processing a query some operations can be performed by several processes at the same time.
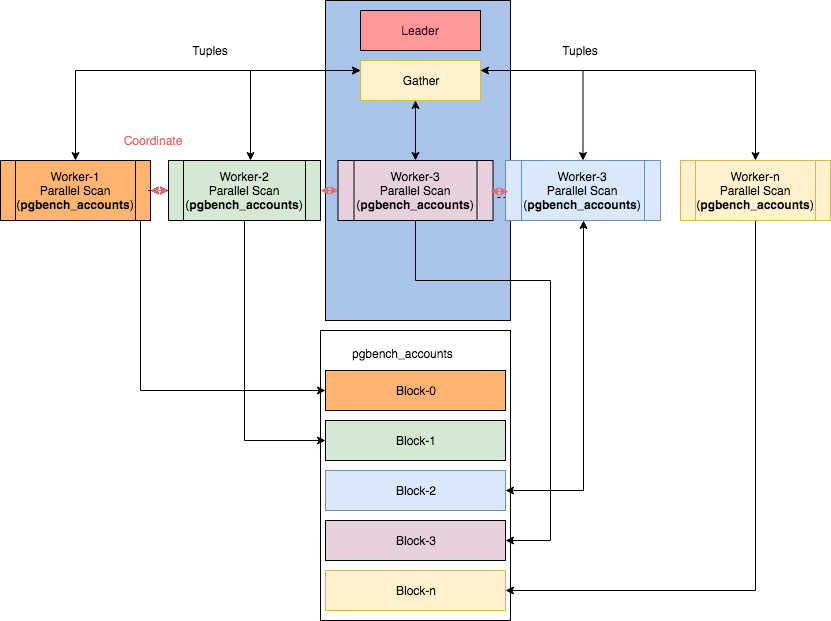
You can familiarize yourself with the schemes of operation of some parallel nodes in the article Parallelism in PostgreSQL by Ibrar Ahmed, where this image came from.
However, in this case it becomes … nontrivial to read the plans.
Briefly, the chronology of the implementation of parallel execution of plan operations looks like this:
- 9.6 – basic functionality: Seq scan, Join, Aggregate
- ten – Index Scan (for btree), Bitmap Heap Scan, Hash Join, Merge Join, Subquery Scan
- eleven – group operations: Hash Join with shared hash table, Append (UNION)
- 12 – basic per-worker statistics on plan nodes
- 13 – detailed per-worker statistics
Therefore, if you are using one of the latest PostgreSQL versions, the chances of seeing in the plan Parallel ... are very large. And with him they come and …
Oddities over time
Let’s take a plan from PostgreSQL 9.6:
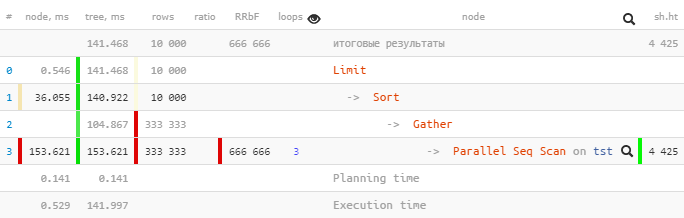
[посмотреть на explain.tensor.ru]
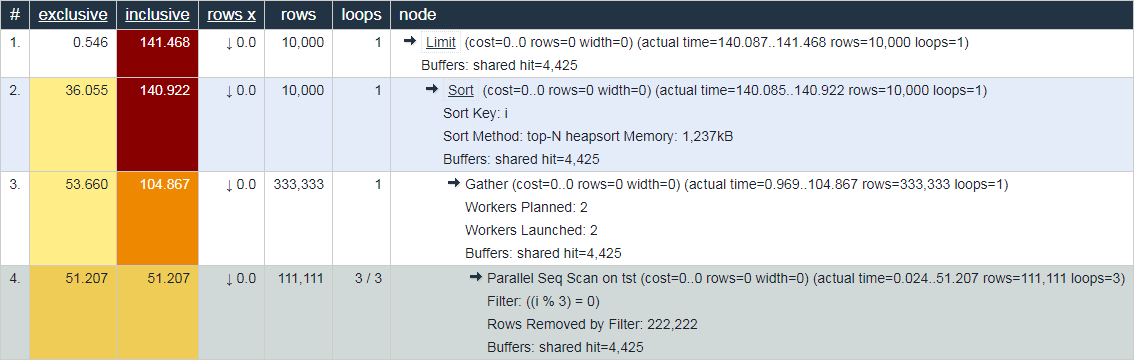
Only one Parallel Seq Scan carried out 153.621ms inside a subtree, and Gather together with all sub-assemblies – total 104.867ms.
How so? Has the total time “upstairs” become less? ..
Let’s take a closer look at Gather-node:
Gather (actual time=0.969..104.867 rows=333333 loops=1)
Workers Planned: 2
Workers Launched: 2
Buffers: shared hit=4425Workers Launched: 2 tells us that in addition to the main process below the tree, 2 more additional ones were involved – for a total of 3. Therefore, everything that happened inside Gather-subtree is the total creativity of all 3 processes at once.
Now let’s see what’s in there Parallel Seq Scan:
Parallel Seq Scan on tst (actual time=0.024..51.207 rows=111111 loops=3)
Filter: ((i % 3) = 0)
Rows Removed by Filter: 222222
Buffers: shared hit=4425Aha! loops=3 Is a summary of all 3 processes. And, on average, each such cycle took 51.207ms. That is, in total, to process this node, the server needed 51.207 x 3 = 153.621 milliseconds CPU time… That is, if we want to understand “what the server was doing” – it is this number that will help us understand.
Note that for understanding “Real” time execution time must be divided by the number of workers – that is
[actual time] x [loops] / [Workers Launched]…
In our example, each worker performed only one cycle through the node, so 153.621 / 3 = 51.207… And yes, now there is nothing strange that the only Gather in the head process was carried out in “as if less time”.
Total: look at explain.tensor.ru total (for all processes) node timeto understand what kind of load your server was busy with, and optimizing which part of the request is worth spending time.
In this sense, the behavior of the same explain.depesz.comshowing the “real average” time at once looks less useful for debugging purposes:
Do not agree? Welcome to comments!
Gather Merge loses everything
Now let’s execute the same query on PostgreSQL versions ten:
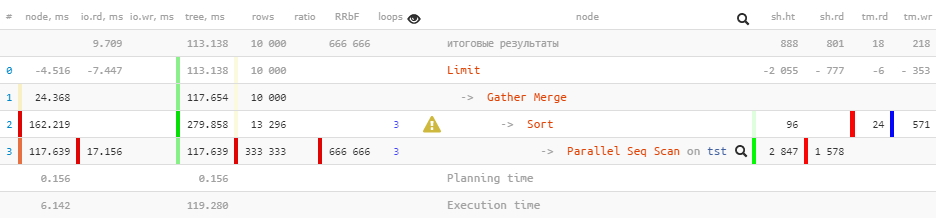
[посмотреть на explain.tensor.ru]
Note that in the plan, instead of a node Gather now turned out to be Gather Merge, and the sequential reading of the table has become ordered, by index, albeit parallel. Here’s what he says about this manual:
When a node is above the parallel part of the plan
Gather Merge, but notGather, this means that all processes that execute parts of the parallel plan produce tuples in sorted order, and that the master process does an order-preserving merge. The knotGatheron the contrary, it receives tuples from subordinate processes in an arbitrary order that is convenient for it, violating the sort order that might exist.
But not all is well in the Danish kingdom:
Limit (actual time=110.740..113.138 rows=10000 loops=1)
Buffers: shared hit=888 read=801, temp read=18 written=218
I/O Timings: read=9.709
-> Gather Merge (actual time=110.739..117.654 rows=10000 loops=1)
Workers Planned: 2
Workers Launched: 2
Buffers: shared hit=2943 read=1578, temp read=24 written=571
I/O Timings: read=17.156When passing attributes Buffers and I/O Timings up the tree part of the data was untimely lost… We can estimate the size of this loss as just about 2/3that are formed by auxiliary processes.
Alas, in the plan itself, there is nowhere to get this information – hence the “disadvantages” on the overlying node. And if you look at the further evolution of this plan in PostgreSQL 12, then it does not fundamentally change, except that some statistics are added for each worker by Sort-node:
Limit (actual time=77.063..80.480 rows=10000 loops=1)
Buffers: shared hit=1764, temp read=223 written=355
-> Gather Merge (actual time=77.060..81.892 rows=10000 loops=1)
Workers Planned: 2
Workers Launched: 2
Buffers: shared hit=4519, temp read=575 written=856
-> Sort (actual time=72.630..73.252 rows=4278 loops=3)
Sort Key: i
Sort Method: external merge Disk: 1832kB
Worker 0: Sort Method: external merge Disk: 1512kB
Worker 1: Sort Method: external merge Disk: 1248kB
Buffers: shared hit=4519, temp read=575 written=856
-> Parallel Seq Scan on tst (actual time=0.014..44.970 rows=111111 loops=3)
Filter: ((i % 3) = 0)
Rows Removed by Filter: 222222
Buffers: shared hit=4425
Planning Time: 0.142 ms
Execution Time: 83.884 msTotal: don’t trust the node data over Gather Merge…





